 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universal Deep Room Acoustics Estimator
Sep 29, 2021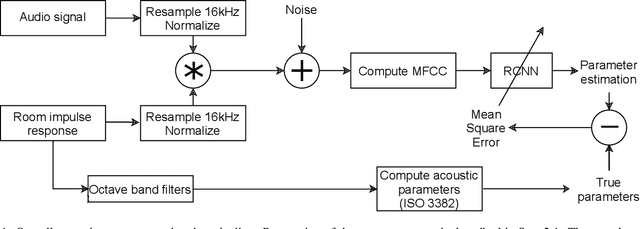
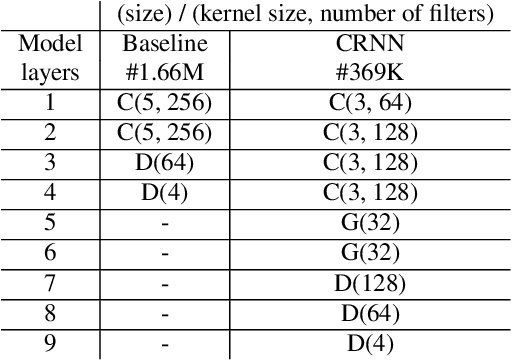
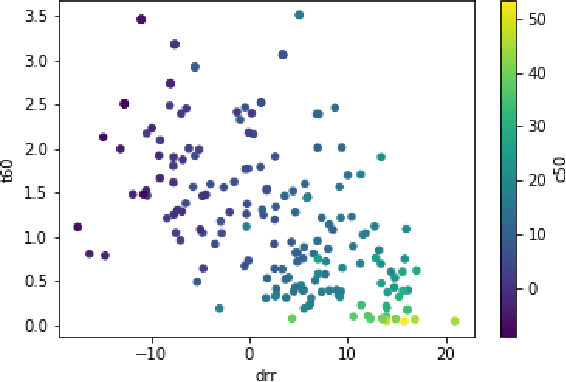
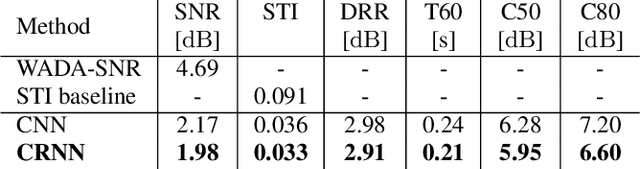
Speech audio quality is subject to degradation caused by an acoustic environment and isotropic ambient and point noises. The environment can lead to decreased speech intelligibility and loss of focus and attention by the listener. Basic acoustic parameters that characterize the environment well are (i) signal-to-noise ratio (SNR), (ii) speech transmission index, (iii) reverberation time, (iv) clarity, and (v) direct-to-reverberant ratio. Except for the SNR, these parameters are usually derived from the Room Impulse Response (RIR) measurements; however, such measurements are often not available. This work presents a universal room acoustic estimator design based on convolutional recurrent neural networks that estimate the acoustic environment measurement blindly and jointly. Our results indicate that the proposed system is robust to non-stationary signal variations and outperforms current state-of-the-art methods.
* Room acoustics, Convolutional Recurrent Neural Network, RT60, C50, DRR, STI, SNR
Joint Blind Room Acoustic Characterization From Speech And Music Signals Using Convolutional Recurrent Neural Networks
Oct 21, 2020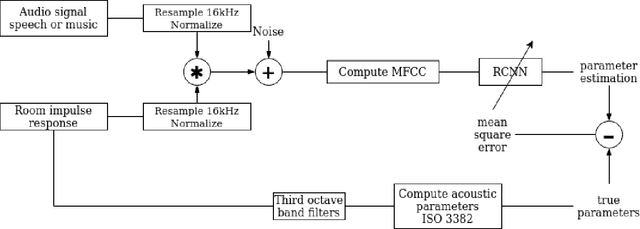
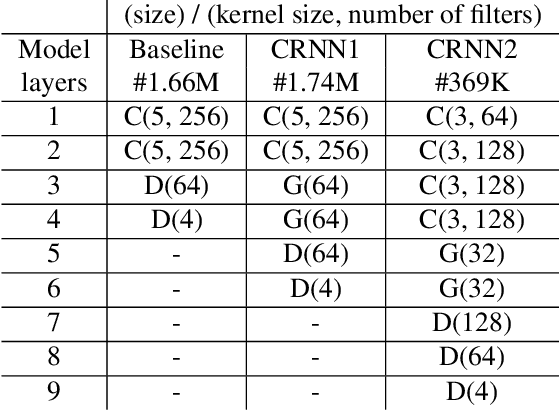
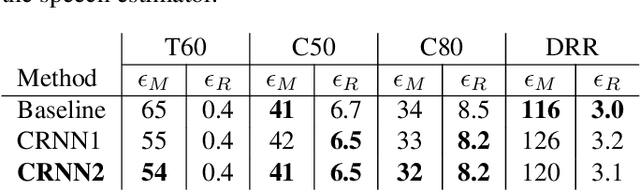
Acoustic environment characterization opens doors for sound reproduction innovations, smart EQing, speech enhancement, hearing aids, and forensics. Reverberation time, clarity, and direct-to-reverberant ratio are acoustic parameters that have been defined to describe reverberant environments. They are closely related to speech intelligibility and sound quality. As explained in the ISO3382 standard, they can be derived from a room measurement called the Room Impulse Response (RIR). However, measuring RIRs requires specific equipment and intrusive sound to be played. The recent audio combined with machine learning suggests that one could estimate those parameters blindly using speech or music signals. We follow these advances and propose a robust end-to-end method to achieve blind joint acoustic parameter estimation using speech and/or music signals. Our results indicate that convolutional recurrent neural networks perform best for this task, and including music in training also helps improve inference from speech.