 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation plane and compression-gnostic feedback in quantum machine learning
Nov 04, 2024



The information plane (Tishby et al. arXiv:physics/0004057, Shwartz-Ziv et al. arXiv:1703.00810) has been proposed as an analytical tool for studying the learning dynamics of neural networks. It provides quantitative insight on how the model approaches the learned state by approximating a minimal sufficient statistics. In this paper we extend this tool to the domain of quantum learning models. In a second step, we study how the insight on how much the model compresses the input data (provided by the information plane) can be used to improve a learning algorithm. Specifically, we consider two ways to do so: via a multiplicative regularization of the loss function, or with a compression-gnostic scheduler of the learning rate (for algorithms based on gradient descent). Both ways turn out to be equivalent in our implementation. Finally, we benchmark the proposed learning algorithms on several classification and regression tasks using variational quantum circuits. The results demonstrate an improvement in test accuracy and convergence speed for both synthetic and real-world datasets. Additionally, with one example we analyzed the impact of the proposed modifications on the performances of neural networks in a classification task.
An exponentially-growing family of universal quantum circuits
Dec 01, 2022Quantum machine learning has become an area of growing interest but has certain theoretical and hardware-specific limitations. Notably, the problem of vanishing gradients, or barren plateaus, renders the training impossible for circuits with high qubit counts, imposing a limit on the number of qubits that data scientists can use for solving problems. Independently, angle-embedded supervised quantum neural networks were shown to produce truncated Fourier series with a degree directly dependent on two factors: the depth of the encoding, and the number of parallel qubits the encoding is applied to. The degree of the Fourier series limits the model expressivity. This work introduces two new architectures whose Fourier degrees grow exponentially: the sequential and parallel exponential quantum machine learning architectures. This is done by efficiently using the available Hilbert space when encoding, increasing the expressivity of the quantum encoding. Therefore, the exponential growth allows staying at the low-qubit limit to create highly expressive circuits avoiding barren plateaus. Practically, parallel exponential architecture was shown to outperform the existing linear architectures by reducing their final mean square error value by up to 44.7% in a one-dimensional test problem. Furthermore, the feasibility of this technique was also shown on a trapped ion quantum processing unit.
Control of Stochastic Quantum Dynamics with Differentiable Programming
Jan 04, 2021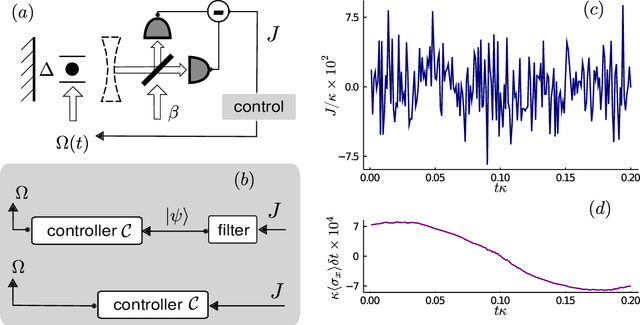
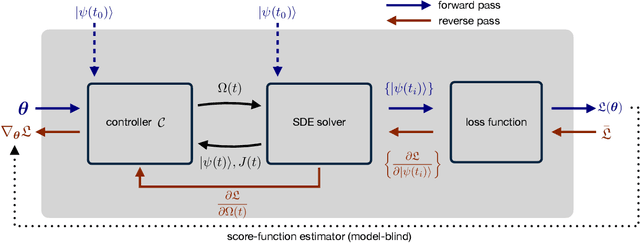
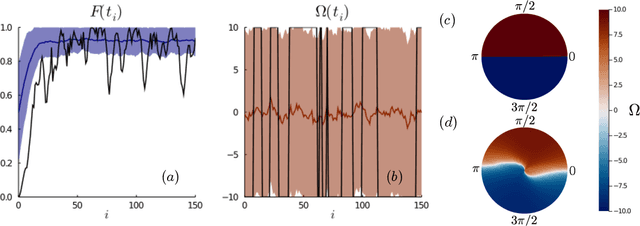
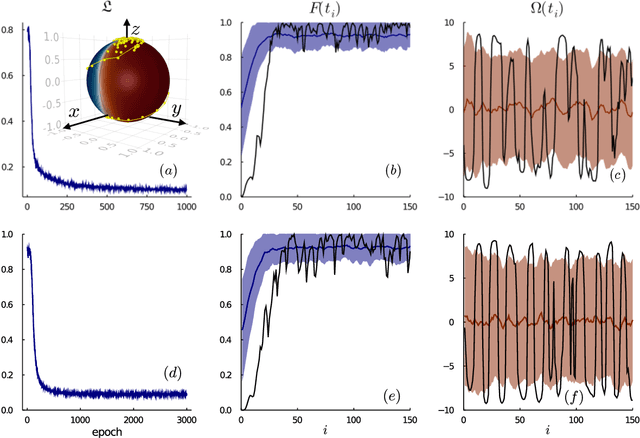
Controlling stochastic dynamics of a quantum system is an indispensable task in fields such as quantum information processing and metrology. Yet, there is no general ready-made approach to design efficient control strategies. Here, we propose a framework for the automated design of control schemes based on differentiable programming ($\partial \mathrm{P}$). We apply this approach to state preparation and stabilization of a qubit subjected to homodyne detection. To this end, we formulate the control task as an optimization problem where the loss function quantifies the distance from the target state and we employ neural networks (NNs) as controllers. The system's time evolution is governed by a stochastic differential equation (SDE). To implement efficient training, we backpropagate the gradient information from the loss function through the SDE solver using adjoint sensitivity methods. As a first example, we feed the quantum state to the controller and focus on different methods to obtain gradients. As a second example, we directly feed the homodyne detection signal to the controller. The instantaneous value of the homodyne current contains only very limited information on the actual state of the system, covered in unavoidable photon-number fluctuations. Despite the resulting poor signal-to-noise ratio, we can train our controller to prepare and stabilize the qubit to a target state with a mean fidelity around 85%. We also compare the solutions found by the NN to a hand-crafted control strategy.
Setting up experimental Bell test with reinforcement learning
May 04, 2020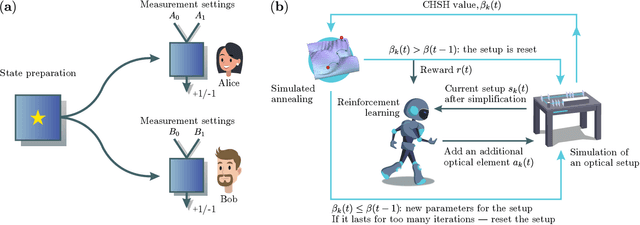
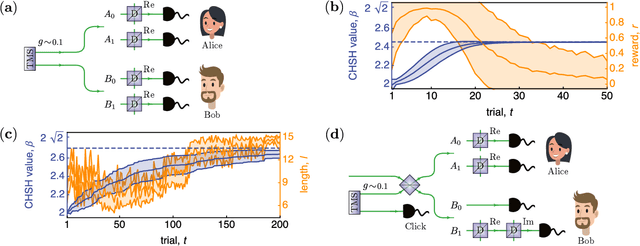
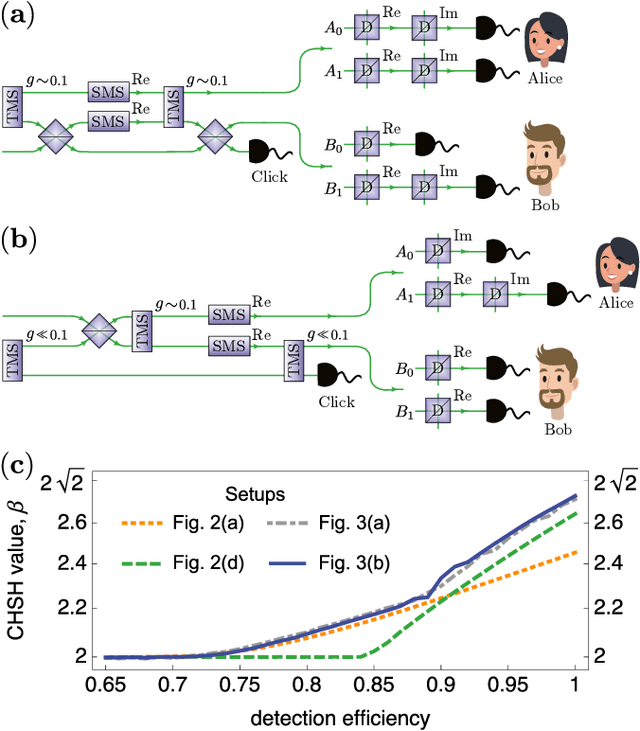
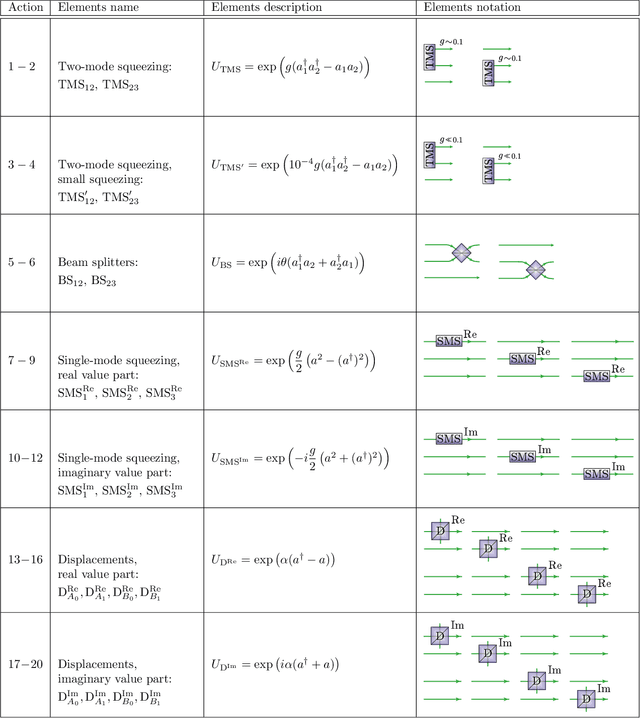
Finding optical setups producing measurement results with a targeted probability distribution is hard as a priori the number of possible experimental implementations grows exponentially with the number of modes and the number of devices. To tackle this complexity, we introduce a method combining reinforcement learning and simulated annealing enabling the automated design of optical experiments producing results with the desired probability distributions. We illustrate the relevance of our method by applying it to a probability distribution favouring high violations of the Bell-CHSH inequality. As a result, we propose new unintuitive experiments leading to higher Bell-CHSH inequality violations than the best currently known setups. Our method might positively impact the usefulness of photonic experiments for device-independent quantum information processing.