 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoints2NeRF: Generating Neural Radiance Fields from 3D point cloud
Jun 02, 2022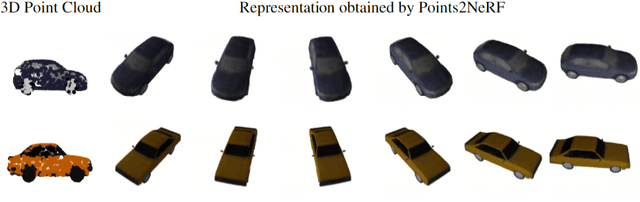



Contemporary registration devices for 3D visual information, such as LIDARs and various depth cameras, capture data as 3D point clouds. In turn, such clouds are challenging to be processed due to their size and complexity. Existing methods address this problem by fitting a mesh to the point cloud and rendering it instead. This approach, however, leads to the reduced fidelity of the resulting visualization and misses color information of the objects crucial in computer graphics applications. In this work, we propose to mitigate this challenge by representing 3D objects as Neural Radiance Fields (NeRFs). We leverage a hypernetwork paradigm and train the model to take a 3D point cloud with the associated color values and return a NeRF network's weights that reconstruct 3D objects from input 2D images. Our method provides efficient 3D object representation and offers several advantages over the existing approaches, including the ability to condition NeRFs and improved generalization beyond objects seen in training. The latter we also confirmed in the results of our empirical evaluation.
HyperMAML: Few-Shot Adaptation of Deep Models with Hypernetworks
May 31, 2022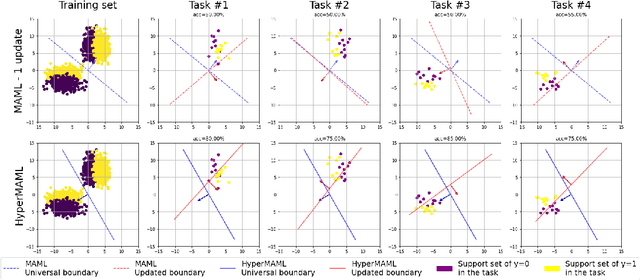
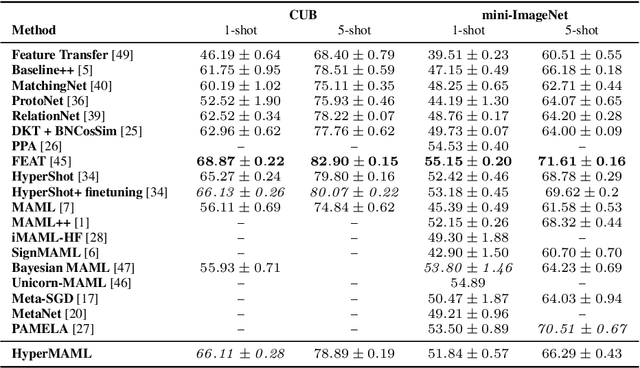

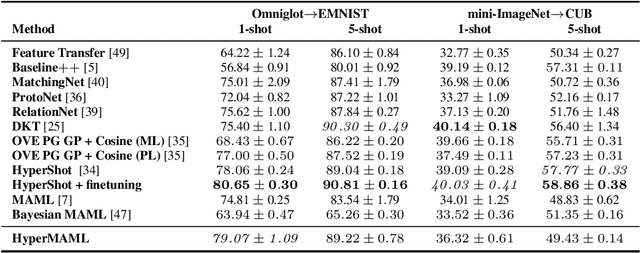
The aim of Few-Shot learning methods is to train models which can easily adapt to previously unseen tasks, based on small amounts of data. One of the most popular and elegant Few-Shot learning approaches is Model-Agnostic Meta-Learning (MAML). The main idea behind this method is to learn the general weights of the meta-model, which are further adapted to specific problems in a small number of gradient steps. However, the model's main limitation lies in the fact that the update procedure is realized by gradient-based optimisation. In consequence, MAML cannot always modify weights to the essential level in one or even a few gradient iterations. On the other hand, using many gradient steps results in a complex and time-consuming optimization procedure, which is hard to train in practice, and may lead to overfitting. In this paper, we propose HyperMAML, a novel generalization of MAML, where the training of the update procedure is also part of the model. Namely, in HyperMAML, instead of updating the weights with gradient descent, we use for this purpose a trainable Hypernetwork. Consequently, in this framework, the model can generate significant updates whose range is not limited to a fixed number of gradient steps. Experiments show that HyperMAML consistently outperforms MAML and performs comparably to other state-of-the-art techniques in a number of standard Few-Shot learning benchmarks.
ICA based on Split Generalized Gaussian
Feb 14, 2018
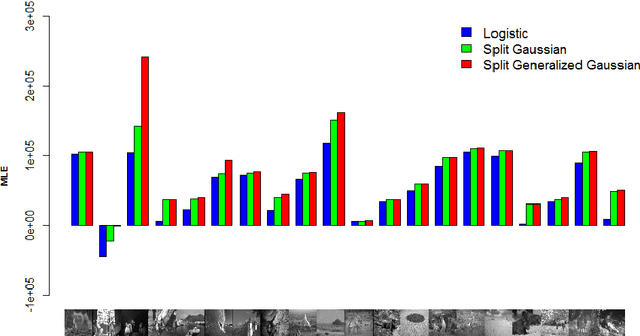
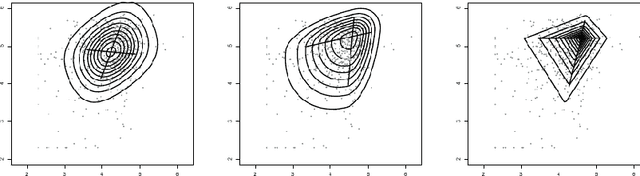

Independent Component Analysis (ICA) - one of the basic tools in data analysis - aims to find a coordinate system in which the components of the data are independent. Most popular ICA methods use kurtosis as a metric of non-Gaussianity to maximize, such as FastICA and JADE. However, their assumption of fourth-order moment (kurtosis) may not always be satisfied in practice. One of the possible solution is to use third-order moment (skewness) instead of kurtosis, which was applied in $ICA_{SG}$ and EcoICA. In this paper we present a competitive approach to ICA based on the Split Generalized Gaussian distribution (SGGD), which is well adapted to heavy-tailed as well as asymmetric data. Consequently, we obtain a method which works better than the classical approaches, in both cases: heavy tails and non-symmetric data. \end{abstract}
Active Function Cross-Entropy Clustering
Feb 06, 2015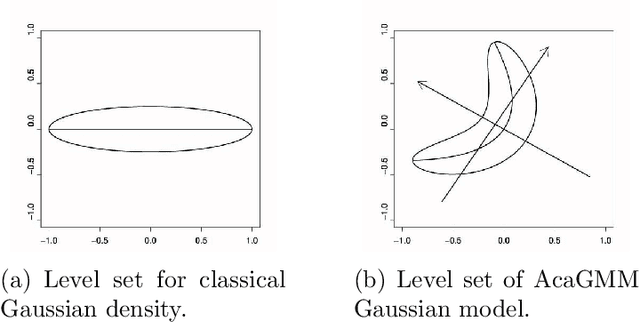
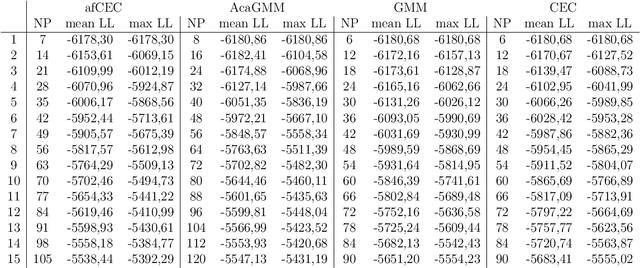
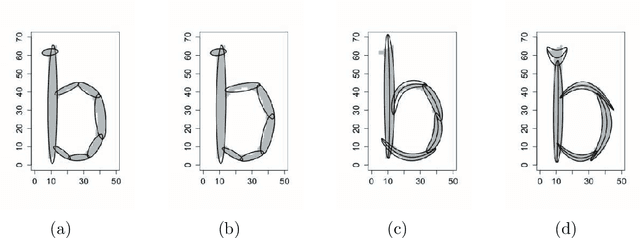
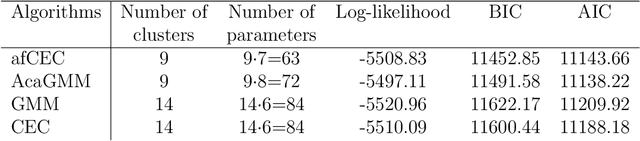
Gaussian Mixture Models (GMM) have found many applications in density estimation and data clustering. However, the model does not adapt well to curved and strongly nonlinear data. Recently there appeared an improvement called AcaGMM (Active curve axis Gaussian Mixture Model), which fits Gaussians along curves using an EM-like (Expectation Maximization) approach. Using the ideas standing behind AcaGMM, we build an alternative active function model of clustering, which has some advantages over AcaGMM. In particular it is naturally defined in arbitrary dimensions and enables an easy adaptation to clustering of complicated datasets along the predefined family of functions. Moreover, it does not need external methods to determine the number of clusters as it automatically reduces the number of groups on-line.