 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOSH: Bayesian Optimization by Sampling Hierarchically
Jul 02, 2020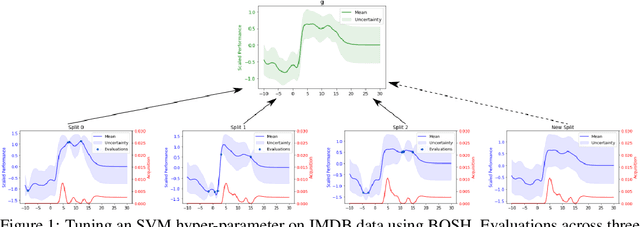
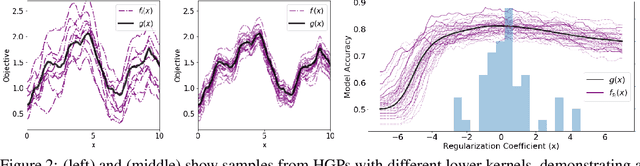
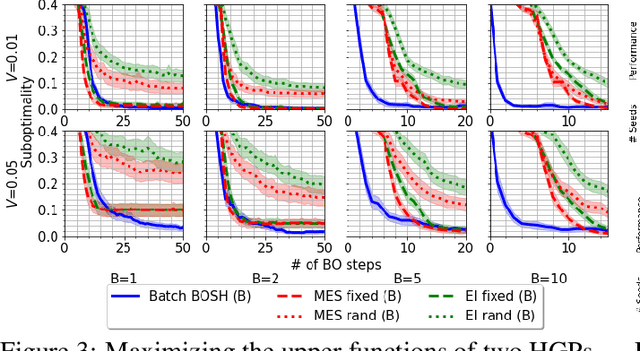
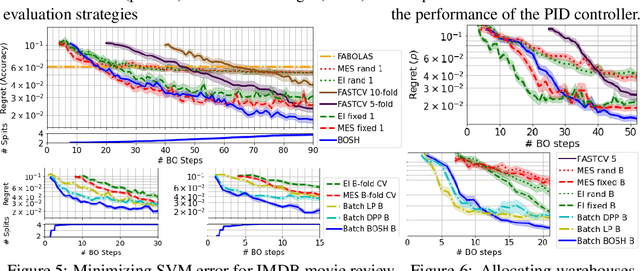
Deployments of Bayesian Optimization (BO) for functions with stochastic evaluations, such as parameter tuning via cross validation and simulation optimization, typically optimize an average of a fixed set of noisy realizations of the objective function. However, disregarding the true objective function in this manner finds a high-precision optimum of the wrong function. To solve this problem, we propose Bayesian Optimization by Sampling Hierarchically (BOSH), a novel BO routine pairing a hierarchical Gaussian process with an information-theoretic framework to generate a growing pool of realizations as the optimization progresses. We demonstrate that BOSH provides more efficient and higher-precision optimization than standard BO across synthetic benchmarks, simulation optimization, reinforcement learning and hyper-parameter tuning tasks.
MUMBO: MUlti-task Max-value Bayesian Optimization
Jun 22, 2020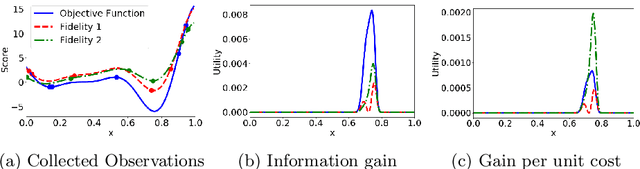
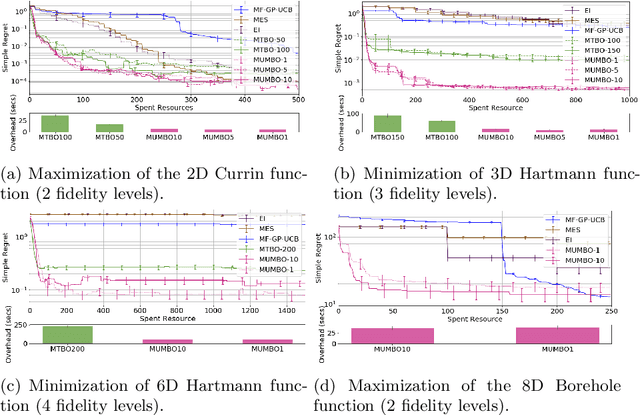
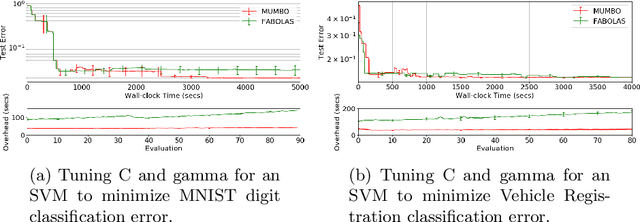
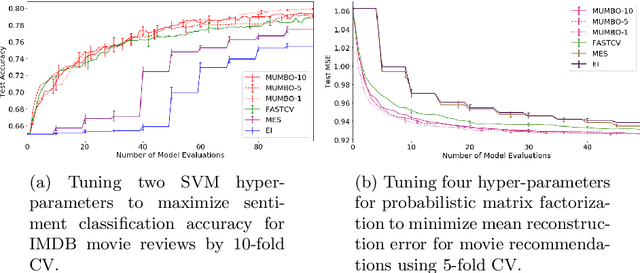
We propose MUMBO, the first high-performing yet computationally efficient acquisition function for multi-task Bayesian optimization. Here, the challenge is to perform efficient optimization by evaluating low-cost functions somehow related to our true target function. This is a broad class of problems including the popular task of multi-fidelity optimization. However, while information-theoretic acquisition functions are known to provide state-of-the-art Bayesian optimization, existing implementations for multi-task scenarios have prohibitive computational requirements. Previous acquisition functions have therefore been suitable only for problems with both low-dimensional parameter spaces and function query costs sufficiently large to overshadow very significant optimization overheads. In this work, we derive a novel multi-task version of entropy search, delivering robust performance with low computational overheads across classic optimization challenges and multi-task hyper-parameter tuning. MUMBO is scalable and efficient, allowing multi-task Bayesian optimization to be deployed in problems with rich parameter and fidelity spaces.
Igbo-English Machine Translation: An Evaluation Benchmark
Apr 01, 2020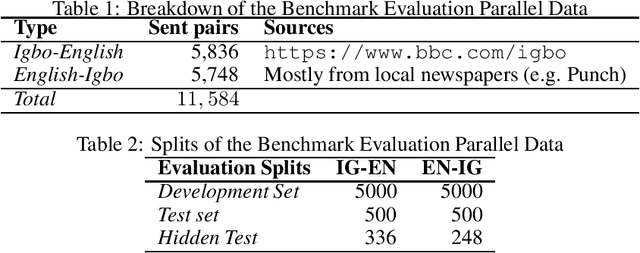

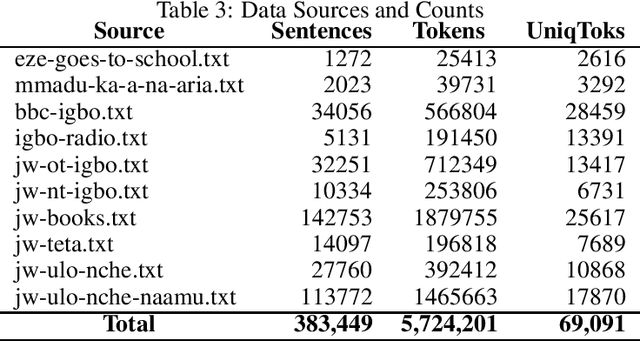
Although researchers and practitioners are pushing the boundaries and enhancing the capacities of NLP tools and methods, works on African languages are lagging. A lot of focus on well resourced languages such as English, Japanese, German, French, Russian, Mandarin Chinese etc. Over 97% of the world's 7000 languages, including African languages, are low resourced for NLP i.e. they have little or no data, tools, and techniques for NLP research. For instance, only 5 out of 2965, 0.19% authors of full text papers in the ACL Anthology extracted from the 5 major conferences in 2018 ACL, NAACL, EMNLP, COLING and CoNLL, are affiliated to African institutions. In this work, we discuss our effort toward building a standard machine translation benchmark dataset for Igbo, one of the 3 major Nigerian languages. Igbo is spoken by more than 50 million people globally with over 50% of the speakers are in southeastern Nigeria. Igbo is low resourced although there have been some efforts toward developing IgboNLP such as part of speech tagging and diacritic restoration
FIESTA: Fast IdEntification of State-of-The-Art models using adaptive bandit algorithms
Jun 28, 2019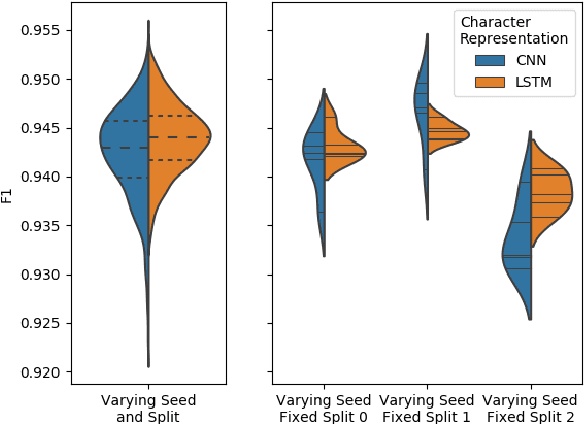

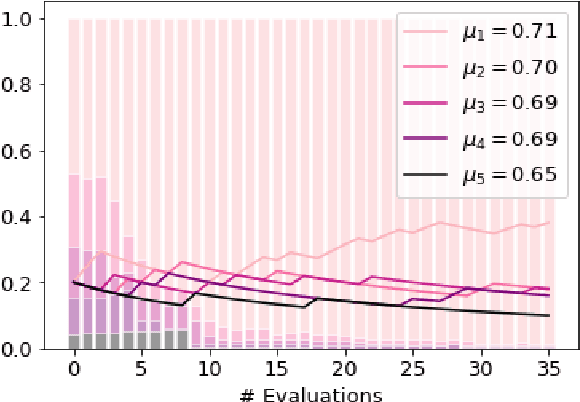
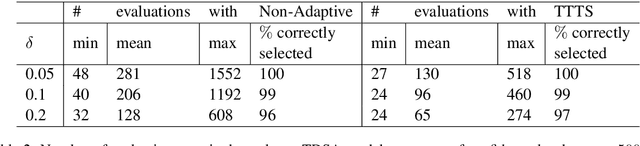
We present FIESTA, a model selection approach that significantly reduces the computational resources required to reliably identify state-of-the-art performance from large collections of candidate models. Despite being known to produce unreliable comparisons, it is still common practice to compare model evaluations based on single choices of random seeds. We show that reliable model selection also requires evaluations based on multiple train-test splits (contrary to common practice in many shared tasks). Using bandit theory from the statistics literature, we are able to adaptively determine appropriate numbers of data splits and random seeds used to evaluate each model, focusing computational resources on the evaluation of promising models whilst avoiding wasting evaluations on models with lower performance. Furthermore, our user-friendly Python implementation produces confidence guarantees of correctly selecting the optimal model. We evaluate our algorithms by selecting between 8 target-dependent sentiment analysis methods using dramatically fewer model evaluations than current model selection approaches.
In Search of Meaning: Lessons, Resources and Next Steps for Computational Analysis of Financial Discourse
Mar 28, 2019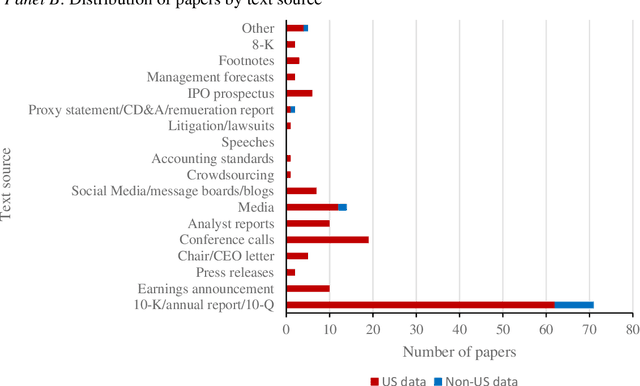
We critically assess mainstream accounting and finance research applying methods from computational linguistics (CL) to study financial discourse. We also review common themes and innovations in the literature and assess the incremental contributions of work applying CL methods over manual content analysis. Key conclusions emerging from our analysis are: (a) accounting and finance research is behind the curve in terms of CL methods generally and word sense disambiguation in particular; (b) implementation issues mean the proposed benefits of CL are often less pronounced than proponents suggest; (c) structural issues limit practical relevance; and (d) CL methods and high quality manual analysis represent complementary approaches to analyzing financial discourse. We describe four CL tools that have yet to gain traction in mainstream AF research but which we believe offer promising ways to enhance the study of meaning in financial discourse. The four tools are named entity recognition (NER), summarization, semantics and corpus linguistics.
Bringing replication and reproduction together with generalisability in NLP: Three reproduction studies for Target Dependent Sentiment Analysis
Aug 06, 2018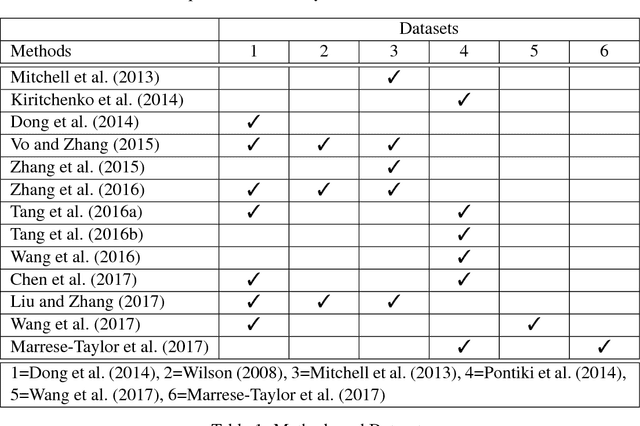
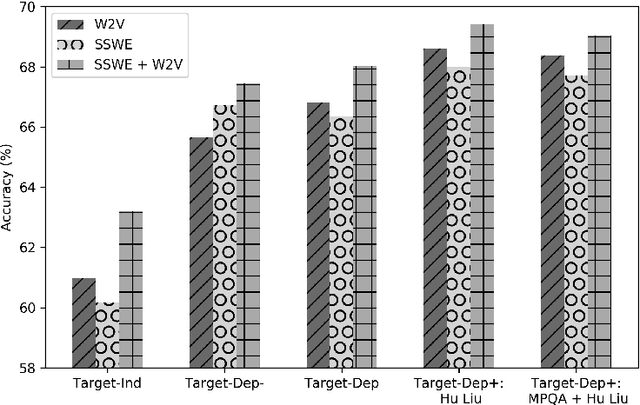
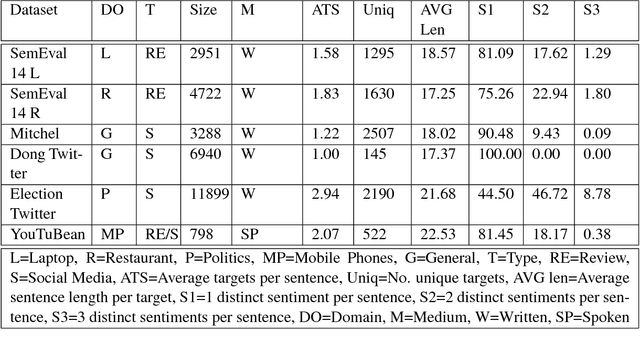
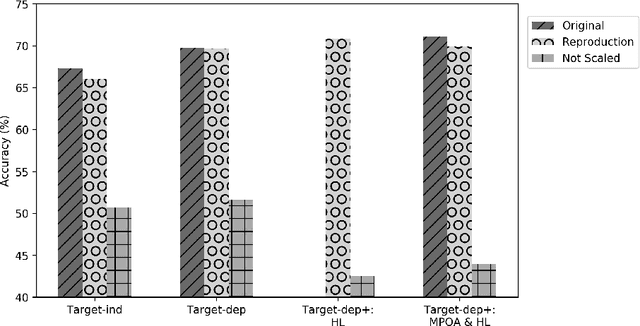
Lack of repeatability and generalisability are two significant threats to continuing scientific development in Natural Language Processing. Language models and learning methods are so complex that scientific conference papers no longer contain enough space for the technical depth required for replication or reproduction. Taking Target Dependent Sentiment Analysis as a case study, we show how recent work in the field has not consistently released code, or described settings for learning methods in enough detail, and lacks comparability and generalisability in train, test or validation data. To investigate generalisability and to enable state of the art comparative evaluations, we carry out the first reproduction studies of three groups of complementary methods and perform the first large-scale mass evaluation on six different English datasets. Reflecting on our experiences, we recommend that future replication or reproduction experiments should always consider a variety of datasets alongside documenting and releasing their methods and published code in order to minimise the barriers to both repeatability and generalisability. We have released our code with a model zoo on GitHub with Jupyter Notebooks to aid understanding and full documentation, and we recommend that others do the same with their papers at submission time through an anonymised GitHub account.
Using J-K fold Cross Validation to Reduce Variance When Tuning NLP Models
Jun 19, 2018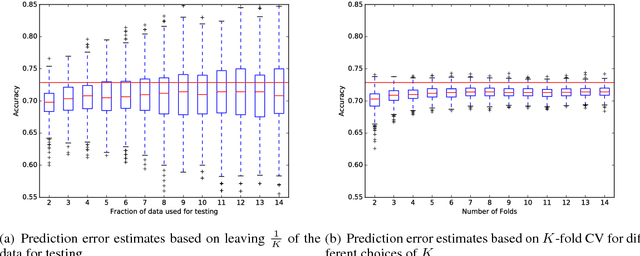
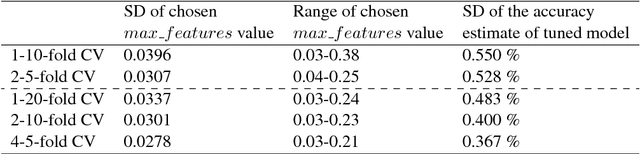
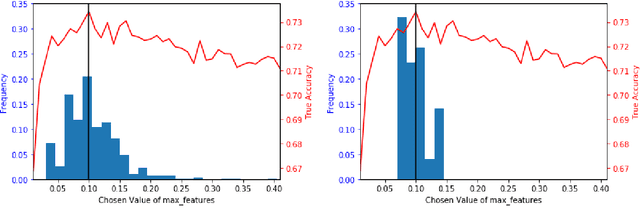
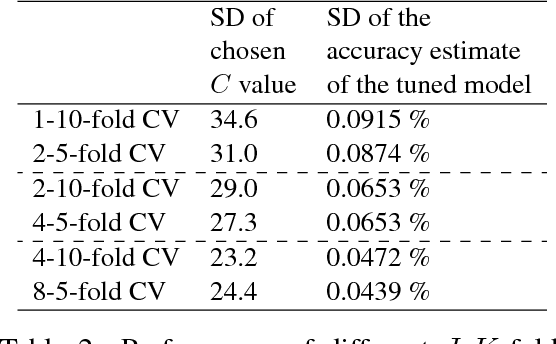
K-fold cross validation (CV) is a popular method for estimating the true performance of machine learning models, allowing model selection and parameter tuning. However, the very process of CV requires random partitioning of the data and so our performance estimates are in fact stochastic, with variability that can be substantial for natural language processing tasks. We demonstrate that these unstable estimates cannot be relied upon for effective parameter tuning. The resulting tuned parameters are highly sensitive to how our data is partitioned, meaning that we often select sub-optimal parameter choices and have serious reproducibility issues. Instead, we propose to use the less variable J-K-fold CV, in which J independent K-fold cross validations are used to assess performance. Our main contributions are extending J-K-fold CV from performance estimation to parameter tuning and investigating how to choose J and K. We argue that variability is more important than bias for effective tuning and so advocate lower choices of K than are typically seen in the NLP literature, instead use the saved computation to increase J. To demonstrate the generality of our recommendations we investigate a wide range of case-studies: sentiment classification (both general and target-specific), part-of-speech tagging and document classification.
Lancaster A at SemEval-2017 Task 5: Evaluation metrics matter: predicting sentiment from financial news headlines
May 01, 2017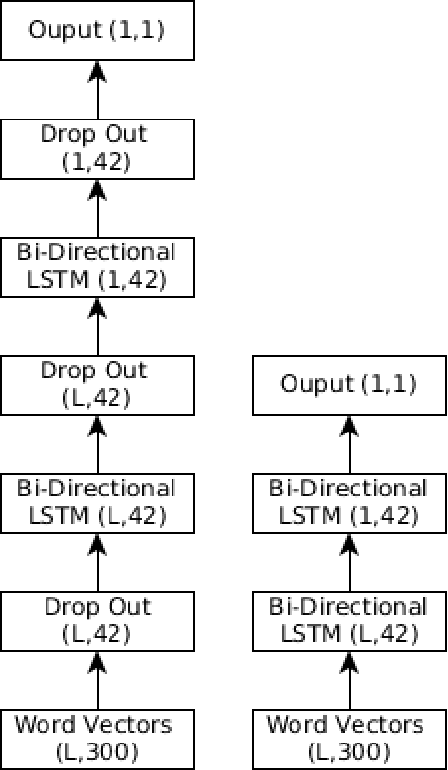
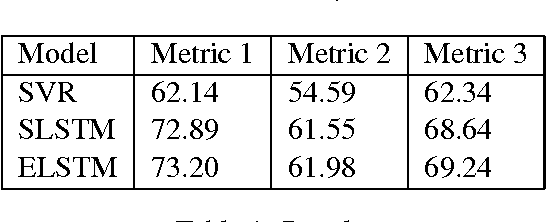
This paper describes our participation in Task 5 track 2 of SemEval 2017 to predict the sentiment of financial news headlines for a specific company on a continuous scale between -1 and 1. We tackled the problem using a number of approaches, utilising a Support Vector Regression (SVR) and a Bidirectional Long Short-Term Memory (BLSTM). We found an improvement of 4-6% using the LSTM model over the SVR and came fourth in the track. We report a number of different evaluations using a finance specific word embedding model and reflect on the effects of using different evaluation metrics.