 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Qualitative Review of GenAI-Based Methods for Data Generation and Augmentation in Industrial Computer Vision Applications
Jun 12, 2026AI-driven computer vision applications require a profound database to ensure predictable behaviors and performance. Such predictable behaviors are especially important for industrial applications in gaining trust from users. However, such a database is not readily available in industrial applications, and its acquisition is not trivial either. Active learning methods can be applied to ramp up data within a project deployment to iteratively increase the database, and thus the application predictability. Unfortunately, we observe that this often leads to a loss of user trust in the application, which is difficult to regain once lost. This leads to a "chicken-and-egg" dilemma in which neither the database nor the application is developed. In this work, we review state-of-the-art methods and approaches to further boost the database the initial active data ramp-up phase. Here, we focus on recent advancements in GenAI-based data generation and augmentation methods and review their adaptability on an industrial computer vision classification use case. Although we observe a potential for automatic data ramp-up, we also see a domain miss match in between the source (training environment) and target (industrial use-case) - regarding context defined in natural language and object characteristics.
A Mixed Initiative Semantic Web Framework for Process Composition
Jun 03, 2020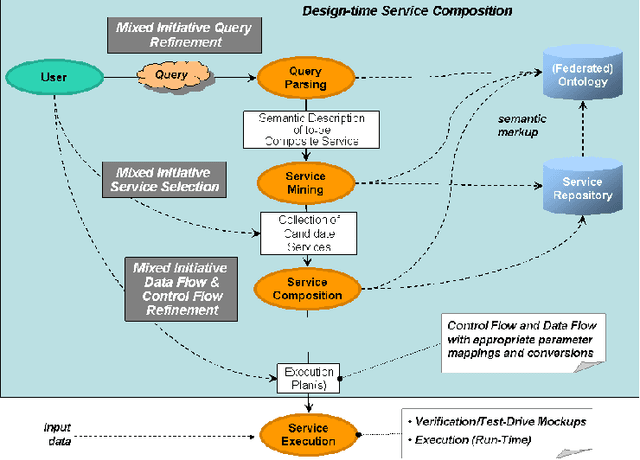
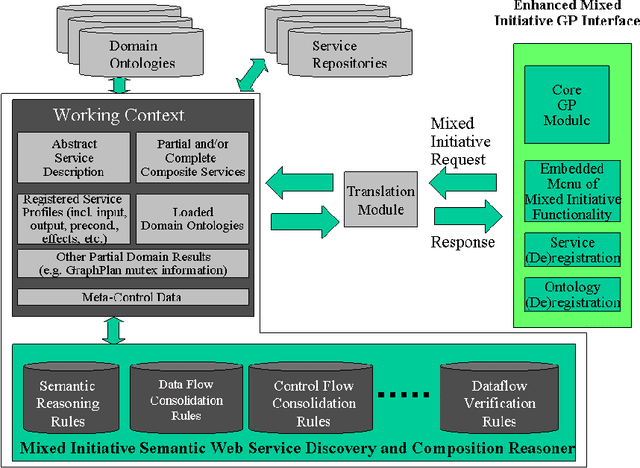
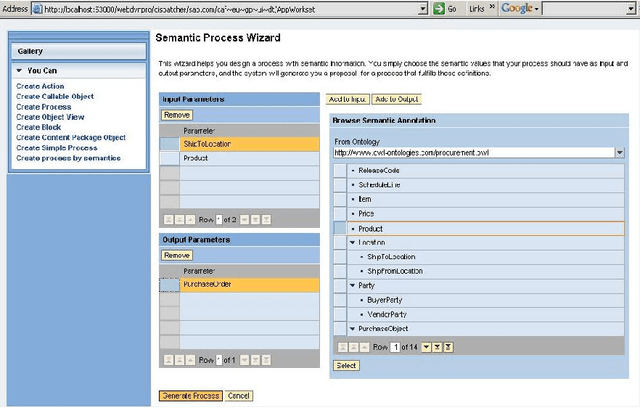
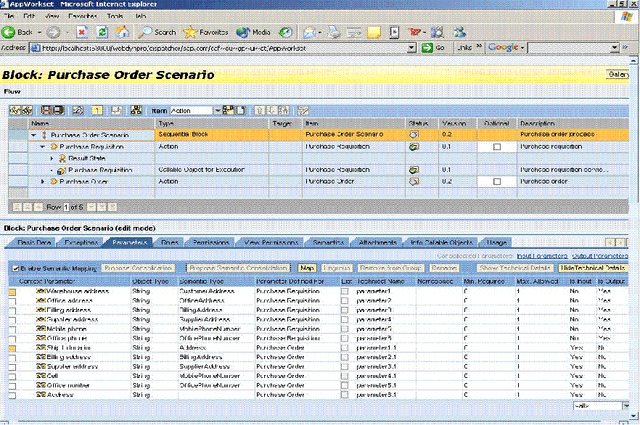
Semantic Web technologies offer the prospect of significantly reducing the amount of effort required to integrate existing enterprise functionality in support of new composite processes; whether within a given organization or across multiple ones. A significant body of work in this area has aimed to fully automate this process, while assuming that all functionality has already been encapsulated in the form of semantic web services with rich and accurate annotations. In this article, we argue that this assumption is often unrealistic. Instead, we describe a mixed initiative framework for semantic web service discovery and composition that aims at flexibly interleaving human decision making and automated functionality in environments where annotations may be incomplete and even inconsistent.
Hidden Markov Models and their Application for Predicting Failure Events
May 20, 2020



We show how Markov mixed membership models (MMMM) can be used to predict the degradation of assets. We model the degradation path of individual assets, to predict overall failure rates. Instead of a separate distribution for each hidden state, we use hierarchical mixtures of distributions in the exponential family. In our approach the observation distribution of the states is a finite mixture distribution of a small set of (simpler) distributions shared across all states. Using tied-mixture observation distributions offers several advantages. The mixtures act as a regularization for typically very sparse problems, and they reduce the computational effort for the learning algorithm since there are fewer distributions to be found. Using shared mixtures enables sharing of statistical strength between the Markov states and thus transfer learning. We determine for individual assets the trade-off between the risk of failure and extended operating hours by combining a MMMM with a partially observable Markov decision process (POMDP) to dynamically optimize the policy for when and how to maintain the asset.