 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSF-Flow: Sound field magnitude estimation via flow matching guided by sparse measurements
May 11, 2026Reconstructing a 3D sound field from sparse microphone measurements is a fundamental yet ill-posed problem, which we address through Acoustic Transfer Function (ATF) magnitude estimation. ATF magnitude encapsulates key perceptual and acoustic properties of a physical space with applications in room characterization and correction. Although recent generative paradigms such as Flow Matching (FM) have achieved state-of-the-art performance in speech and music generation, their potential in spatial audio remains underexplored. We propose a novel framework for 3D ATF magnitude reconstruction as a guided generation task, with a 3D U-Net conditioned by a permutation-invariant set encoder. This architecture enables reconstruction from an arbitrary number of sparse inputs while leveraging the stable and efficient training properties of FM. Experimental results demonstrate that SF-Flow achieves accurate reconstruction up to \SI{1}{kHz}, trains substantially faster than the autoencoder baseline, and improves significantly with dataset size.
Modal Estimation on a Warped Frequency Axis for Linear System Modeling
Feb 22, 2022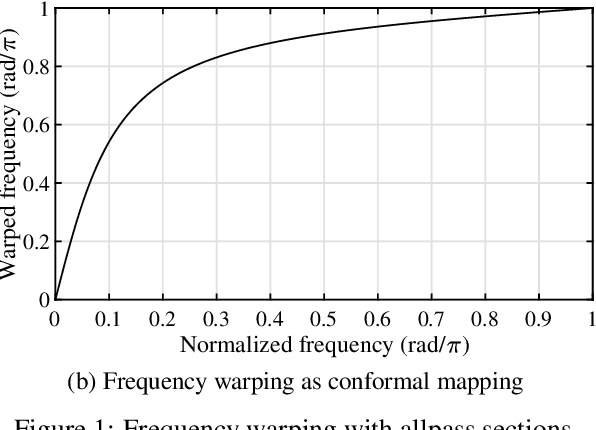
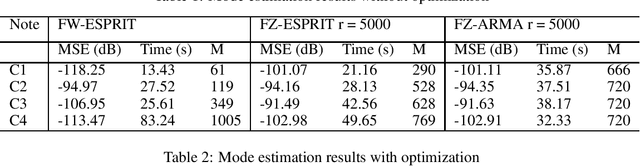
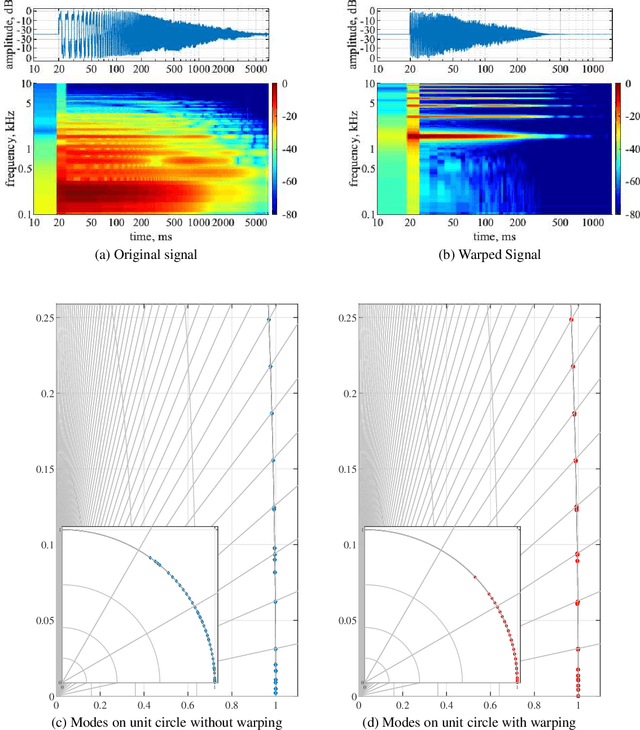
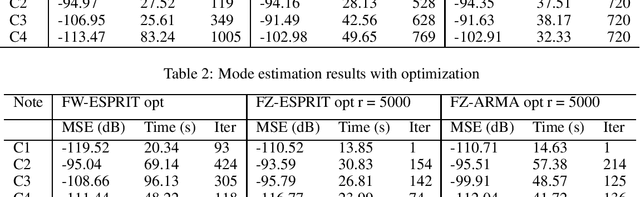
Linear systems such as room acoustics and string oscillations may be modeled as the sum of mode responses, each characterized by a frequency, damping and amplitude. Here, we consider finding the mode parameters from impulse response measurements, and estimate the mode frequencies and decay rates as the generalized eigenvalues of Hankel matrices of system response samples, similar to ESPRIT. For greater resolution at low frequencies, such as desired in room acoustics and musical instrument modeling, the estimation is done on a warped frequency axis. The approach has the benefit of selecting the number of modes to achieve a desired fidelity to the measured impulse response. An optimization to further refine the frequency and damping parameters is presented. The method is used to model coupled piano strings and room impulse responses, with its performance comparing favorably to FZ-ARMA.