 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovement of a Prediction Model for Heart Failure Survival through Explainable Artificial Intelligence
Aug 20, 2021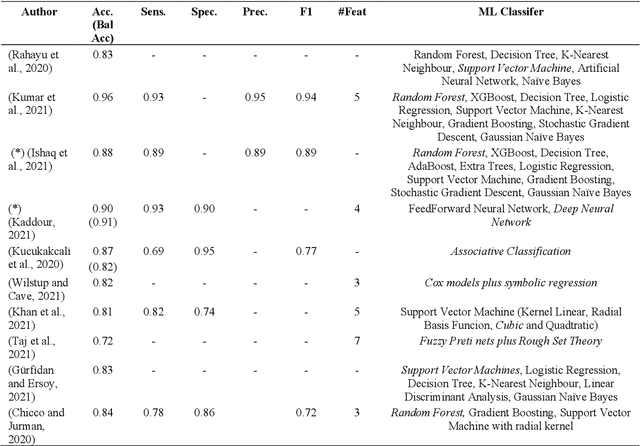
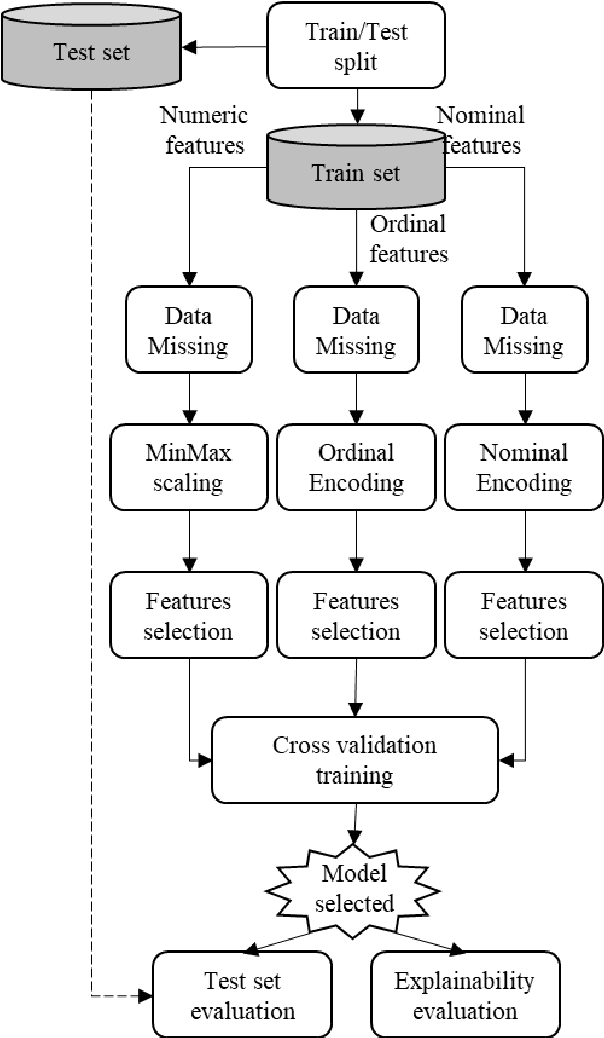
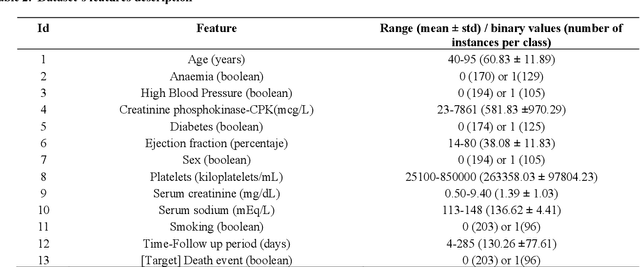
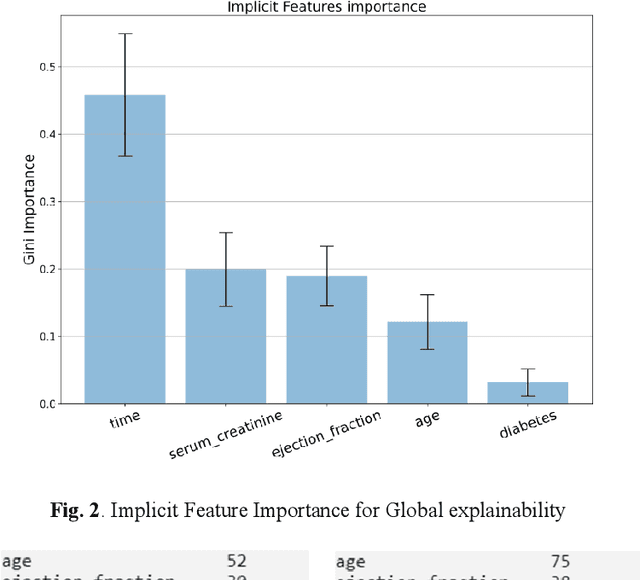
Cardiovascular diseases and their associated disorder of heart failure are one of the major death causes globally, being a priority for doctors to detect and predict its onset and medical consequences. Artificial Intelligence (AI) allows doctors to discover clinical indicators and enhance their diagnosis and treatments. Specifically, explainable AI offers tools to improve the clinical prediction models that experience poor interpretability of their results. This work presents an explainability analysis and evaluation of a prediction model for heart failure survival by using a dataset that comprises 299 patients who suffered heart failure. The model employs a data workflow pipeline able to select the best ensemble tree algorithm as well as the best feature selection technique. Moreover, different post-hoc techniques have been used for the explainability analysis of the model. The paper's main contribution is an explainability-driven approach to select the best prediction model for HF survival based on an accuracy-explainability balance. Therefore, the most balanced explainable prediction model implements an Extra Trees classifier over 5 selected features (follow-up time, serum creatinine, ejection fraction, age and diabetes) out of 12, achieving a balanced-accuracy of 85.1% and 79.5% with cross-validation and new unseen data respectively. The follow-up time is the most influencing feature followed by serum-creatinine and ejection-fraction. The explainable prediction model for HF survival presented in this paper would improve a further adoption of clinical prediction models by providing doctors with intuitions to better understand the reasoning of, usually, black-box AI clinical solutions, and make more reasonable and data-driven decisions.
An Explainable Classification Model for Chronic Kidney Disease Patients
May 21, 2021



Currently, Chronic Kidney Disease (CKD) is experiencing a globally increasing incidence and high cost to health systems. A delayed recognition leads to premature mortality due to progressive loss of kidney function. The employment of data mining to discover subtle patterns in CKD indicators would contribute to an early diagnosis. This work develops a classifier model that would support healthcare professionals in the early diagnosis of CKD patients. Through a data pipeline, an exhaustive search is performed to find the best data mining classifier with different parameters of the data preparation's sub-stages like data missing or feature selection. Therefore, Extra Trees is selected as the best classifier with a 100% and 99% of accuracy with, respectively, cross-validation technique and with new unseen data. Moreover, the 8 features selected are employed to assess the explainability of the model's results denoting which features are more relevant in the model's output.