 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTBench: A Curriculum-Grounded Benchmark for Evaluating LLMs as Mathematical Research Assistants in Graph Theory
Jun 02, 2026Large language models (LLMs) are increasingly used as self-study assistants in technical disciplines, yet their reliability as mathematical reasoning assistants remains poorly understood. We introduce GTBench, a curriculum-grounded benchmark for evaluating LLMs as mathematical research assistants in graph theory, comprising 63 problems organized into three groups of increasing difficulty: undergraduate definitions and basic properties (Group 1), algorithm tracing and structural reasoning (Group 2), and graduate-level proof construction (Group 3). Problems are sourced from verified academic materials including Diestel's Graph Theory. We evaluate five frontier models -- GPT-5, Claude Sonnet 4.6, Gemini 2.5 Flash-Lite, Llama 3.3 70B, and Mistral Large 3 -- under zero-shot and chain-of-thought prompting, using exact-match and LLM-as-judge evaluation for Groups 1 and 2, and a hybrid human expert and LLM-as-judge protocol for Group 3. Our results reveal a pronounced performance hierarchy: GPT-5 approaches ceiling on Group 1 (95.8% zero-shot) and maintains meaningful accuracy on graduate proofs (82%), while all other models degrade substantially with difficulty, with Llama achieving 0% under human evaluation on Group 3 zero-shot. Failure mode analysis shows that correct algorithm, wrong execution errors dominate Groups 1 and 2, while Group 3 additionally surfaces incomplete reasoning failures and reveals systematic disagreement between human evaluators and the automated judge, particularly on verbose or near-complete proofs (kappa = 0.48-0.83 across human pairs). GTBench provides the first curriculum-grounded evaluation framework for graph-theoretic reasoning in LLMs, with direct implications for the governance of AI tools in mathematical education and scientific research.
LLM Benchmarking with LLaMA2: Evaluating Code Development Performance Across Multiple Programming Languages
Mar 24, 2025



The rapid evolution of large language models (LLMs) has opened new possibilities for automating various tasks in software development. This paper evaluates the capabilities of the Llama 2-70B model in automating these tasks for scientific applications written in commonly used programming languages. Using representative test problems, we assess the model's capacity to generate code, documentation, and unit tests, as well as its ability to translate existing code between commonly used programming languages. Our comprehensive analysis evaluates the compilation, runtime behavior, and correctness of the generated and translated code. Additionally, we assess the quality of automatically generated code, documentation and unit tests. Our results indicate that while Llama 2-70B frequently generates syntactically correct and functional code for simpler numerical tasks, it encounters substantial difficulties with more complex, parallelized, or distributed computations, requiring considerable manual corrections. We identify key limitations and suggest areas for future improvements to better leverage AI-driven automation in scientific computing workflows.
Evaluating AI-generated code for C++, Fortran, Go, Java, Julia, Matlab, Python, R, and Rust
May 21, 2024This study evaluates the capabilities of ChatGPT versions 3.5 and 4 in generating code across a diverse range of programming languages. Our objective is to assess the effectiveness of these AI models for generating scientific programs. To this end, we asked ChatGPT to generate three distinct codes: a simple numerical integration, a conjugate gradient solver, and a parallel 1D stencil-based heat equation solver. The focus of our analysis was on the compilation, runtime performance, and accuracy of the codes. While both versions of ChatGPT successfully created codes that compiled and ran (with some help), some languages were easier for the AI to use than others (possibly because of the size of the training sets used). Parallel codes -- even the simple example we chose to study here -- also difficult for the AI to generate correctly.
ML-based identification of the interface regions for coupling local and nonlocal models
Apr 23, 2024Local-nonlocal coupling approaches combine the computational efficiency of local models and the accuracy of nonlocal models. However, the coupling process is challenging, requiring expertise to identify the interface between local and nonlocal regions. This study introduces a machine learning-based approach to automatically detect the regions in which the local and nonlocal models should be used in a coupling approach. This identification process uses the loading functions and provides as output the selected model at the grid points. Training is based on datasets of loading functions for which reference coupling configurations are computed using accurate coupled solutions, where accuracy is measured in terms of the relative error between the solution to the coupling approach and the solution to the nonlocal model. We study two approaches that differ from one another in terms of the data structure. The first approach, referred to as the full-domain input data approach, inputs the full load vector and outputs a full label vector. In this case, the classification process is carried out globally. The second approach consists of a window-based approach, where loads are preprocessed and partitioned into windows and the problem is formulated as a node-wise classification approach in which the central point of each window is treated individually. The classification problems are solved via deep learning algorithms based on convolutional neural networks. The performance of these approaches is studied on one-dimensional numerical examples using F1-scores and accuracy metrics. In particular, it is shown that the windowing approach provides promising results, achieving an accuracy of 0.96 and an F1-score of 0.97. These results underscore the potential of the approach to automate coupling processes, leading to more accurate and computationally efficient solutions for material science applications.
Towards a Scalable and Distributed Infrastructure for Deep Learning Applications
Oct 06, 2020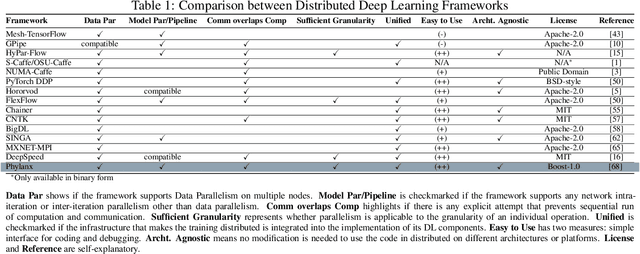
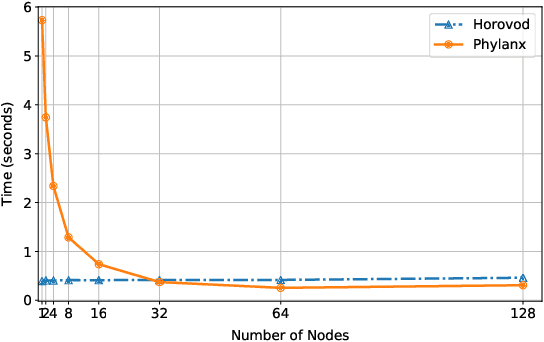
Although recent scaling up approaches to train deep neural networks have proven to be effective, the computational intensity of large and complex models, as well as the availability of large-scale datasets require deep learning frameworks to utilize scaling out techniques. Parallelization approaches and distribution requirements are not considered in the primary designs of most available distributed deep learning frameworks and most of them still are not able to perform effective and efficient fine-grained inter-node communication. We present Phylanx that has the potential to alleviate these shortcomings. Phylanx presents a productivity-oriented frontend where user Python code is translated to a futurized execution tree that can be executed efficiently on multiple nodes using the C++ standard library for parallelism and concurrency (HPX), leveraging fine-grained threading and an active messaging task-based runtime system.