 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Machine: Towards Generative World Modeling for Time-Series
May 21, 2026World models represent a paradigm shift in generative AI, pursuing predictive understanding and controllable simulation of environments in a structured and generalizable way. We present World Machine, a generative world-modeling architecture for time series. It is a transformer-based architecture with latent states that enables adaptation to different amounts of observed data and contexts. This shows an improvement over traditional transformers, which have a computational and memory cost that scales quadratically with the context. Experiments on a proposed synthetic dataset, Toy1D, validate the approach's feasibility, demonstrate capabilities not found in conventional transformers, and highlight the contributions of each component of the training protocol.
Hidden bawls, whispers, and yelps: can text be made to sound more than just its words?
Feb 22, 2022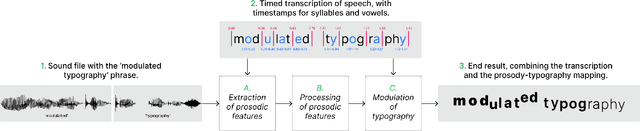
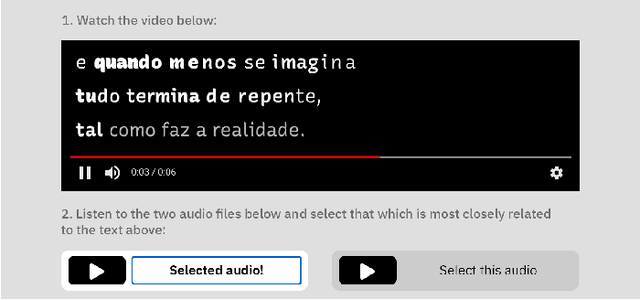

Whether a word was bawled, whispered, or yelped, captions will typically represent it in the same way. If they are your only way to access what is being said, subjective nuances expressed in the voice will be lost. Since so much of communication is carried by these nuances, we posit that if captions are to be used as an accurate representation of speech, embedding visual representations of paralinguistic qualities into captions could help readers use them to better understand speech beyond its mere textual content. This paper presents a model for processing vocal prosody (its loudness, pitch, and duration) and mapping it into visual dimensions of typography (respectively, font-weight, baseline shift, and letter-spacing), creating a visual representation of these lost vocal subtleties that can be embedded directly into the typographical form of text. An evaluation was carried out where participants were exposed to this speech-modulated typography and asked to match it to its originating audio, presented between similar alternatives. Participants (n=117) were able to correctly identify the original audios with an average accuracy of 65%, with no significant difference when showing them modulations as animated or static text. Additionally, participants' comments showed their mental models of speech-modulated typography varied widely.