 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgreement in Representation Space for Open-Ended Self-Consistency
Jun 10, 2026Self-consistency improves LLM reasoning by sampling multiple outputs and selecting the most consistent answer, but existing formulations largely rely on exact matching and therefore remain limited to tasks with categorical outputs. In this work, we study self-consistency in open-ended generation tasks such as code synthesis and text summarization. We hypothesize that consistency can be understood as a geometric property of the generation space, where semantically compatible generations concentrate in similar regions of representation space. To study this hypothesis, we introduce Embedding-Based Agreement (EBA), a simple training-free operationalization that estimates agreement by clustering sampled generations in embedding space. Through experiments on mathematical reasoning, code generation, and summarization, we show that agreement in representation space provides a robust and scalable signal of self-consistency for open-ended tasks. In particular, EBA consistently outperforms random selection and exhibits more stable scaling behavior than recent selection approaches based on LLM evaluation or uncertainty estimation. We further show that these agreement signals remain stable across model families and embedding spaces, even with native hidden representations. Finally, our analysis shows that the geometric location occupied by sampled generations is strongly correlated with generation quality: generations concentrated near central regions of representation space tend to correspond to more reliable outputs, whereas peripheral generations are substantially less accurate. Overall, our findings support viewing self-consistency as a property of the geometric organization of sampled generations rather than exact symbolic overlap.
Multimodal LLMs Do Not Compose Skills Optimally Across Modalities
Nov 12, 2025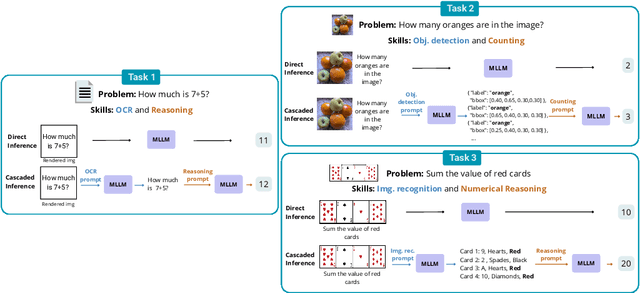
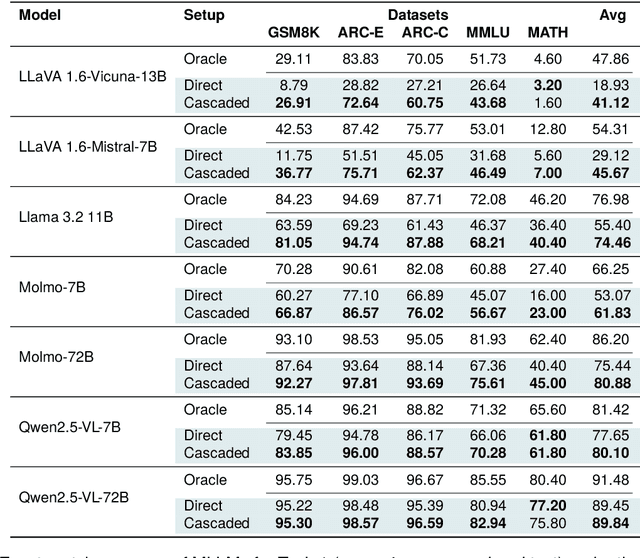
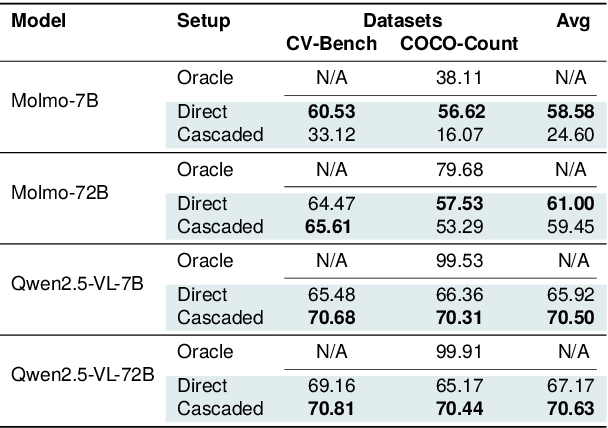

Skill composition is the ability to combine previously learned skills to solve new tasks. As neural networks acquire increasingly complex skills during their pretraining, it is not clear how successfully they can compose them. In this paper, we focus on Multimodal Large Language Models (MLLM), and study their ability to compose skills across modalities. To this end, we design three evaluation tasks which can be solved sequentially composing two modality-dependent skills, and evaluate several open MLLMs under two main settings: i) prompting the model to directly solve the task, and ii) using a two-step cascaded inference approach, which manually enforces the composition of the two skills for a given task. Even with these straightforward compositions, we find that all evaluated MLLMs exhibit a significant cross-modality skill composition gap. To mitigate the aforementioned gap, we explore two alternatives: i) use chain-of-thought prompting to explicitly instruct MLLMs for skill composition and ii) a specific fine-tuning recipe to promote skill composition. Although those strategies improve model performance, they still exhibit significant skill composition gaps, suggesting that more research is needed to improve cross-modal skill composition in MLLMs.
Improving the Efficiency of Visually Augmented Language Models
Sep 17, 2024



Despite the impressive performance of autoregressive Language Models (LM) it has been shown that due to reporting bias, LMs lack visual knowledge, i.e. they do not know much about the visual world and its properties. To augment LMs with visual knowledge, existing solutions often rely on explicit images, requiring time-consuming retrieval or image generation systems. This paper shows that explicit images are not necessary to visually augment an LM. Instead, we use visually-grounded text representations obtained from the well-known CLIP multimodal system. For a fair comparison, we modify VALM, a visually-augmented LM which uses image retrieval and representation, to work directly with visually-grounded text representations. We name this new model BLIND-VALM. We show that BLIND-VALM performs on par with VALM for Visual Language Understanding (VLU), Natural Language Understanding (NLU) and Language Modeling tasks, despite being significantly more efficient and simpler. We also show that scaling up our model within the compute budget of VALM, either increasing the model or pre-training corpus size, we outperform VALM for all the evaluation tasks.