 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Data Imbalance Under a Federated Learning Approach for Credit Risk Forecasting
Jan 14, 2024Credit risk forecasting plays a crucial role for commercial banks and other financial institutions in granting loans to customers and minimise the potential loss. However, traditional machine learning methods require the sharing of sensitive client information with an external server to build a global model, potentially posing a risk of security threats and privacy leakage. A newly developed privacy-preserving distributed machine learning technique known as Federated Learning (FL) allows the training of a global model without the necessity of accessing private local data directly. This investigation examined the feasibility of federated learning in credit risk assessment and showed the effects of data imbalance on model performance. Two neural network architectures, Multilayer Perceptron (MLP) and Long Short-Term Memory (LSTM), and one tree ensemble architecture, Extreme Gradient Boosting (XGBoost), were explored across three different datasets under various scenarios involving different numbers of clients and data distribution configurations. We demonstrate that federated models consistently outperform local models on non-dominant clients with smaller datasets. This trend is especially pronounced in highly imbalanced data scenarios, yielding a remarkable average improvement of 17.92% in model performance. However, for dominant clients (clients with more data), federated models may not exhibit superior performance, suggesting the need for special incentives for this type of clients to encourage their participation.
Joint Study of Above Ground Biomass and Soil Organic Carbon for Total Carbon Estimation using Satellite Imagery in Scotland
May 08, 2022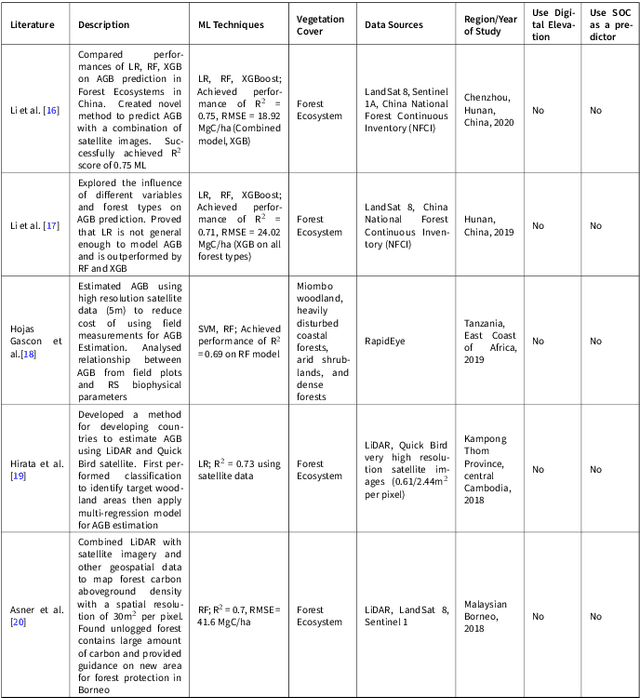
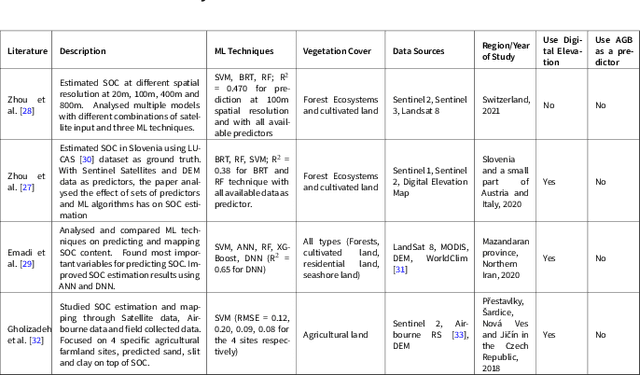
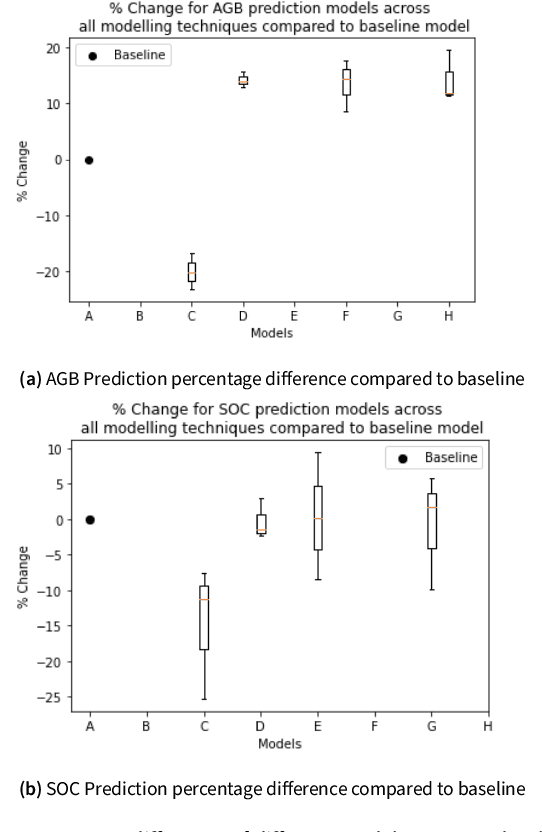
Land Carbon verification has long been a challenge in the carbon credit market. Carbon verification methods currently available are expensive, and may generate low-quality credit. Scalable and accurate remote sensing techniques enable new approaches to monitor changes in Above Ground Biomass (AGB) and Soil Organic Carbon (SOC). The majority of state-of-the-art research employs remote sensing on AGB and SOC separately, although some studies indicate a positive correlation between the two. We intend to combine the two domains in our research to improve state-of-the-art total carbon estimation and to provide insight into the voluntary carbon trading market. We begin by establishing baseline model in our study area in Scotland, using state-of-the-art methodologies in the SOC and AGB domains. The effects of feature engineering techniques such as variance inflation factor and feature selection on machine learning models are then investigated. This is extended by combining predictor variables from the two domains. Finally, we leverage the possible correlation between AGB and SOC to establish a relationship between the two and propose novel models in an attempt outperform the state-of-the-art results. We compared three machine learning techniques, boosted regression tree, random forest, and xgboost. These techniques have been demonstrated to be the most effective in both domains.