 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrifting Features: Detection and evaluation in the context of automatic RRLs identification in VVV
May 23, 2021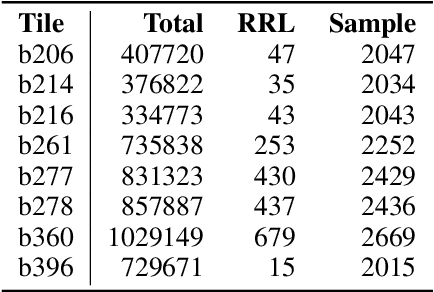
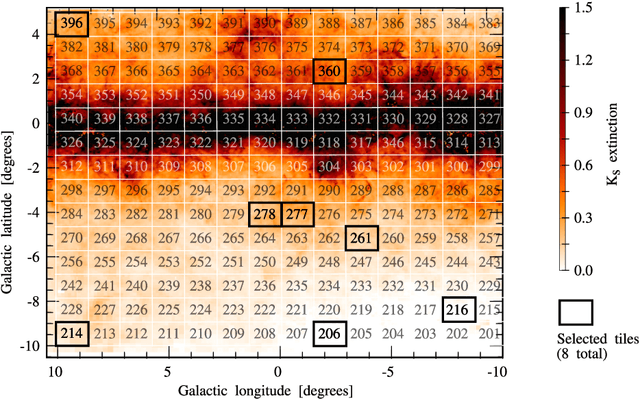
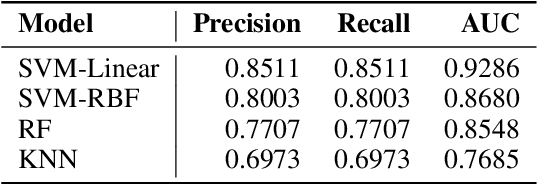
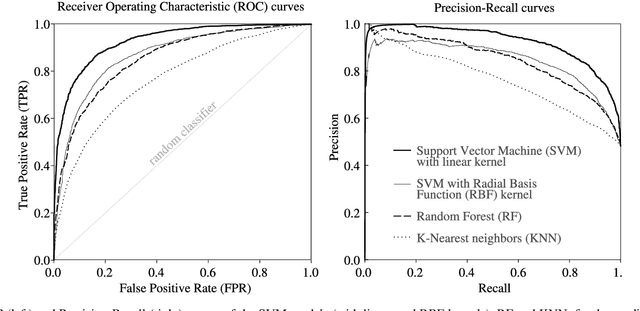
As most of the modern astronomical sky surveys produce data faster than humans can analyze it, Machine Learning (ML) has become a central tool in Astronomy. Modern ML methods can be characterized as highly resistant to some experimental errors. However, small changes on the data over long distances or long periods of time, which cannot be easily detected by statistical methods, can be harmful to these methods. We develop a new strategy to cope with this problem, also using ML methods in an innovative way, to identify these potentially harmful features. We introduce and discuss the notion of Drifting Features, related with small changes in the properties as measured in the data features. We use the identification of RRLs in VVV based on an earlier work and introduce a method for detecting Drifting Features. Our method forces a classifier to learn the tile of origin of diverse sources (mostly stellar 'point sources'), and select the features more relevant to the task of finding candidates to Drifting Features. We show that this method can efficiently identify a reduced set of features that contains useful information about the tile of origin of the sources. For our particular example of detecting RRLs in VVV, we find that Drifting Features are mostly related to color indices. On the other hand, we show that, even if we have a clear set of Drifting Features in our problem, they are mostly insensitive to the identification of RRLs. Drifting Features can be efficiently identified using ML methods. However, in our example, removing Drifting Features does not improve the identification of RRLs.
Neural network ensembles: Evaluation of aggregation algorithms
Feb 01, 2005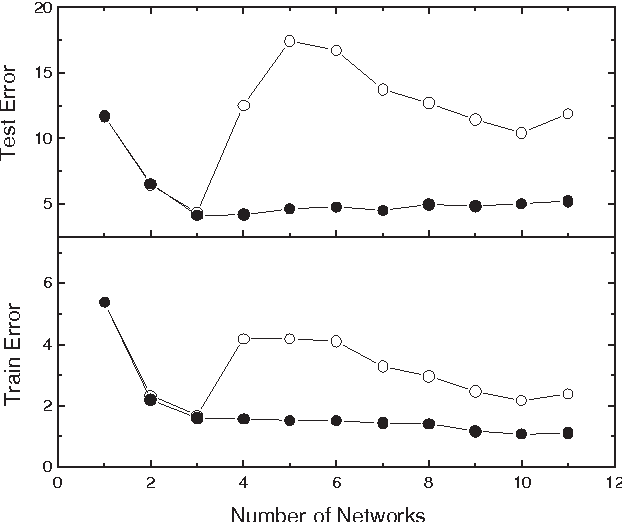
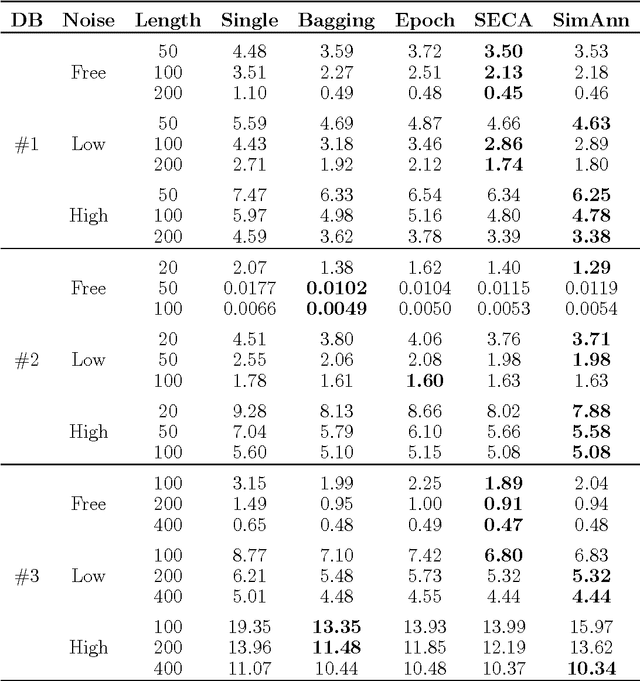
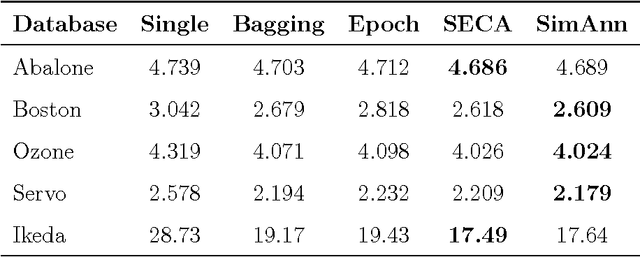
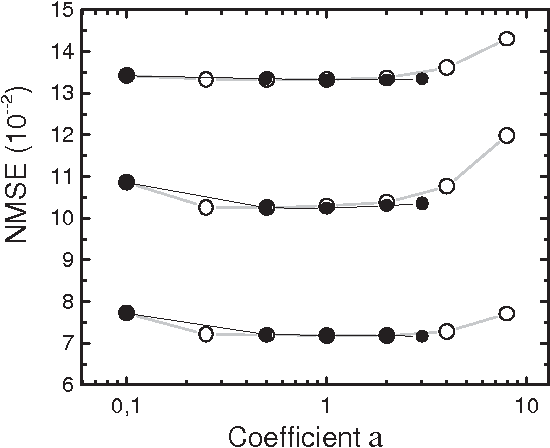
Ensembles of artificial neural networks show improved generalization capabilities that outperform those of single networks. However, for aggregation to be effective, the individual networks must be as accurate and diverse as possible. An important problem is, then, how to tune the aggregate members in order to have an optimal compromise between these two conflicting conditions. We present here an extensive evaluation of several algorithms for ensemble construction, including new proposals and comparing them with standard methods in the literature. We also discuss a potential problem with sequential aggregation algorithms: the non-frequent but damaging selection through their heuristics of particularly bad ensemble members. We introduce modified algorithms that cope with this problem by allowing individual weighting of aggregate members. Our algorithms and their weighted modifications are favorably tested against other methods in the literature, producing a sensible improvement in performance on most of the standard statistical databases used as benchmarks.