 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical Hyper-Parameters: No Random, No Cry
Jun 10, 2017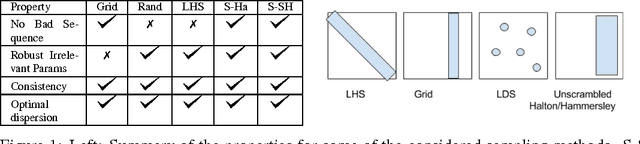
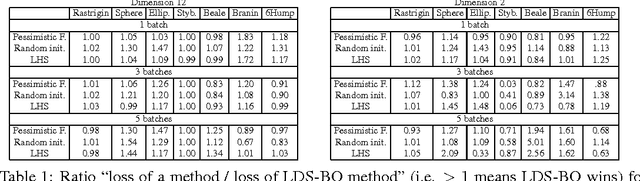

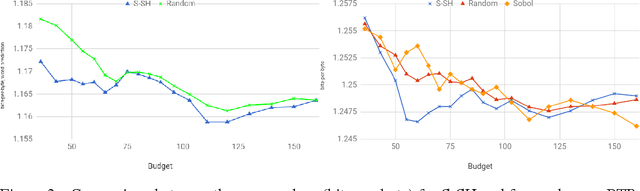
The selection of hyper-parameters is critical in Deep Learning. Because of the long training time of complex models and the availability of compute resources in the cloud, "one-shot" optimization schemes - where the sets of hyper-parameters are selected in advance (e.g. on a grid or in a random manner) and the training is executed in parallel - are commonly used. It is known that grid search is sub-optimal, especially when only a few critical parameters matter, and suggest to use random search instead. Yet, random search can be "unlucky" and produce sets of values that leave some part of the domain unexplored. Quasi-random methods, such as Low Discrepancy Sequences (LDS) avoid these issues. We show that such methods have theoretical properties that make them appealing for performing hyperparameter search, and demonstrate that, when applied to the selection of hyperparameters of complex Deep Learning models (such as state-of-the-art LSTM language models and image classification models), they yield suitable hyperparameters values with much fewer runs than random search. We propose a particularly simple LDS method which can be used as a drop-in replacement for grid or random search in any Deep Learning pipeline, both as a fully one-shot hyperparameter search or as an initializer in iterative batch optimization.
Better Text Understanding Through Image-To-Text Transfer
May 26, 2017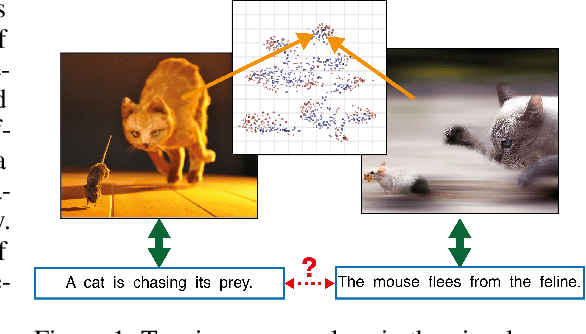
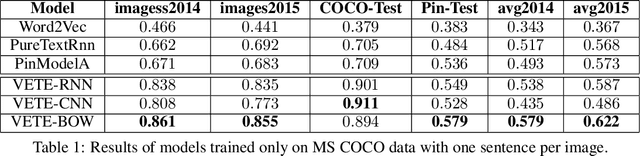
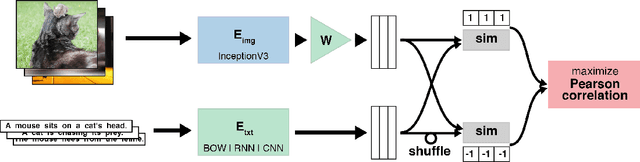
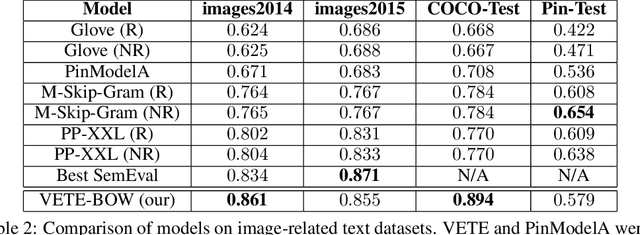
Generic text embeddings are successfully used in a variety of tasks. However, they are often learnt by capturing the co-occurrence structure from pure text corpora, resulting in limitations of their ability to generalize. In this paper, we explore models that incorporate visual information into the text representation. Based on comprehensive ablation studies, we propose a conceptually simple, yet well performing architecture. It outperforms previous multimodal approaches on a set of well established benchmarks. We also improve the state-of-the-art results for image-related text datasets, using orders of magnitude less data.
Approximation and Convergence Properties of Generative Adversarial Learning
May 24, 2017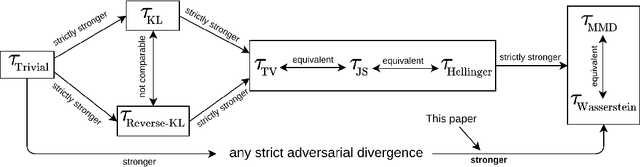
Generative adversarial networks (GAN) approximate a target data distribution by jointly optimizing an objective function through a "two-player game" between a generator and a discriminator. Despite their empirical success, however, two very basic questions on how well they can approximate the target distribution remain unanswered. First, it is not known how restricting the discriminator family affects the approximation quality. Second, while a number of different objective functions have been proposed, we do not understand when convergence to the global minima of the objective function leads to convergence to the target distribution under various notions of distributional convergence. In this paper, we address these questions in a broad and unified setting by defining a notion of adversarial divergences that includes a number of recently proposed objective functions. We show that if the objective function is an adversarial divergence with some additional conditions, then using a restricted discriminator family has a moment-matching effect. Additionally, we show that for objective functions that are strict adversarial divergences, convergence in the objective function implies weak convergence, thus generalizing previous results.
AdaGAN: Boosting Generative Models
May 24, 2017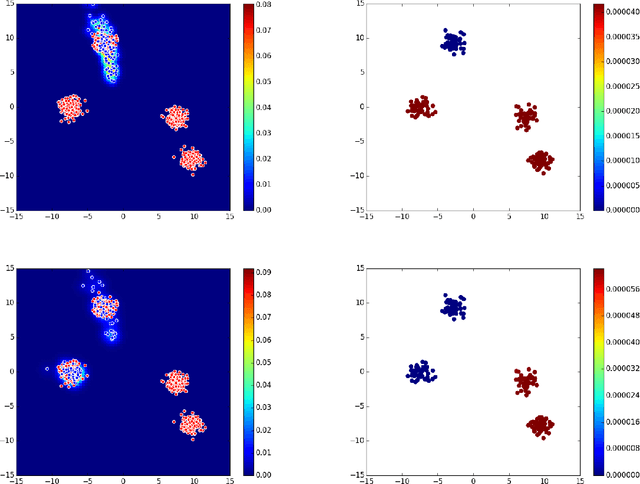
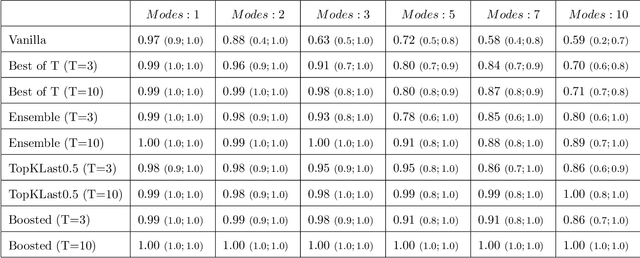
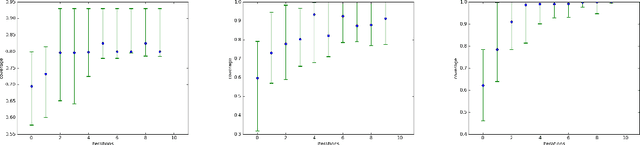
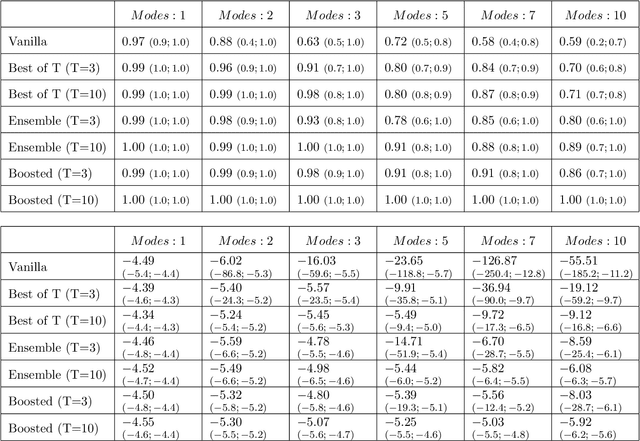
Generative Adversarial Networks (GAN) (Goodfellow et al., 2014) are an effective method for training generative models of complex data such as natural images. However, they are notoriously hard to train and can suffer from the problem of missing modes where the model is not able to produce examples in certain regions of the space. We propose an iterative procedure, called AdaGAN, where at every step we add a new component into a mixture model by running a GAN algorithm on a reweighted sample. This is inspired by boosting algorithms, where many potentially weak individual predictors are greedily aggregated to form a strong composite predictor. We prove that such an incremental procedure leads to convergence to the true distribution in a finite number of steps if each step is optimal, and convergence at an exponential rate otherwise. We also illustrate experimentally that this procedure addresses the problem of missing modes.
From optimal transport to generative modeling: the VEGAN cookbook
May 22, 2017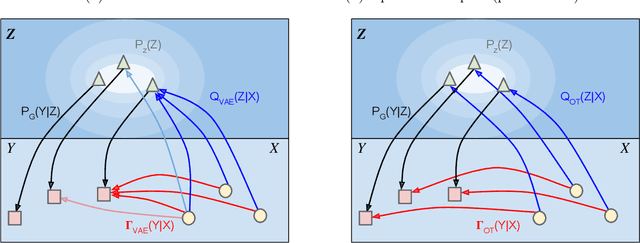
We study unsupervised generative modeling in terms of the optimal transport (OT) problem between true (but unknown) data distribution $P_X$ and the latent variable model distribution $P_G$. We show that the OT problem can be equivalently written in terms of probabilistic encoders, which are constrained to match the posterior and prior distributions over the latent space. When relaxed, this constrained optimization problem leads to a penalized optimal transport (POT) objective, which can be efficiently minimized using stochastic gradient descent by sampling from $P_X$ and $P_G$. We show that POT for the 2-Wasserstein distance coincides with the objective heuristically employed in adversarial auto-encoders (AAE) (Makhzani et al., 2016), which provides the first theoretical justification for AAEs known to the authors. We also compare POT to other popular techniques like variational auto-encoders (VAE) (Kingma and Welling, 2014). Our theoretical results include (a) a better understanding of the commonly observed blurriness of images generated by VAEs, and (b) establishing duality between Wasserstein GAN (Arjovsky and Bottou, 2017) and POT for the 1-Wasserstein distance.