 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Space Constraints Improve the Generalization of the Differentiable Neural Computer in some Algorithmic Tasks
Oct 18, 2021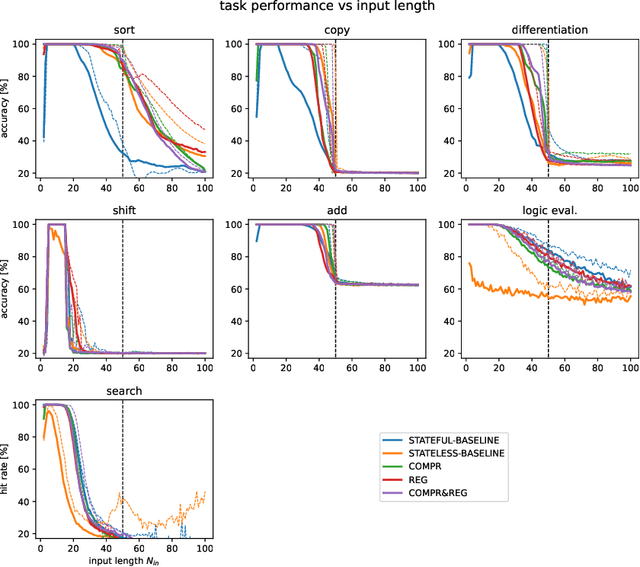
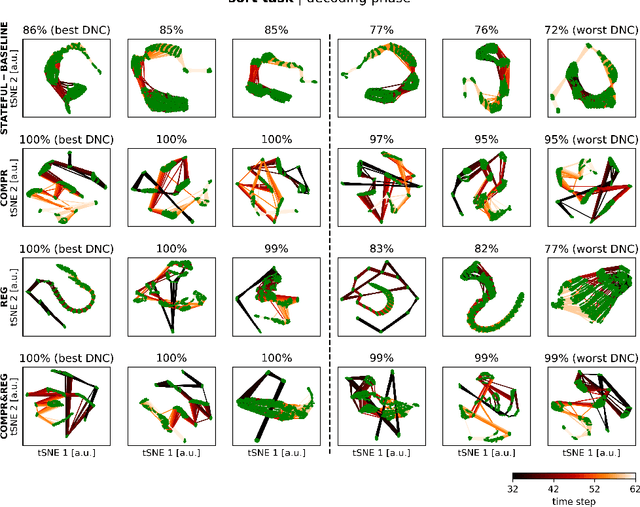
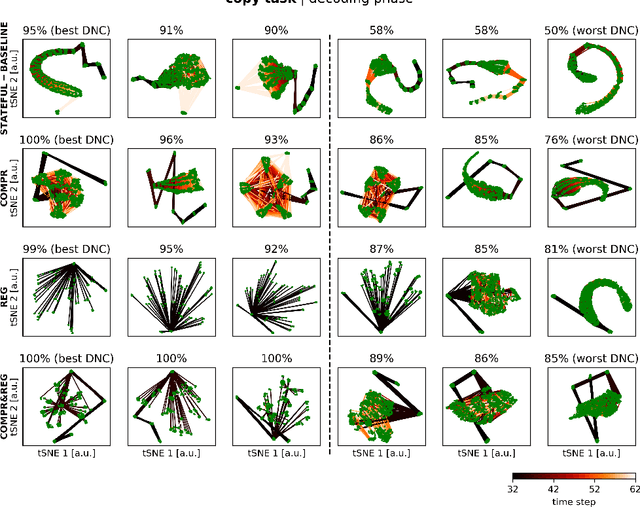
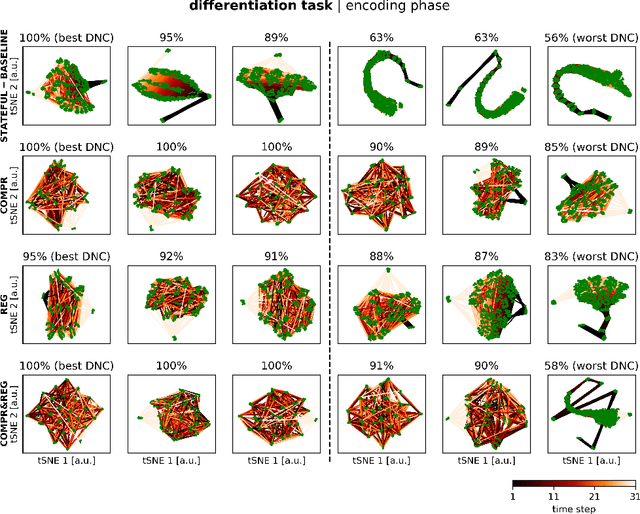
Memory-augmented neural networks (MANNs) can solve algorithmic tasks like sorting. However, they often do not generalize to lengths of input sequences not seen in the training phase. Therefore, we introduce two approaches constraining the state-space of the network controller to improve the generalization to out-of-distribution-sized input sequences: state compression and state regularization. We show that both approaches can improve the generalization capability of a particular type of MANN, the differentiable neural computer (DNC), and compare our approaches to a stateful and a stateless controller on a set of algorithmic tasks. Furthermore, we show that especially the combination of both approaches can enable a pre-trained DNC to be extended post hoc with a larger memory. Thus, our introduced approaches allow to train a DNC using shorter input sequences and thus save computational resources. Moreover, we observed that the capability for generalization is often accompanied by loop structures in the state-space, which could correspond to looping constructs in algorithms.
Lessons Learned from the 1st ARIEL Machine Learning Challenge: Correcting Transiting Exoplanet Light Curves for Stellar Spots
Oct 29, 2020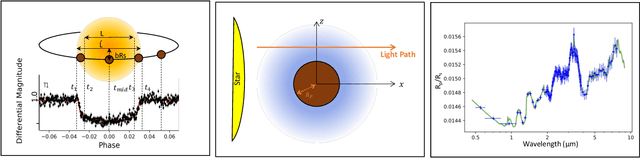

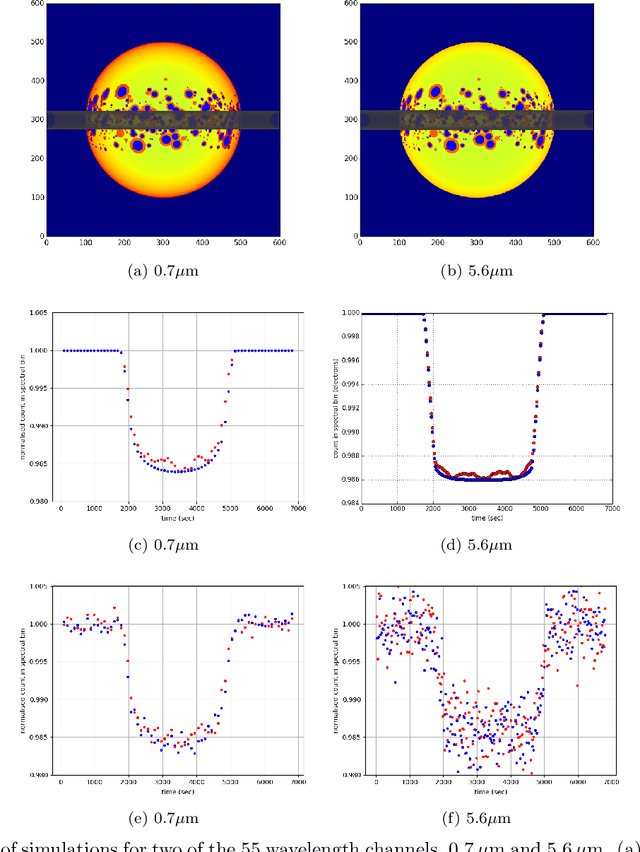
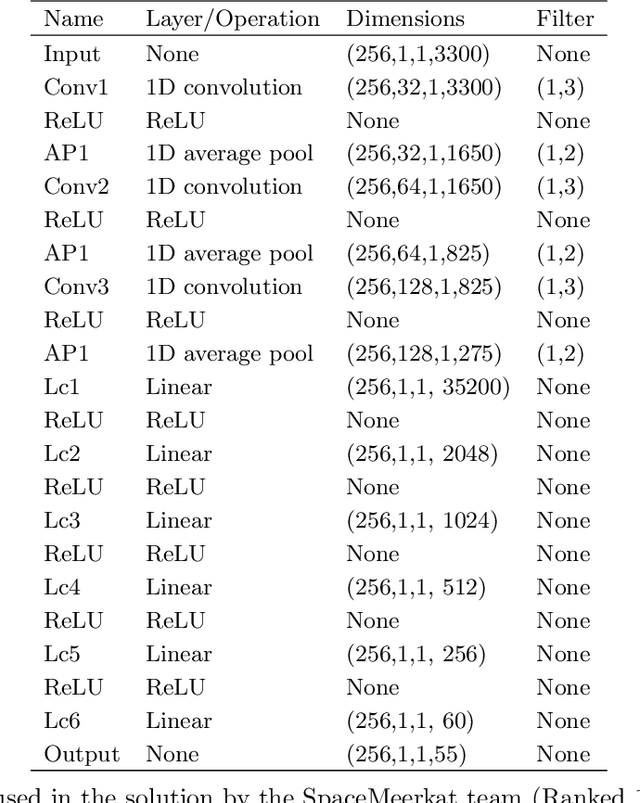
The last decade has witnessed a rapid growth of the field of exoplanet discovery and characterisation. However, several big challenges remain, many of which could be addressed using machine learning methodology. For instance, the most prolific method for detecting exoplanets and inferring several of their characteristics, transit photometry, is very sensitive to the presence of stellar spots. The current practice in the literature is to identify the effects of spots visually and correct for them manually or discard the affected data. This paper explores a first step towards fully automating the efficient and precise derivation of transit depths from transit light curves in the presence of stellar spots. The methods and results we present were obtained in the context of the 1st Machine Learning Challenge organized for the European Space Agency's upcoming Ariel mission. We first present the problem, the simulated Ariel-like data and outline the Challenge while identifying best practices for organizing similar challenges in the future. Finally, we present the solutions obtained by the top-5 winning teams, provide their code and discuss their implications. Successful solutions either construct highly non-linear (w.r.t. the raw data) models with minimal preprocessing -deep neural networks and ensemble methods- or amount to obtaining meaningful statistics from the light curves, constructing linear models on which yields comparably good predictive performance.