 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Single-Sample Polylogarithmic Regret Bound for Nonstationary Online Linear Programming
Mar 15, 2026We study nonstationary Online Linear Programming (OLP), where $n$ orders arrive sequentially with reward-resource consumption pairs that form a sequence of independent, but not necessarily identically distributed, random vectors. At the beginning of the planning horizon, the decision-maker is provided with a resource endowment that is sufficient to fulfill a significant portion of the requests. The decision-maker seeks to maximize the expected total reward by making immediate and irrevocable acceptance or rejection decisions for each order, subject to this resource endowment. We focus on the challenging single-sample setting, where only one sample from each of the $n$ distributions is available at the start of the planning horizon. We propose a novel re-solving algorithm that integrates a dynamic programming perspective with the dual-based frameworks traditionally employed in stationary environments. In the large-resource regime, where the resource endowment scales linearly with the number of orders, we prove that our algorithm achieves $O((\log n)^2)$ regret across a broad class of nonstationary distribution sequences. Our results demonstrate that polylogarithmic regret is attainable even under significant environmental shifts and minimal data availability, bridging the gap between stationary OLP and more volatile real-world resource allocation problems.
Choice-Model-Assisted Q-learning for Delayed-Feedback Revenue Management
Feb 02, 2026We study reinforcement learning for revenue management with delayed feedback, where a substantial fraction of value is determined by customer cancellations and modifications observed days after booking. We propose \emph{choice-model-assisted RL}: a calibrated discrete choice model is used as a fixed partial world model to impute the delayed component of the learning target at decision time. In the fixed-model deployment regime, we prove that tabular Q-learning with model-imputed targets converges to an $O(\varepsilon/(1-γ))$ neighborhood of the optimal Q-function, where $\varepsilon$ summarizes partial-model error, with an additional $O(t^{-1/2})$ sampling term. Experiments in a simulator calibrated from 61{,}619 hotel bookings (1{,}088 independent runs) show: (i) no statistically detectable difference from a maturity-buffer DQN baseline in stationary settings; (ii) positive effects under in-family parameter shifts, with significant gains in 5 of 10 shift scenarios after Holm--Bonferroni correction (up to 12.4\%); and (iii) consistent degradation under structural misspecification, where the choice model assumptions are violated (1.4--2.6\% lower revenue). These results characterize when partial behavioral models improve robustness under shift and when they introduce harmful bias.
Online Regenerative Learning
Oct 02, 2022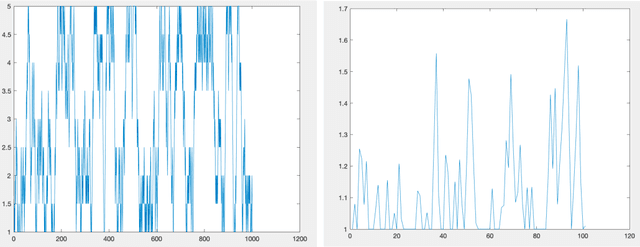

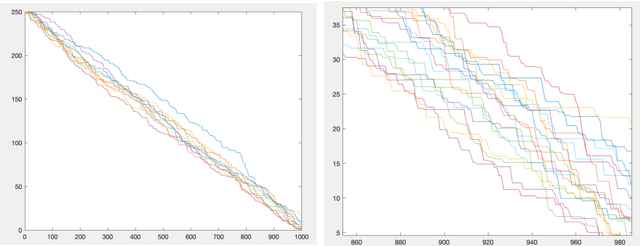
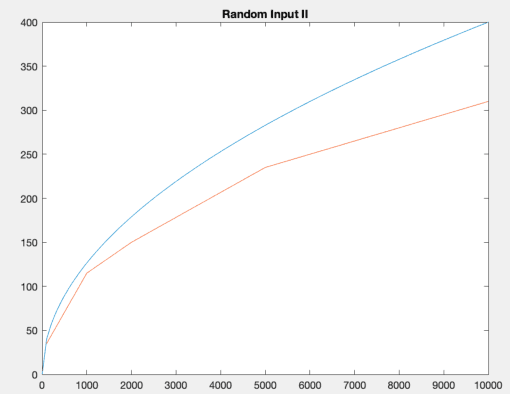
We study a type of Online Linear Programming (OLP) problem that maximizes the objective function with stochastic inputs. The performance of various algorithms that analyze this type of OLP is well studied when the stochastic inputs follow some i.i.d distribution. The two central questions to ask are: (i) can the algorithms achieve the same efficiency if the stochastic inputs are not i.i.d but still stationary, and (ii) how can we modify our algorithms if we know the stochastic inputs are trendy, hence not stationary. We answer the first question by analyzing a regenerative type of input and show the regrets of two popular algorithms are bounded by the same orders as their i.i.d counterparts. We discuss the second question in the context of linearly growing inputs and propose a trend-adaptive algorithm. We provide numerical simulations to illustrate the performance of our algorithms under both regenerative and trendy inputs.