 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Sensor-free Affect Detection: A Systematic Literature Review
Oct 11, 2023Emotions and other affective states play a pivotal role in cognition and, consequently, the learning process. It is well-established that computer-based learning environments (CBLEs) that can detect and adapt to students' affective states can enhance learning outcomes. However, practical constraints often pose challenges to the deployment of sensor-based affect detection in CBLEs, particularly for large-scale or long-term applications. As a result, sensor-free affect detection, which exclusively relies on logs of students' interactions with CBLEs, emerges as a compelling alternative. This paper provides a comprehensive literature review on sensor-free affect detection. It delves into the most frequently identified affective states, the methodologies and techniques employed for sensor development, the defining attributes of CBLEs and data samples, as well as key research trends. Despite the field's evident maturity, demonstrated by the consistent performance of the models and the application of advanced machine learning techniques, there is ample scope for future research. Potential areas for further exploration include enhancing the performance of sensor-free detection models, amassing more samples of underrepresented emotions, and identifying additional emotions. There is also a need to refine model development practices and methods. This could involve comparing the accuracy of various data collection techniques, determining the optimal granularity of duration, establishing a shared database of action logs and emotion labels, and making the source code of these models publicly accessible. Future research should also prioritize the integration of models into CBLEs for real-time detection, the provision of meaningful interventions based on detected emotions, and a deeper understanding of the impact of emotions on learning.
An Analysis of Hierarchical Text Classification Using Word Embeddings
Sep 06, 2018
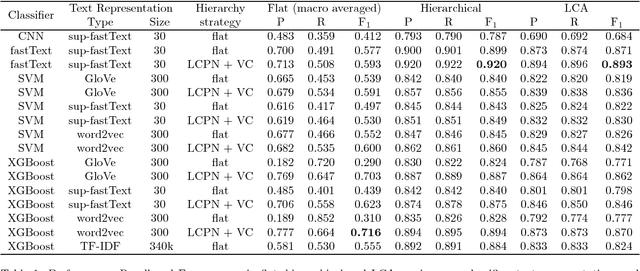

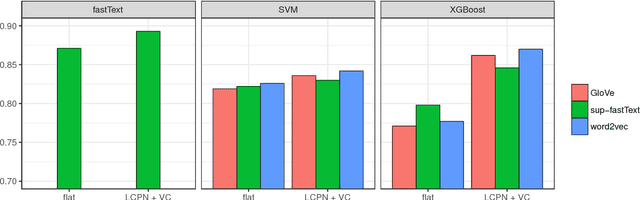
Efficient distributed numerical word representation models (word embeddings) combined with modern machine learning algorithms have recently yielded considerable improvement on automatic document classification tasks. However, the effectiveness of such techniques has not been assessed for the hierarchical text classification (HTC) yet. This study investigates the application of those models and algorithms on this specific problem by means of experimentation and analysis. We trained classification models with prominent machine learning algorithm implementations---fastText, XGBoost, SVM, and Keras' CNN---and noticeable word embeddings generation methods---GloVe, word2vec, and fastText---with publicly available data and evaluated them with measures specifically appropriate for the hierarchical context. FastText achieved an ${}_{LCA}F_1$ of 0.893 on a single-labeled version of the RCV1 dataset. An analysis indicates that using word embeddings and its flavors is a very promising approach for HTC.