 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Task Vector is not Enough: A Large-Scale Study for In-Context Learning
May 29, 2025In-context learning (ICL) enables Large Language Models (LLMs) to adapt to new tasks using few examples, with task vectors - specific hidden state activations - hypothesized to encode task information. Existing studies are limited by small-scale benchmarks, restricting comprehensive analysis. We introduce QuiteAFew, a novel dataset of 3,096 diverse few-shot tasks, each with 30 input-output pairs derived from the Alpaca dataset. Experiments with Llama-3-8B on QuiteAFew reveal: (1) task vector performance peaks at an intermediate layer (e.g., 15th), (2) effectiveness varies significantly by task type, and (3) complex tasks rely on multiple, subtask-specific vectors rather than a single vector, suggesting distributed task knowledge representation.
WikiMulti: a Corpus for Cross-Lingual Summarization
Apr 23, 2022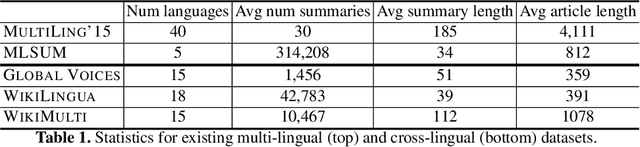


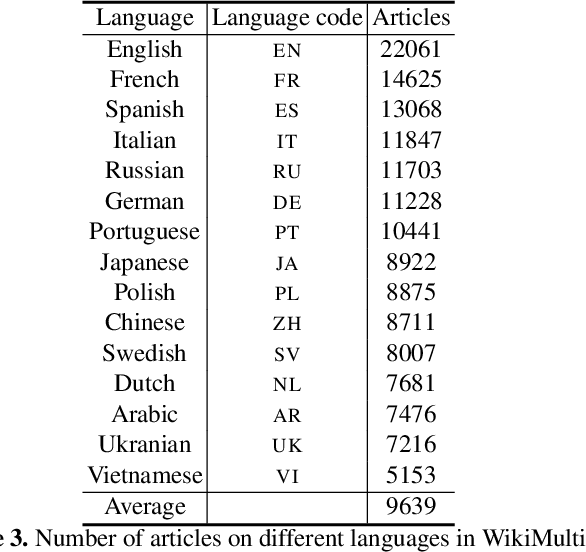
Cross-lingual summarization (CLS) is the task to produce a summary in one particular language for a source document in a different language. We introduce WikiMulti - a new dataset for cross-lingual summarization based on Wikipedia articles in 15 languages. As a set of baselines for further studies, we evaluate the performance of existing cross-lingual abstractive summarization methods on our dataset. We make our dataset publicly available here: https://github.com/tikhonovpavel/wikimulti