 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised K-modal Styled Content Generation
Jan 10, 2020

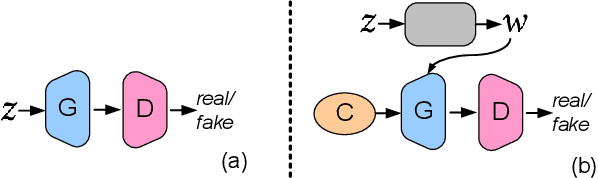

The emergence of generative models based on deep neural networks has recently enabled the automatic generation of massive amounts of graphical content, both in 2D and in 3D. Generative Adversarial Networks (GANs) and style control mechanisms, such as Adaptive Instance Normalization (AdaIN), have proved particularly effective in this context, culminating in the state-of-the-art StyleGAN architecture. While such models are able to learn diverse distributions, provided a sufficiently large training set, they are not well-suited for scenarios where the distribution of the training data exhibits a multi-modal behavior. In such cases, reshaping a uniform or normal distribution over the latent space into a complex multi-modal distribution in the data domain is challenging, and the quality of the generated samples may suffer as a result. Furthermore, the different modes are entangled with the other attributes of the data, and thus, mode transitions cannot be well controlled via continuous style parameters. In this paper, we introduce uMM-GAN, a novel architecture designed to better model such multi-modal distributions, in an unsupervised fashion. Building upon the StyleGAN architecture, our network learns multiple modes, in a completely unsupervised manner, and combines them using a set of learned weights. Quite strikingly, we show that this approach is capable of homing onto the natural modes in the training set, and effectively approximates the complex distribution as a superposition of multiple simple ones. We demonstrate that uMM-GAN copes better with multi-modal distributions, while at the same time disentangling between the modes and their style, thereby providing an independent degree of control over the generated content.
XNet: GAN Latent Space Constraints
Jan 14, 2019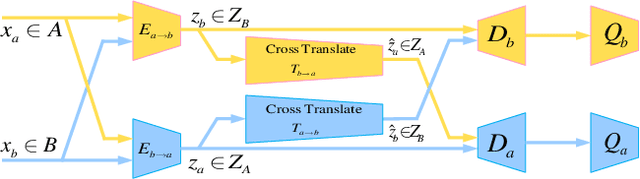

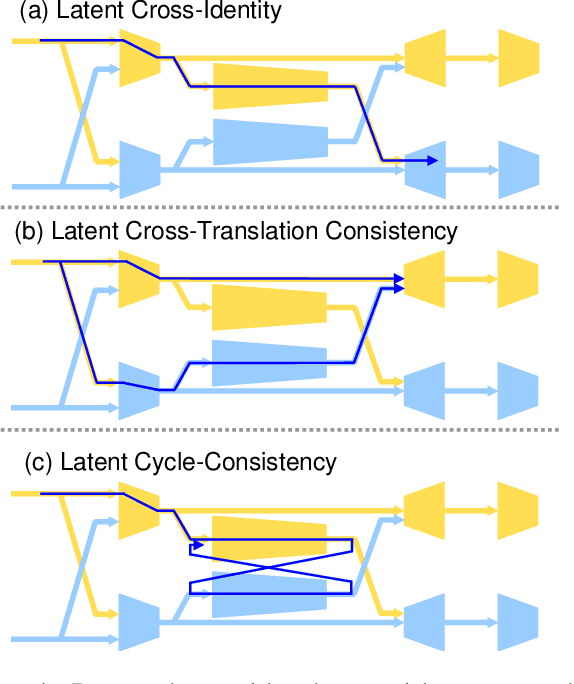

Recent GAN-based architectures have been able to deliver impressive performance on the general task of image-to-image translation. In particular, it was shown that a wide variety of image translation operators may be learned from two image sets, containing images from two different domains, without establishing an explicit pairing between the images. This was made possible by introducing clever regularizers to overcome the under-constrained nature of the unpaired translation problem. In this work, we introduce a novel architecture for unpaired image translation, and explore several new regularizers enabled by it. Specifically, our architecture comprises a pair of GANs, as well as a pair of translators between their respective latent spaces. These cross-translators enable us to impose several regularizing constraints on the learnt image translation operator, collectively referred to as latent cross-consistency. Our results show that our proposed architecture and latent cross-consistency constraints are able to outperform the existing state-of-the-art on a wide variety of image translation tasks.