 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirichlet-Based Monte Carlo Dropout for Uncertainty Estimation in Neural Networks
May 22, 2026Traditional neural networks provide deterministic predictions without inherent uncertainty estimates. While Bayesian Neural Networks (BNNs) offer a principled approach to uncertainty quantification, their computational complexity limits scalability. Monte Carlo (MC) Dropout, initially introduced as a regularization technique, has been shown to approximate Bayesian inference by enabling probabilistic modeling through multiple stochastic forward passes. In this work, we enhance uncertainty estimation in deep learning by integrating a Dirichlet-based framework within MC Dropout. Specifically, we leverage the formulation proposed by Sensoy et al. (2018), where class probabilities are modeled using a Dirichlet distribution, allowing for a more informative uncertainty representation. The proposed approach maintains the computational efficiency of MC Dropout while improving the quality of uncertainty estimates. We discuss the theoretical foundations of our method and compare it with existing uncertainty quantification techniques. The results highlight the effectiveness of the proposed method in producing well-calibrated uncertainty estimates, offering a practical solution for uncertainty-aware deep learning models.
Learning stochastic dynamical systems with neural networks mimicking the Euler-Maruyama scheme
May 18, 2021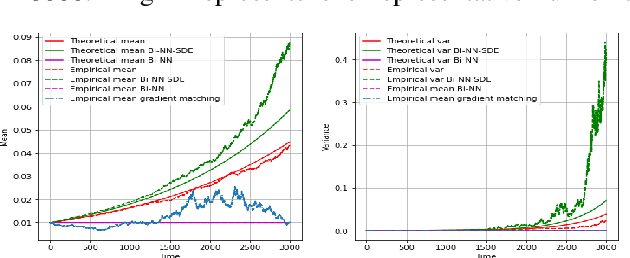

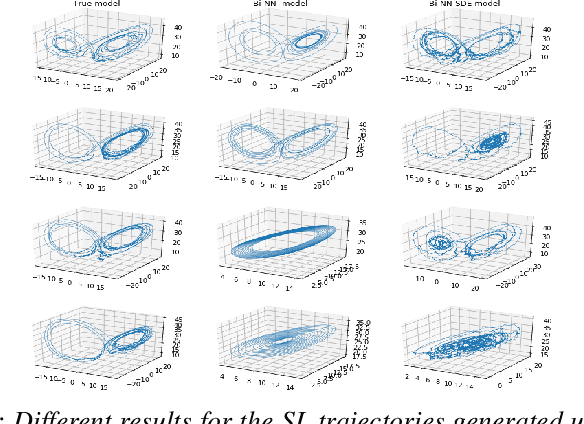
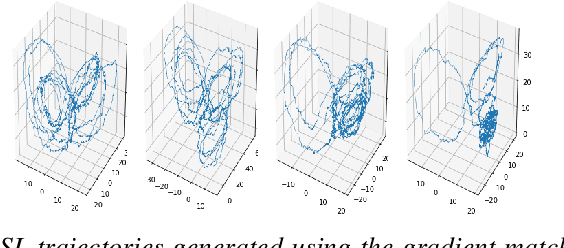
Stochastic differential equations (SDEs) are one of the most important representations of dynamical systems. They are notable for the ability to include a deterministic component of the system and a stochastic one to represent random unknown factors. However, this makes learning SDEs much more challenging than ordinary differential equations (ODEs). In this paper, we propose a data driven approach where parameters of the SDE are represented by a neural network with a built-in SDE integration scheme. The loss function is based on a maximum likelihood criterion, under order one Markov Gaussian assumptions. The algorithm is applied to the geometric brownian motion and a stochastic version of the Lorenz-63 model. The latter is particularly hard to handle due to the presence of a stochastic component that depends on the state. The algorithm performance is attested using different simulations results. Besides, comparisons are performed with the reference gradient matching method used for non linear drift estimation, and a neural networks-based method, that does not consider the stochastic term.