 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology-Driven Processing of Transdisciplinary Domain Knowledge
Nov 01, 2023The monograph discusses certain aspects of modern real-world problems facing humanity, which are much more challenging than scientific ones. Modern science is unable to solve them in a fundamental way. Vernadsky's noosphere thesis, in fact, appeals to the scientific worldview that needs to be built in a way that overcomes the interdisciplinary barriers and increases the effectiveness of interdisciplinary interaction and modern science overall. We are talking about the general transdisciplinary knowledge. In world practice, there is still no systematic methodology and a specific form of generally accepted valid scientific theory that would provide transdisciplinary knowledge. Non-linear interdisciplinary interaction is the standard of evolution of modern science. At the same time, a new transdisciplinary theory (domain of scientific research) is being de facto created and the process is repeated many times: from an individual or group of disciplines, through interdisciplinary interaction, in a direction that brings us closer to creating a holistic general scientific worldview.
OntoChatGPT Information System: Ontology-Driven Structured Prompts for ChatGPT Meta-Learning
Jul 11, 2023This research presents a comprehensive methodology for utilizing an ontology-driven structured prompts system in interplay with ChatGPT, a widely used large language model (LLM). The study develops formal models, both information and functional, and establishes the methodological foundations for integrating ontology-driven prompts with ChatGPT's meta-learning capabilities. The resulting productive triad comprises the methodological foundations, advanced information technology, and the OntoChatGPT system, which collectively enhance the effectiveness and performance of chatbot systems. The implementation of this technology is demonstrated using the Ukrainian language within the domain of rehabilitation. By applying the proposed methodology, the OntoChatGPT system effectively extracts entities from contexts, classifies them, and generates relevant responses. The study highlights the versatility of the methodology, emphasizing its applicability not only to ChatGPT but also to other chatbot systems based on LLMs, such as Google's Bard utilizing the PaLM 2 LLM. The underlying principles of meta-learning, structured prompts, and ontology-driven information retrieval form the core of the proposed methodology, enabling their adaptation and utilization in various LLM-based systems. This versatile approach opens up new possibilities for NLP and dialogue systems, empowering developers to enhance the performance and functionality of chatbot systems across different domains and languages.
* 14 pages, 1 figure. Published. International Journal of Computing, 22(2), 170-183. https://doi.org/10.47839/ijc.22.2.3086
Distributional semantic modeling: a revised technique to train term/word vector space models applying the ontology-related approach
Mar 06, 2020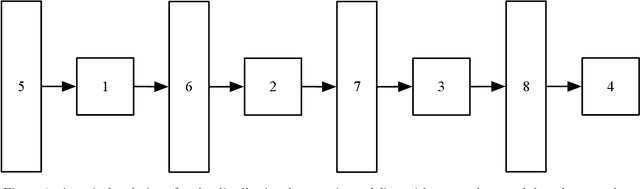
We design a new technique for the distributional semantic modeling with a neural network-based approach to learn distributed term representations (or term embeddings) - term vector space models as a result, inspired by the recent ontology-related approach (using different types of contextual knowledge such as syntactic knowledge, terminological knowledge, semantic knowledge, etc.) to the identification of terms (term extraction) and relations between them (relation extraction) called semantic pre-processing technology - SPT. Our method relies on automatic term extraction from the natural language texts and subsequent formation of the problem-oriented or application-oriented (also deeply annotated) text corpora where the fundamental entity is the term (includes non-compositional and compositional terms). This gives us an opportunity to changeover from distributed word representations (or word embeddings) to distributed term representations (or term embeddings). This transition will allow to generate more accurate semantic maps of different subject domains (also, of relations between input terms - it is useful to explore clusters and oppositions, or to test your hypotheses about them). The semantic map can be represented as a graph using Vec2graph - a Python library for visualizing word embeddings (term embeddings in our case) as dynamic and interactive graphs. The Vec2graph library coupled with term embeddings will not only improve accuracy in solving standard NLP tasks, but also update the conventional concept of automated ontology development. The main practical result of our work is the development kit (set of toolkits represented as web service APIs and web application), which provides all necessary routines for the basic linguistic pre-processing and the semantic pre-processing of the natural language texts in Ukrainian for future training of term vector space models.