 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracle Complexity in Nonsmooth Nonconvex Optimization
Apr 14, 2021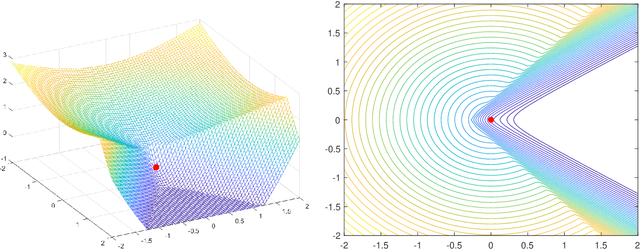
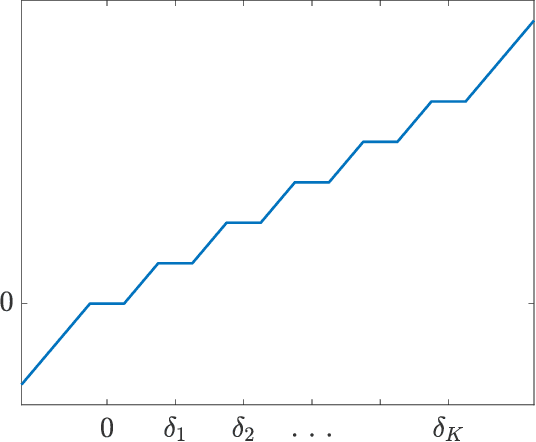
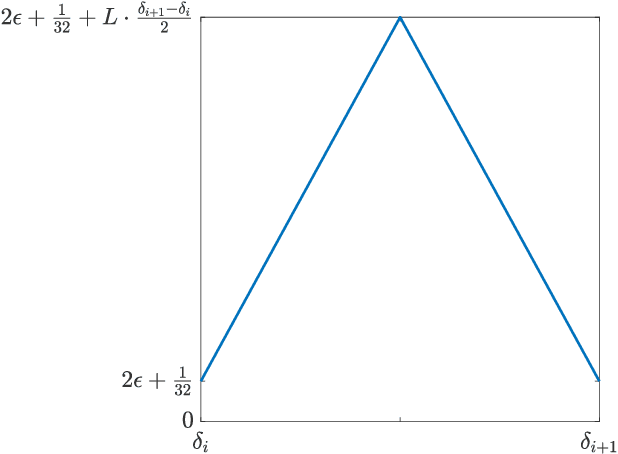
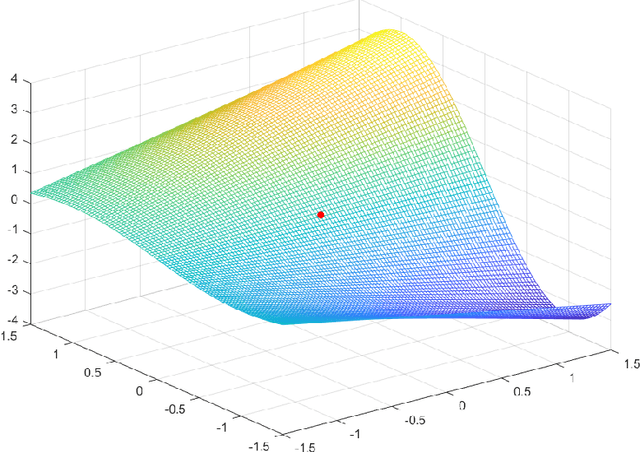
It is well-known that given a smooth, bounded-from-below, and possibly nonconvex function, standard gradient-based methods can find $\epsilon$-stationary points (with gradient norm less than $\epsilon$) in $\mathcal{O}(1/\epsilon^2)$ iterations. However, many important nonconvex optimization problems, such as those associated with training modern neural networks, are inherently not smooth, making these results inapplicable. In this paper, we study nonsmooth nonconvex optimization from an oracle complexity viewpoint, where the algorithm is assumed to be given access only to local information about the function at various points. We provide two main results (under mild assumptions): First, we consider the problem of getting near $\epsilon$-stationary points. This is perhaps the most natural relaxation of finding $\epsilon$-stationary points, which is impossible in the nonsmooth nonconvex case. We prove that this relaxed goal cannot be achieved efficiently, for any distance and $\epsilon$ smaller than some constants. Our second result deals with the possibility of tackling nonsmooth nonconvex optimization by reduction to smooth optimization: Namely, applying smooth optimization methods on a smooth approximation of the objective function. For this approach, we prove an inherent trade-off between oracle complexity and smoothness: On the one hand, smoothing a nonsmooth nonconvex function can be done very efficiently (e.g., by randomized smoothing), but with dimension-dependent factors in the smoothness parameter, which can strongly affect iteration complexity when plugging into standard smooth optimization methods. On the other hand, these dimension factors can be eliminated with suitable smoothing methods, but only by making the oracle complexity of the smoothing process exponentially large.
Size and Depth Separation in Approximating Natural Functions with Neural Networks
Feb 03, 2021When studying the expressive power of neural networks, a main challenge is to understand how the size and depth of the network affect its ability to approximate real functions. However, not all functions are interesting from a practical viewpoint: functions of interest usually have a polynomially-bounded Lipschitz constant, and can be computed efficiently. We call functions that satisfy these conditions "natural", and explore the benefits of size and depth for approximation of natural functions with ReLU networks. As we show, this problem is more challenging than the corresponding problem for non-natural functions. We give barriers to showing depth-lower-bounds: Proving existence of a natural function that cannot be approximated by polynomial-size networks of depth $4$ would settle longstanding open problems in computational complexity. It implies that beyond depth $4$ there is a barrier to showing depth-separation for natural functions, even between networks of constant depth and networks of nonconstant depth. We also study size-separation, namely, whether there are natural functions that can be approximated with networks of size $O(s(d))$, but not with networks of size $O(s'(d))$. We show a complexity-theoretic barrier to proving such results beyond size $O(d\log^2(d))$, but also show an explicit natural function, that can be approximated with networks of size $O(d)$ and not with networks of size $o(d/\log d)$. For approximation in $L_\infty$ we achieve such separation already between size $O(d)$ and size $o(d)$. Moreover, we show superpolynomial size lower bounds and barriers to such lower bounds, depending on the assumptions on the function. Our size-separation results rely on an analysis of size lower bounds for Boolean functions, which is of independent interest: We show linear size lower bounds for computing explicit Boolean functions with neural networks and threshold circuits.
The Min-Max Complexity of Distributed Stochastic Convex Optimization with Intermittent Communication
Feb 02, 2021We resolve the min-max complexity of distributed stochastic convex optimization (up to a log factor) in the intermittent communication setting, where $M$ machines work in parallel over the course of $R$ rounds of communication to optimize the objective, and during each round of communication, each machine may sequentially compute $K$ stochastic gradient estimates. We present a novel lower bound with a matching upper bound that establishes an optimal algorithm.
The Connection Between Approximation, Depth Separation and Learnability in Neural Networks
Jan 31, 2021Several recent works have shown separation results between deep neural networks, and hypothesis classes with inferior approximation capacity such as shallow networks or kernel classes. On the other hand, the fact that deep networks can efficiently express a target function does not mean this target function can be learned efficiently by deep neural networks. In this work we study the intricate connection between learnability and approximation capacity. We show that learnability with deep networks of a target function depends on the ability of simpler classes to approximate the target. Specifically, we show that a necessary condition for a function to be learnable by gradient descent on deep neural networks is to be able to approximate the function, at least in a weak sense, with shallow neural networks. We also show that a class of functions can be learned by an efficient statistical query algorithm if and only if it can be approximated in a weak sense by some kernel class. We give several examples of functions which demonstrate depth separation, and conclude that they cannot be efficiently learned, even by a hypothesis class that can efficiently approximate them.
Implicit Regularization in ReLU Networks with the Square Loss
Dec 15, 2020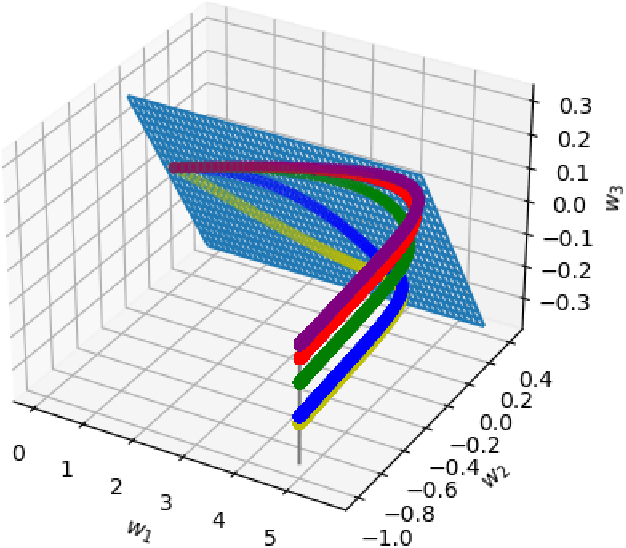
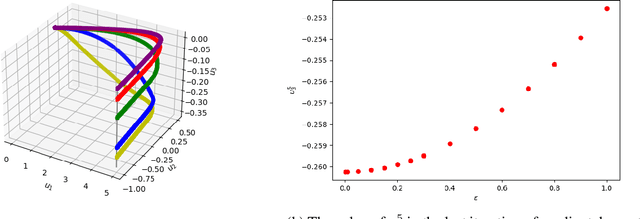
Understanding the implicit regularization (or implicit bias) of gradient descent has recently been a very active research area. However, the implicit regularization in nonlinear neural networks is still poorly understood, especially for regression losses such as the square loss. Perhaps surprisingly, we prove that even for a single ReLU neuron, it is impossible to characterize the implicit regularization with the square loss by any explicit function of the model parameters (although on the positive side, we show it can be characterized approximately). For one hidden-layer networks, we prove a similar result, where in general it is impossible to characterize implicit regularization properties in this manner, except for the "balancedness" property identified in Du et al. [2018]. Our results suggest that a more general framework than the one considered so far may be needed to understand implicit regularization for nonlinear predictors, and provides some clues on what this framework should be.
High-Order Oracle Complexity of Smooth and Strongly Convex Optimization
Oct 13, 2020In this note, we consider the complexity of optimizing a highly smooth (Lipschitz $k$-th order derivative) and strongly convex function, via calls to a $k$-th order oracle which returns the value and first $k$ derivatives of the function at a given point, and where the dimension is unrestricted. Extending the techniques introduced in Arjevani et al. [2019], we prove that the worst-case oracle complexity for any fixed $k$ to optimize the function up to accuracy $\epsilon$ is on the order of $\left(\frac{\mu_k D^{k-1}}{\lambda}\right)^{\frac{2}{3k+1}}+\log\log\left(\frac{1}{\epsilon}\right)$ (up to log factors independent of $\epsilon$), where $\mu_k$ is the Lipschitz constant of the $k$-th derivative, $D$ is the initial distance to the optimum, and $\lambda$ is the strong convexity parameter.
Gradient Methods Never Overfit On Separable Data
Jun 30, 2020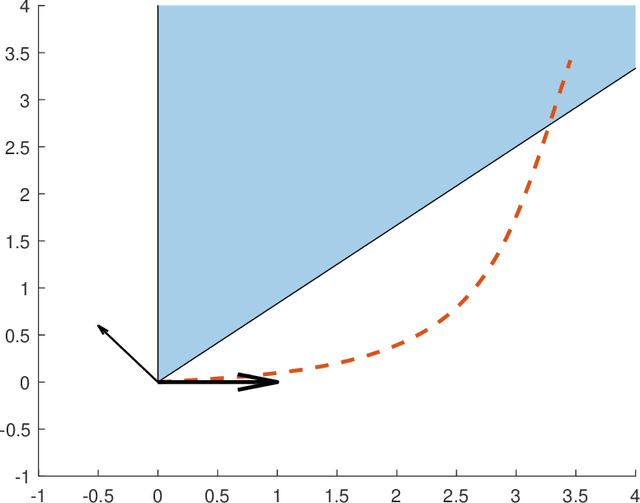
A line of recent works established that when training linear predictors over separable data, using gradient methods and exponentially-tailed losses, the predictors asymptotically converge in direction to the max-margin predictor. As a consequence, the predictors asymptotically do not overfit. However, this does not address the question of whether overfitting might occur non-asymptotically, after some bounded number of iterations. In this paper, we formally show that standard gradient methods (in particular, gradient flow, gradient descent and stochastic gradient descent) never overfit on separable data: If we run these methods for $T$ iterations on a dataset of size $m$, both the empirical risk and the generalization error decrease at an essentially optimal rate of $\tilde{\mathcal{O}}(1/\gamma^2 T)$ up till $T\approx m$, at which point the generalization error remains fixed at an essentially optimal level of $\tilde{\mathcal{O}}(1/\gamma^2 m)$ regardless of how large $T$ is. Along the way, we present non-asymptotic bounds on the number of margin violations over the dataset, and prove their tightness.
Neural Networks with Small Weights and Depth-Separation Barriers
Jun 03, 2020In studying the expressiveness of neural networks, an important question is whether there are functions which can only be approximated by sufficiently deep networks, assuming their size is bounded. However, for constant depths, existing results are limited to depths $2$ and $3$, and achieving results for higher depths has been an important open question. In this paper, we focus on feedforward ReLU networks, and prove fundamental barriers to proving such results beyond depth $4$, by reduction to open problems and natural-proof barriers in circuit complexity. To show this, we study a seemingly unrelated problem of independent interest: Namely, whether there are polynomially-bounded functions which require super-polynomial weights in order to approximate with constant-depth neural networks. We provide a negative and constructive answer to that question, by showing that if a function can be approximated by a polynomially-sized, constant depth $k$ network with arbitrarily large weights, it can also be approximated by a polynomially-sized, depth $3k+3$ network, whose weights are polynomially bounded.
The Effects of Mild Over-parameterization on the Optimization Landscape of Shallow ReLU Neural Networks
Jun 01, 2020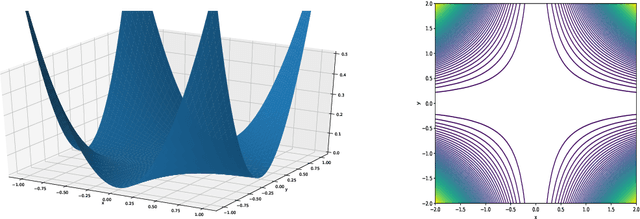
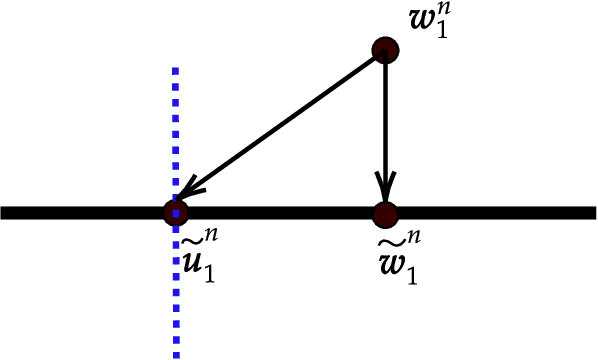
We study the effects of mild over-parameterization on the optimization landscape of a simple ReLU neural network of the form $\mathbf{x}\mapsto\sum_{i=1}^k\max\{0,\mathbf{w}_i^{\top}\mathbf{x}\}$, in a well-studied teacher-student setting where the target values are generated by the same architecture, and when directly optimizing over the population squared loss with respect to Gaussian inputs. We prove that while the objective is strongly convex around the global minima when the teacher and student networks possess the same number of neurons, it is not even \emph{locally convex} after any amount of over-parameterization. Moreover, related desirable properties (e.g., one-point strong convexity and the Polyak-{\L}ojasiewicz condition) also do not hold even locally. On the other hand, we establish that the objective remains one-point strongly convex in \emph{most} directions (suitably defined). For the non-global minima, we prove that adding even just a single neuron will turn a non-global minimum into a saddle point. This holds under some technical conditions which we validate empirically. These results provide a possible explanation for why recovering a global minimum becomes significantly easier when we over-parameterize, even if the amount of over-parameterization is very moderate.
Can We Find Near-Approximately-Stationary Points of Nonsmooth Nonconvex Functions?
Mar 14, 2020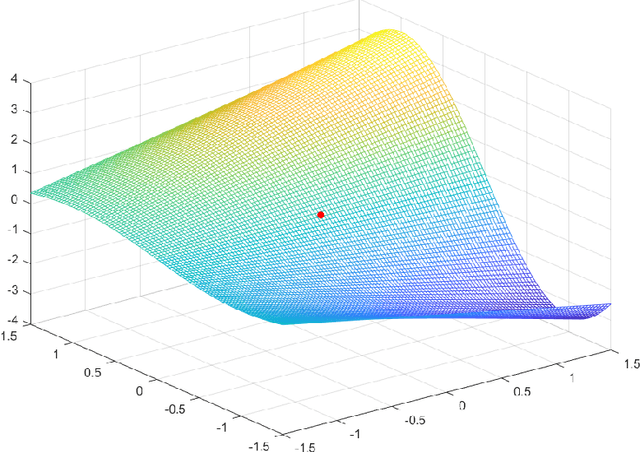
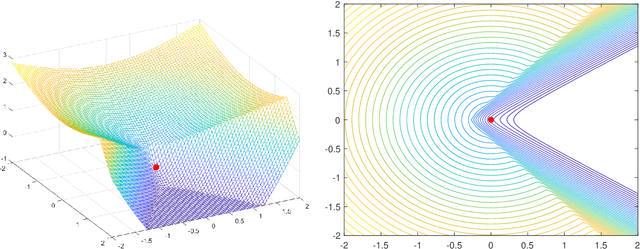
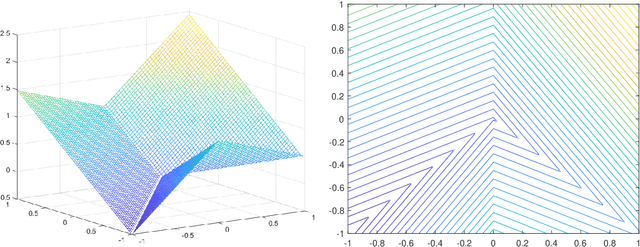
It is well-known that given a bounded, smooth nonconvex function, standard gradient-based methods can find $\epsilon$-stationary points (where the gradient norm is less than $\epsilon$) in $\mathcal{O}(1/\epsilon^2)$ iterations. However, many important nonconvex optimization problems, such as those associated with training modern neural networks, are inherently not smooth, making these results inapplicable. Moreover, as recently pointed out in Zhang et al. [2020], it is generally impossible to provide finite-time guarantees for finding an $\epsilon$-stationary point of nonsmooth functions. Perhaps the most natural relaxation of this is to find points which are near such $\epsilon$-stationary points. In this paper, we show that even this relaxed goal is hard to obtain in general, given only black-box access to the function values and gradients. We also discuss the pros and cons of alternative approaches.