 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Filters with Certainty
Jun 22, 2026Hash-based data structures such as Bloom filters are widely used in network systems for tasks including caching, anomaly detection, and machine learning pipelines. They typically provide binary indications of whether an element belongs to a set of interest, e.g., the contents of a cache. When uncertainty arises due to hash collisions, a positive indication is returned to avoid false negatives. We argue that the certainty associated with such indications can itself be useful information. This work focuses on Counting Bloom Filters (CBFs), a Bloom-filter variant that maintains counters rather than bits. Besides supporting insertions and deletions, these counters provide additional information that can be used to estimate the certainty of positive membership indications. We show how this certainty signal can be exploited in architectures that combine Bloom Filters with machine learning (ML) models.
A Computational Approach to Packet Classification
Feb 10, 2020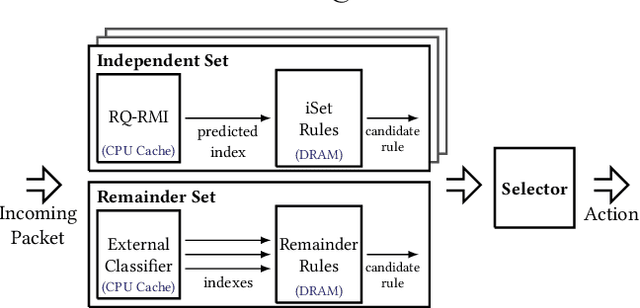

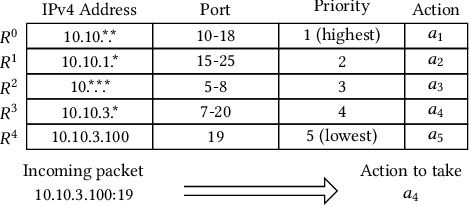
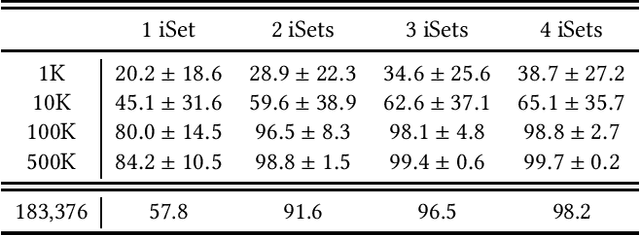
Multi-field packet classification is a crucial component in modern software-defined data center networks. To achieve high throughput and low latency, state-of-the-art algorithms strive to fit the rule lookup data structures into on-die caches; however, they do not scale well with the number of rules. We present a novel approach, NuevoMatch, which improves the memory scaling of existing methods. A new data structure, Range Query Recursive Model Index (RQ-RMI), is the key component that enables NuevoMatch to replace most of the accesses to main memory with model inference computations. We describe an efficient training algorithm which guarantees the correctness of the RQ-RMI-based classification. The use of RQ-RMI allows the packet rules to be compressed into model weights that fit into the hardware cache and takes advantage of the growing support for fast neural network processing in modern CPUs, such as wide vector processing engines, achieving a rate of tens of nanoseconds per lookup. Our evaluation using 500K multi-field rules from the standard ClassBench benchmark shows a geomean compression factor of 4.9X, 8X, and 82X, and an average performance improvement of 2.7X, 4.4X and 2.6X in latency and 1.3X, 2.2X, and 1.2X in throughput compared to CutSplit, NeuroCuts, and TupleMerge, all state-of-the-art algorithms.