 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Patch Pruning: Efficient Video Instance Segmentation via Early Token Reduction
Apr 01, 2026Vision Transformers (ViTs) have demonstrated state-ofthe-art performance in several benchmarks, yet their high computational costs hinders their practical deployment. Patch Pruning offers significant savings, but existing approaches restrict token reduction to deeper layers, leaving early-stage compression unexplored. This limits their potential for holistic efficiency. In this work, we present a novel Video Patch Pruning framework (VPP) that integrates temporal prior knowledge to enable efficient sparsity within early ViT layers. Our approach is motivated by the observation that prior features extracted from deeper layers exhibit strong foreground selectivity. Therefore we propose a fully differentiable module for temporal mapping to accurately select the most relevant patches in early network stages. Notably, the proposed method enables a patch reduction of up to 60% in dense prediction tasks, exceeding the capabilities of conventional image-based patch pruning, which typically operate around a 30% patch sparsity. VPP excels the high-sparsity regime, sustaining remarkable performance even when patch usage is reduced below 55%. Specifically, it preserves stable results with a maximal performance drop of 0.6% on the Youtube-VIS 2021 dataset.
HyperSparse Neural Networks: Shifting Exploration to Exploitation through Adaptive Regularization
Aug 16, 2023

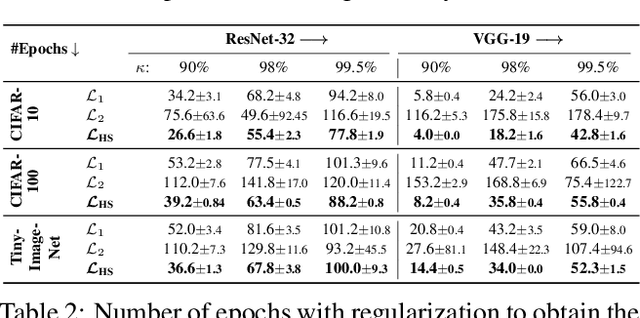

Sparse neural networks are a key factor in developing resource-efficient machine learning applications. We propose the novel and powerful sparse learning method Adaptive Regularized Training (ART) to compress dense into sparse networks. Instead of the commonly used binary mask during training to reduce the number of model weights, we inherently shrink weights close to zero in an iterative manner with increasing weight regularization. Our method compresses the pre-trained model knowledge into the weights of highest magnitude. Therefore, we introduce a novel regularization loss named HyperSparse that exploits the highest weights while conserving the ability of weight exploration. Extensive experiments on CIFAR and TinyImageNet show that our method leads to notable performance gains compared to other sparsification methods, especially in extremely high sparsity regimes up to 99.8 percent model sparsity. Additional investigations provide new insights into the patterns that are encoded in weights with high magnitudes.