 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoto-Realistic Video Prediction on Natural Videos of Largely Changing Frames
Mar 19, 2020
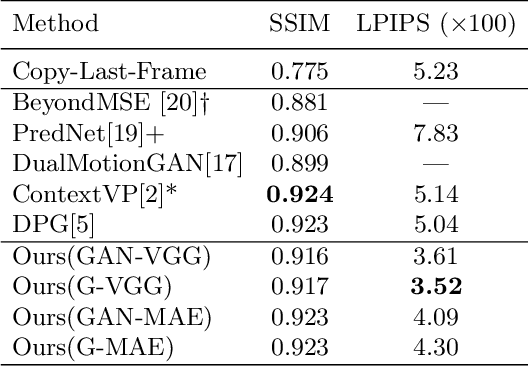
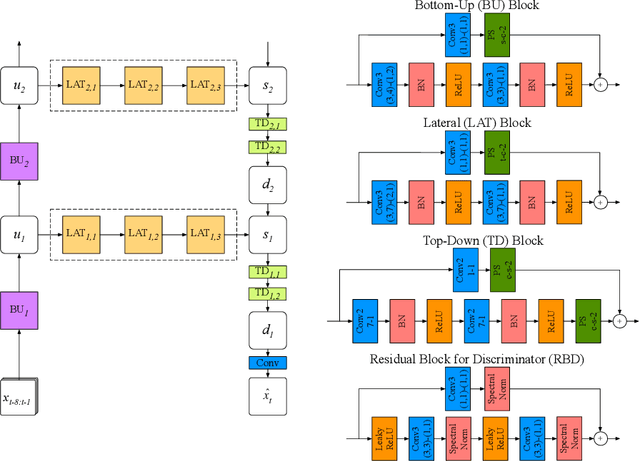

Recent advances in deep learning have significantly improved performance of video prediction. However, state-of-the-art methods still suffer from blurriness and distortions in their future predictions, especially when there are large motions between frames. To address these issues, we propose a deep residual network with the hierarchical architecture where each layer makes a prediction of future state at different spatial resolution, and these predictions of different layers are merged via top-down connections to generate future frames. We trained our model with adversarial and perceptual loss functions, and evaluated it on a natural video dataset captured by car-mounted cameras. Our model quantitatively outperforms state-of-the-art baselines in future frame prediction on video sequences of both largely and slightly changing frames. Furthermore, our model generates future frames with finer details and textures that are perceptually more realistic than the baselines, especially under fast camera motions.
Neural Trajectory Analysis of Recurrent Neural Network In Handwriting Synthesis
Apr 13, 2018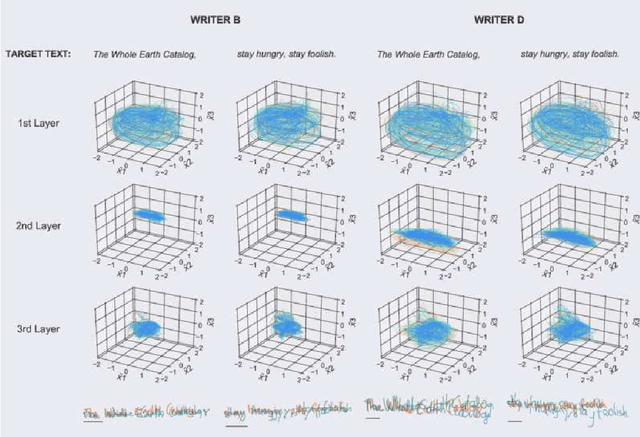
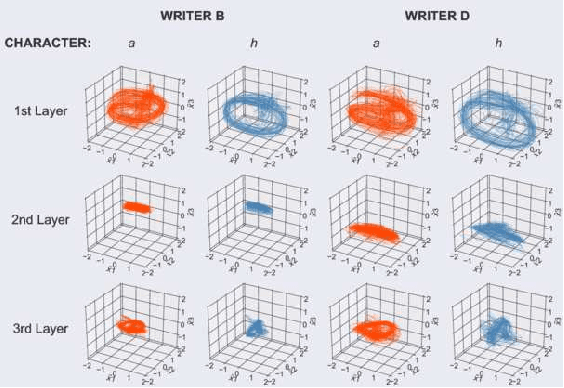
Recurrent neural networks (RNNs) are capable of learning to generate highly realistic, online handwritings in a wide variety of styles from a given text sequence. Furthermore, the networks can generate handwritings in the style of a particular writer when the network states are primed with a real sequence of pen movements from the writer. However, how populations of neurons in the RNN collectively achieve such performance still remains poorly understood. To tackle this problem, we investigated learned representations in RNNs by extracting low-dimensional, neural trajectories that summarize the activity of a population of neurons in the network during individual syntheses of handwritings. The neural trajectories show that different writing styles are encoded in different subspaces inside an internal space of the network. Within each subspace, different characters of the same style are represented as different state dynamics. These results demonstrate the effectiveness of analyzing the neural trajectory for intuitive understanding of how the RNNs work.