 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPlatt: Simple Calibration Framework for Ranking Models
Jan 13, 2026Ranking models are extensively used in e-commerce for relevance estimation. These models often suffer from poor interpretability and no scale calibration, particularly when trained with typical ranking loss functions. This paper addresses the problem of post-hoc calibration of ranking models. We introduce MLPlatt: a simple yet effective ranking model calibration method that preserves the item ordering and converts ranker outputs to interpretable click-through rate (CTR) probabilities usable in downstream tasks. The method is context-aware by design and achieves good calibration metrics globally, and within strata corresponding to different values of a selected categorical field (such as user country or device), which is often important from a business perspective of an E-commerce platform. We demonstrate the superiority of MLPlatt over existing approaches on two datasets, achieving an improvement of over 10\% in F-ECE (Field Expected Calibration Error) compared to other methods. Most importantly, we show that high-quality calibration can be achieved without compromising the ranking quality.
Metric Learning for Session-based Recommendations
Jan 07, 2021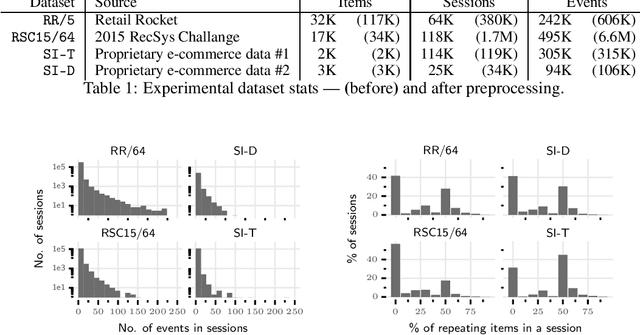
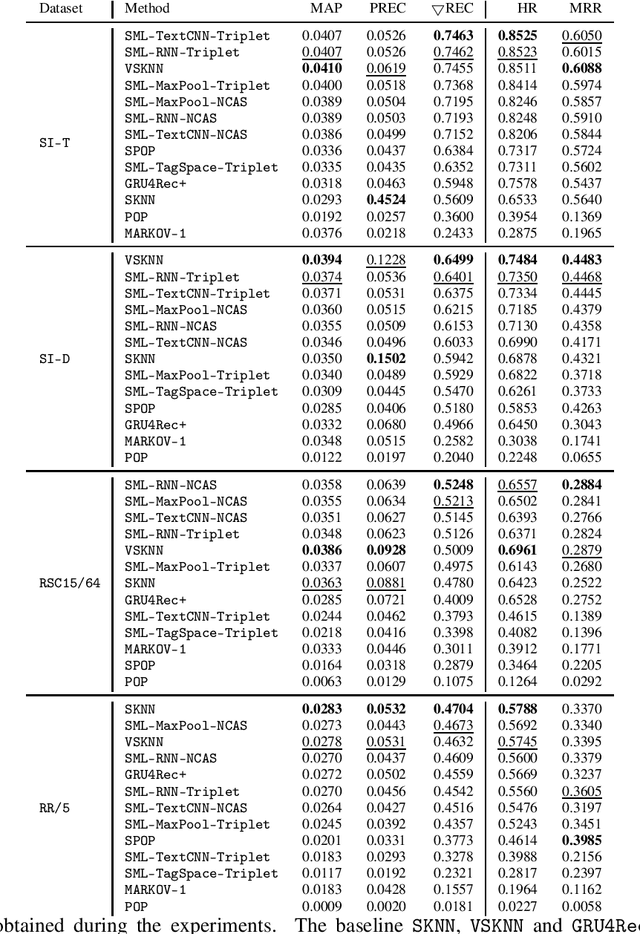
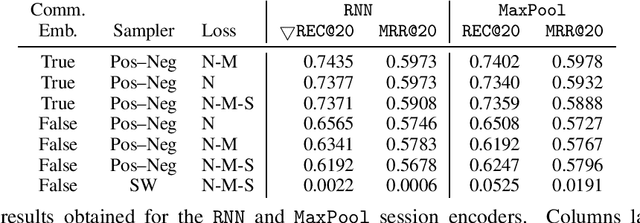
Session-based recommenders, used for making predictions out of users' uninterrupted sequences of actions, are attractive for many applications. Here, for this task we propose using metric learning, where a common embedding space for sessions and items is created, and distance measures dissimilarity between the provided sequence of users' events and the next action. We discuss and compare metric learning approaches to commonly used learning-to-rank methods, where some synergies exist. We propose a simple architecture for problem analysis and demonstrate that neither extensively big nor deep architectures are necessary in order to outperform existing methods. The experimental results against strong baselines on four datasets are provided with an ablation study.