 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Factorization Layers for Neural Networks with Limited Supervision
Dec 14, 2016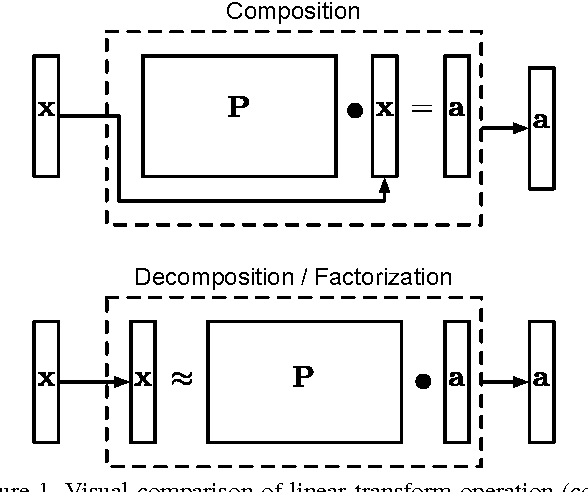
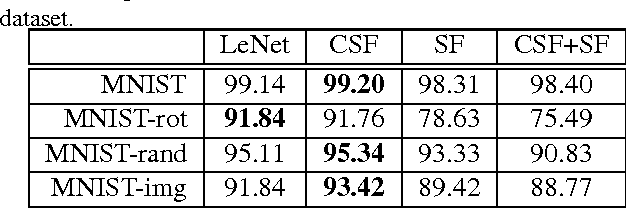
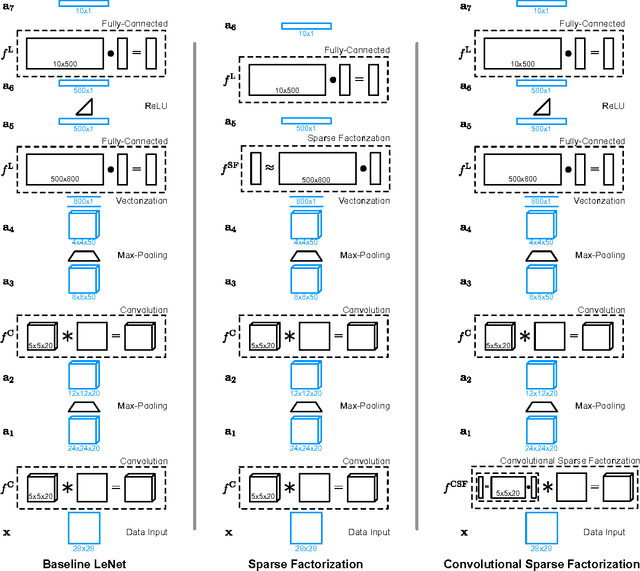
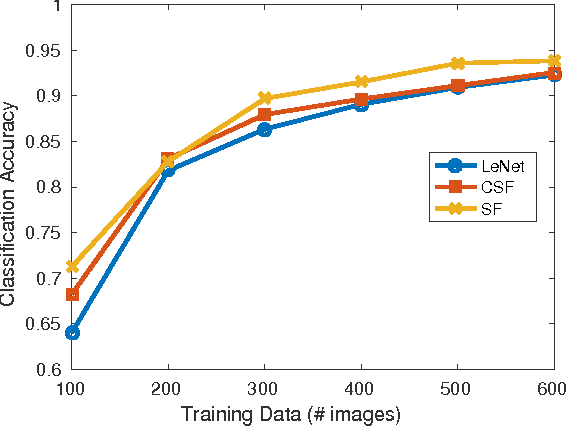
Whereas CNNs have demonstrated immense progress in many vision problems, they suffer from a dependence on monumental amounts of labeled training data. On the other hand, dictionary learning does not scale to the size of problems that CNNs can handle, despite being very effective at low-level vision tasks such as denoising and inpainting. Recently, interest has grown in adapting dictionary learning methods for supervised tasks such as classification and inverse problems. We propose two new network layers that are based on dictionary learning: a sparse factorization layer and a convolutional sparse factorization layer, analogous to fully-connected and convolutional layers, respectively. Using our derivations, these layers can be dropped in to existing CNNs, trained together in an end-to-end fashion with back-propagation, and leverage semisupervision in ways classical CNNs cannot. We experimentally compare networks with these two new layers against a baseline CNN. Our results demonstrate that networks with either of the sparse factorization layers are able to outperform classical CNNs when supervised data are few. They also show performance improvements in certain tasks when compared to the CNN with no sparse factorization layers with the same exact number of parameters.
Watch What You Just Said: Image Captioning with Text-Conditional Attention
Nov 24, 2016
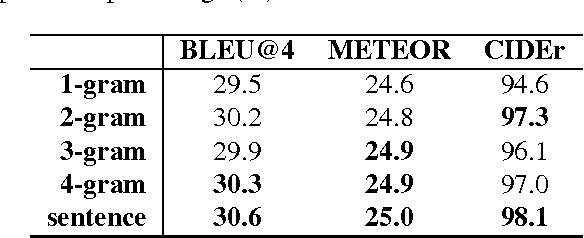
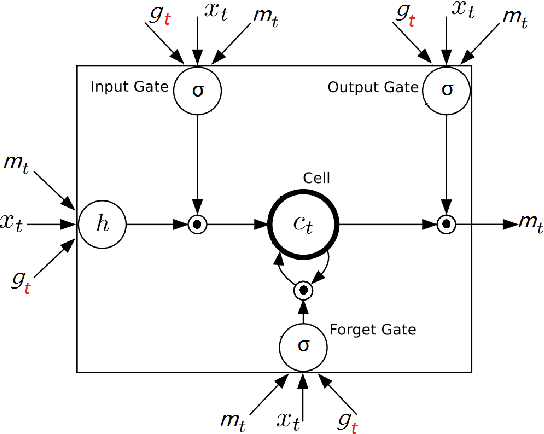

Attention mechanisms have attracted considerable interest in image captioning due to its powerful performance. However, existing methods use only visual content as attention and whether textual context can improve attention in image captioning remains unsolved. To explore this problem, we propose a novel attention mechanism, called \textit{text-conditional attention}, which allows the caption generator to focus on certain image features given previously generated text. To obtain text-related image features for our attention model, we adopt the guiding Long Short-Term Memory (gLSTM) captioning architecture with CNN fine-tuning. Our proposed method allows joint learning of the image embedding, text embedding, text-conditional attention and language model with one network architecture in an end-to-end manner. We perform extensive experiments on the MS-COCO dataset. The experimental results show that our method outperforms state-of-the-art captioning methods on various quantitative metrics as well as in human evaluation, which supports the use of our text-conditional attention in image captioning.