 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamic Network Using a Reuse Gate Function in Semi-supervised Video Object Segmentation
Dec 21, 2020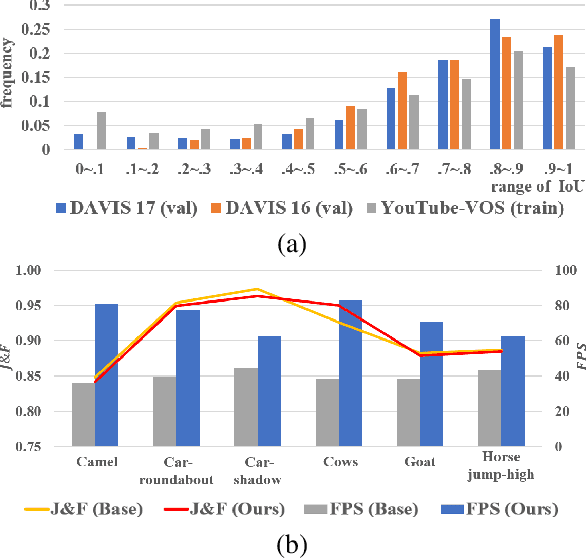
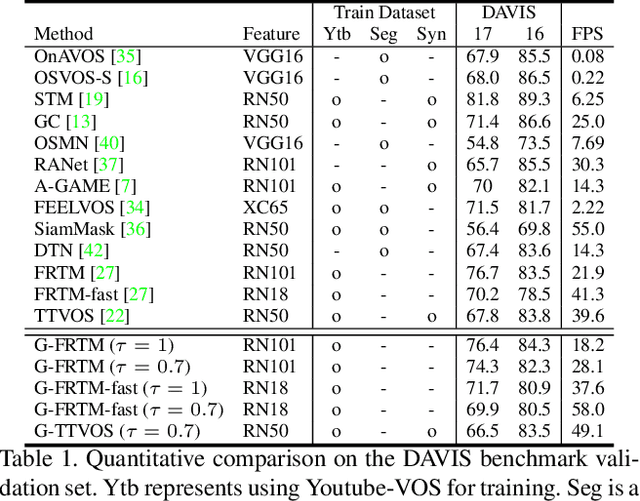
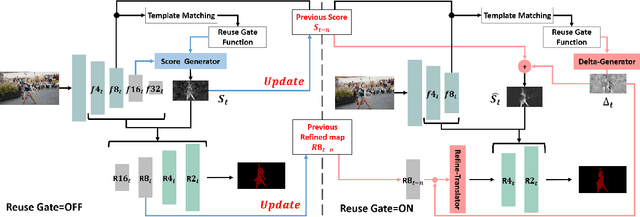
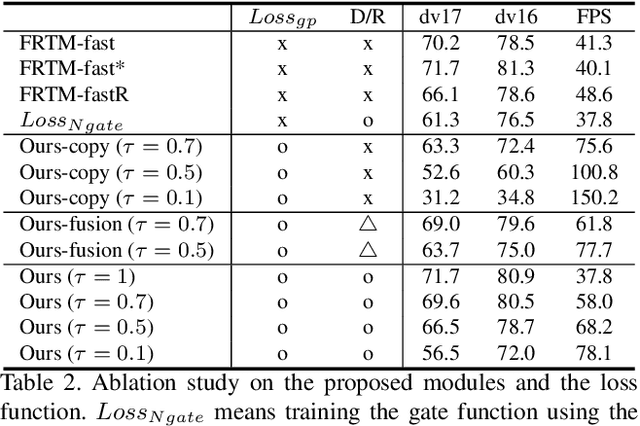
Current state-of-the-art approaches for Semi-supervised Video Object Segmentation (Semi-VOS) propagates information from previous frames to generate segmentation mask for the current frame. This results in high-quality segmentation across challenging scenarios such as changes in appearance and occlusion. But it also leads to unnecessary computations for stationary or slow-moving objects where the change across frames is minimal. In this work, we exploit this observation by using temporal information to quickly identify frames with minimal change and skip the heavyweight mask generation step. To realize this efficiency, we propose a novel dynamic network that estimates change across frames and decides which path -- computing a full network or reusing previous frame's feature -- to choose depending on the expected similarity. Experimental results show that our approach significantly improves inference speed without much accuracy degradation on challenging Semi-VOS datasets -- DAVIS 16, DAVIS 17, and YouTube-VOS. Furthermore, our approach can be applied to multiple Semi-VOS methods demonstrating its generality.
StyleUV: Diverse and High-fidelity UV Map Generative Model
Nov 25, 2020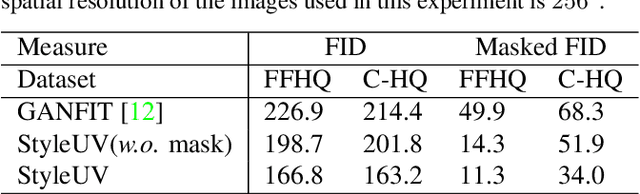
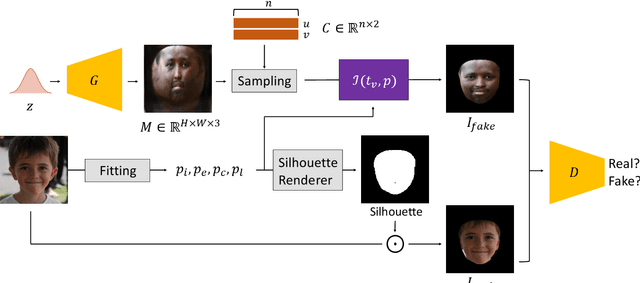


Reconstructing 3D human faces in the wild with the 3D Morphable Model (3DMM) has become popular in recent years. While most prior work focuses on estimating more robust and accurate geometry, relatively little attention has been paid to improving the quality of the texture model. Meanwhile, with the advent of Generative Adversarial Networks (GANs), there has been great progress in reconstructing realistic 2D images. Recent work demonstrates that GANs trained with abundant high-quality UV maps can produce high-fidelity textures superior to those produced by existing methods. However, acquiring such high-quality UV maps is difficult because they are expensive to acquire, requiring laborious processes to refine. In this work, we present a novel UV map generative model that learns to generate diverse and realistic synthetic UV maps without requiring high-quality UV maps for training. Our proposed framework can be trained solely with in-the-wild images (i.e., UV maps are not required) by leveraging a combination of GANs and a differentiable renderer. Both quantitative and qualitative evaluations demonstrate that our proposed texture model produces more diverse and higher fidelity textures compared to existing methods.
TTVOS: Lightweight Video Object Segmentation with Adaptive Template Attention Module and Temporal Consistency Loss
Nov 09, 2020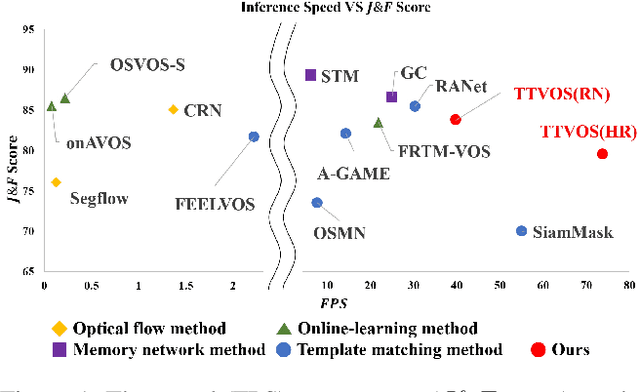
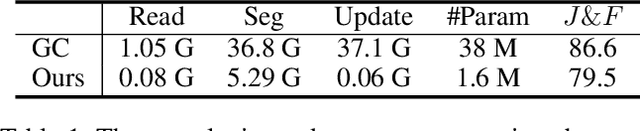
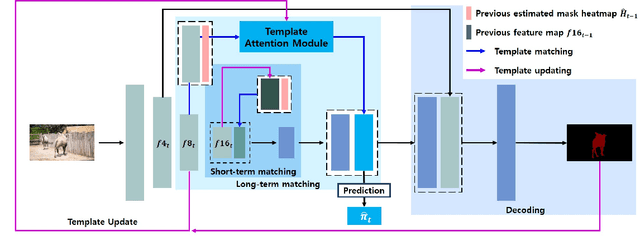
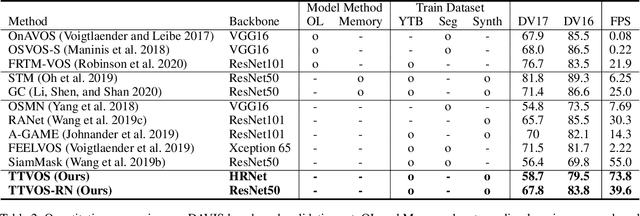
Semi-supervised video object segmentation (semi-VOS) is widely used in many applications. This task is tracking class-agnostic objects by a given segmentation mask. For doing this, various approaches have been developed based on optical flow, online-learning, and memory networks. These methods show high accuracy but are hard to be utilized in real-world applications due to slow inference time and tremendous complexity. To resolve this problem, template matching methods are devised for fast processing speed, sacrificing lots of performance. We introduce a novel semi-VOS model based on a temple matching method and a novel temporal consistency loss to reduce the performance gap from heavy models while expediting inference time a lot. Our temple matching method consists of short-term and long-term matching. The short-term matching enhances target object localization, while long-term matching improves fine details and handles object shape-changing through the newly proposed adaptive template attention module. However, the long-term matching causes error-propagation due to the inflow of the past estimated results when updating the template. To mitigate this problem, we also propose a temporal consistency loss for better temporal coherence between neighboring frames by adopting the concept of a transition matrix. Our model obtains 79.5% J&F score at the speed of 73.8 FPS on the DAVIS16 benchmark.
Asynchronous Edge Learning using Cloned Knowledge Distillation
Oct 22, 2020



With the increasing demand for more and more data, the federated learning (FL) methods, which try to utilize highly distributed on-device local data in the training process, have been proposed.However, fledgling services provided by startup companies not only have limited number of clients, but also have minimal resources for constant communications between the server and multiple clients. In addition, in a real-world environment where the user pool changes dynamically, the FL system must be able to efficiently utilize rapid inflow and outflow of users, while at the same time experience minimal bottleneck due to network delays of multiple users. In this respect, we amend the federated learning scenario to a more flexible asynchronous edge learning. To solve the aforementioned learning problems, we propose an asynchronous model-based communication method with knowledge distillation. In particular, we dub our knowledge distillation scheme as "cloned distillation" and explain how it is different from other knowledge distillation method. In brief, we found that in knowledge distillation between the teacher and the student there exist two contesting traits in the student: to attend to the teacher's knowledge or to retain its own knowledge exclusive to the teacher. And in this edge learning scenario, the attending property should be amplified rather than the retaining property, because teachers are dispatched to the users to learn from them and recollected at the server to teach the core model. Our asynchronous edge learning method can elastically handle the dynamic inflow and outflow of users in a service with minimal communication cost, operate with essentially no bottleneck due to user delay, and protect user's privacy. Also we found that it is robust to users who behave abnormally or maliciously.
Self-supervised pre-training and contrastive representation learning for multiple-choice video QA
Sep 17, 2020
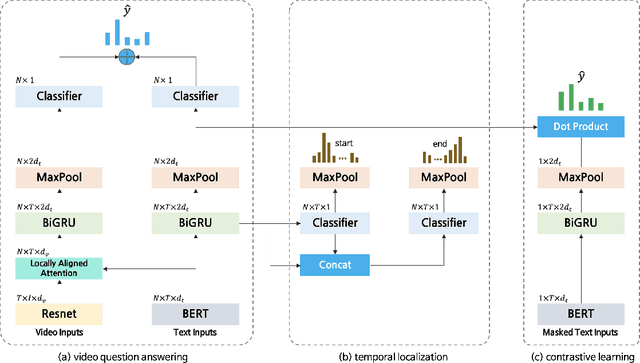
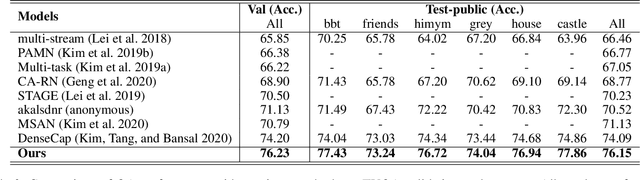
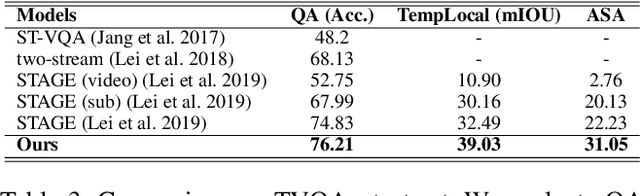
Video Question Answering (Video QA) requires fine-grained understanding of both video and language modalities to answer the given questions. In this paper, we propose novel training schemes for multiple-choice video question answering with a self-supervised pre-training stage and a supervised contrastive learning in the main stage as an auxiliary learning. In the self-supervised pre-training stage, we transform the original problem format of predicting the correct answer into the one that predicts the relevant question to provide a model with broader contextual inputs without any further dataset or annotation. For contrastive learning in the main stage, we add a masking noise to the input corresponding to the ground-truth answer, and consider the original input of the ground-truth answer as a positive sample, while treating the rest as negative samples. By mapping the positive sample closer to the masked input, we show that the model performance is improved. We further employ locally aligned attention to focus more effectively on the video frames that are particularly relevant to the given corresponding subtitle sentences. We evaluate our proposed model on highly competitive benchmark datasets related to multiple-choice videoQA: TVQA, TVQA+, and DramaQA. Experimental results show that our model achieves state-of-the-art performance on all datasets. We also validate our approaches through further analyses.
On the Orthogonality of Knowledge Distillation with Other Techniques: From an Ensemble Perspective
Sep 14, 2020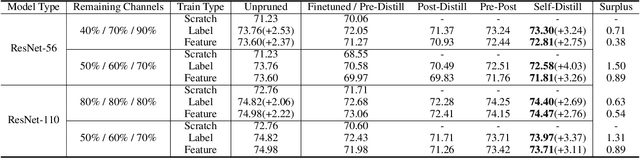


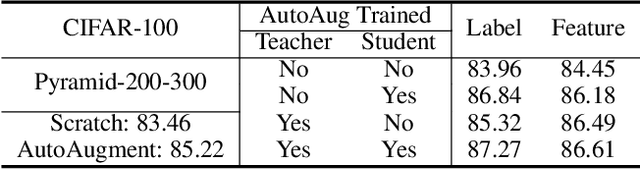
To put a state-of-the-art neural network to practical use, it is necessary to design a model that has a good trade-off between the resource consumption and performance on the test set. Many researchers and engineers are developing methods that enable training or designing a model more efficiently. Developing an efficient model includes several strategies such as network architecture search, pruning, quantization, knowledge distillation, utilizing cheap convolution, regularization, and also includes any craft that leads to a better performance-resource trade-off. When combining these technologies together, it would be ideal if one source of performance improvement does not conflict with others. We call this property as the orthogonality in model efficiency. In this paper, we focus on knowledge distillation and demonstrate that knowledge distillation methods are orthogonal to other efficiency-enhancing methods both analytically and empirically. Analytically, we claim that knowledge distillation functions analogous to a ensemble method, bootstrap aggregating. This analytical explanation is provided from the perspective of implicit data augmentation property of knowledge distillation. Empirically, we verify knowledge distillation as a powerful apparatus for practical deployment of efficient neural network, and also introduce ways to integrate it with other methods effectively.
Part-Aware Data Augmentation for 3D Object Detection in Point Cloud
Jul 27, 2020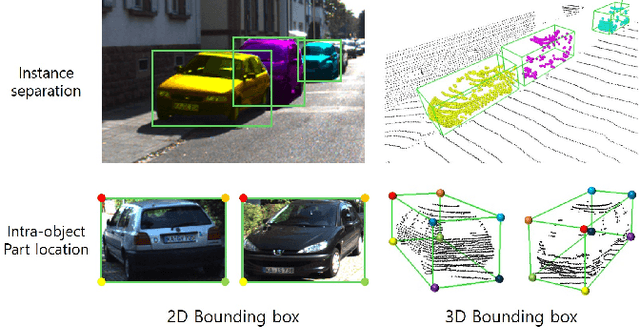
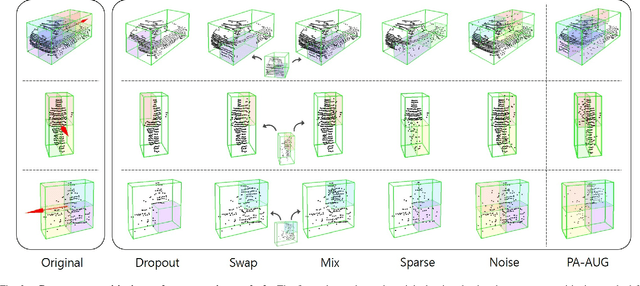
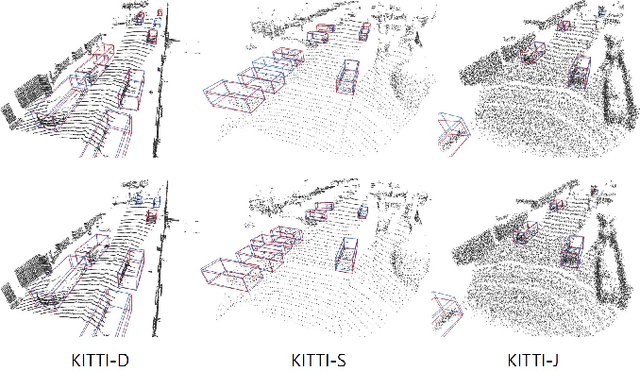
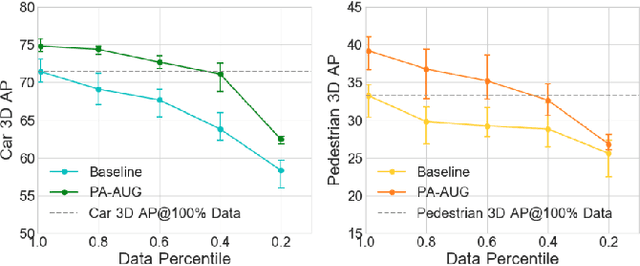
Data augmentation has greatly contributed to improving the performance in image recognition tasks, and a lot of related studies have been conducted. However, data augmentation on 3D point cloud data has not been much explored. 3D label has more sophisticated and rich structural information than the 2D label, so it enables more diverse and effective data augmentation. In this paper, we propose part-aware data augmentation (PA-AUG) that can better utilize rich information of 3D label to enhance the performance of 3D object detectors. PA-AUG divides objects into partitions and stochastically applies five novel augmentation methods to each local region. It is compatible with existing point cloud data augmentation methods and can be used universally regardless of the detector's architecture. PA-AUG has improved the performance of state-of-the-art 3D object detector for all classes of the KITTI dataset and has the equivalent effect of increasing the train data by about 2.5$\times$. We also show that PA-AUG not only increases performance for a given dataset but also is robust to corrupted data. CODE WILL BE AVAILABLE.
Procrustean Regression Networks: Learning 3D Structure of Non-Rigid Objects from 2D Annotations
Jul 21, 2020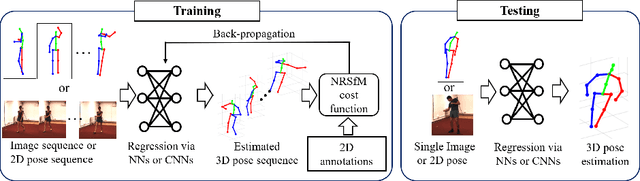
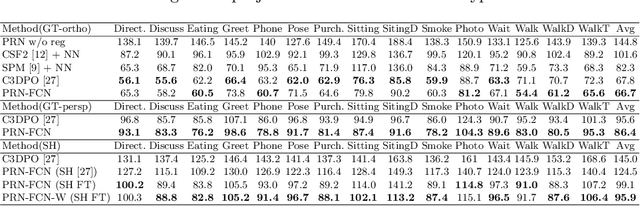

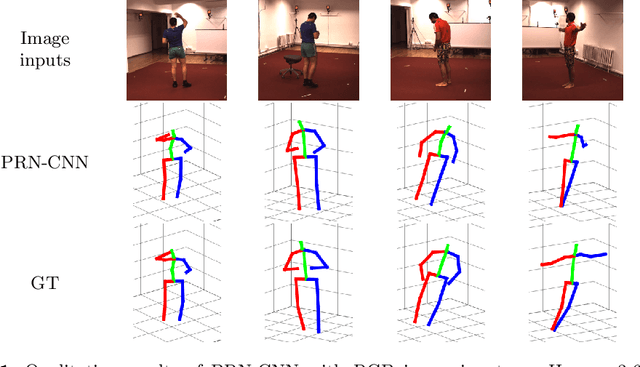
We propose a novel framework for training neural networks which is capable of learning 3D information of non-rigid objects when only 2D annotations are available as ground truths. Recently, there have been some approaches that incorporate the problem setting of non-rigid structure-from-motion (NRSfM) into deep learning to learn 3D structure reconstruction. The most important difficulty of NRSfM is to estimate both the rotation and deformation at the same time, and previous works handle this by regressing both of them. In this paper, we resolve this difficulty by proposing a loss function wherein the suitable rotation is automatically determined. Trained with the cost function consisting of the reprojection error and the low-rank term of aligned shapes, the network learns the 3D structures of such objects as human skeletons and faces during the training, whereas the testing is done in a single-frame basis. The proposed method can handle inputs with missing entries and experimental results validate that the proposed framework shows superior reconstruction performance to the state-of-the-art method on the Human 3.6M, 300-VW, and SURREAL datasets, even though the underlying network structure is very simple.
SeqHAND:RGB-Sequence-Based 3D Hand Pose and Shape Estimation
Jul 10, 2020
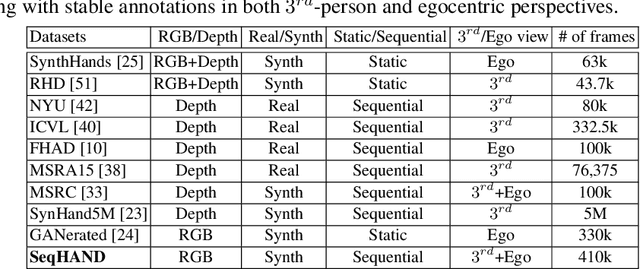
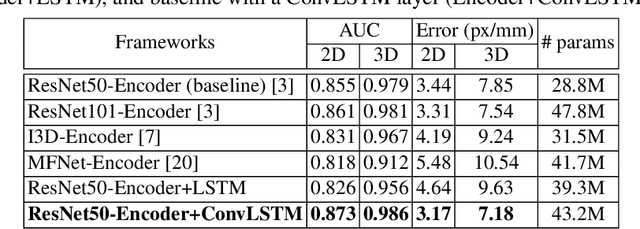
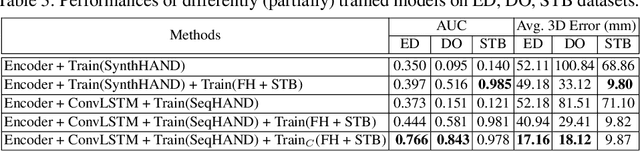
3D hand pose estimation based on RGB images has been studied for a long time. Most of the studies, however, have performed frame-by-frame estimation based on independent static images. In this paper, we attempt to not only consider the appearance of a hand but incorporate the temporal movement information of a hand in motion into the learning framework for better 3D hand pose estimation performance, which leads to the necessity of a large scale dataset with sequential RGB hand images. We propose a novel method that generates a synthetic dataset that mimics natural human hand movements by re-engineering annotations of an extant static hand pose dataset into pose-flows. With the generated dataset, we train a newly proposed recurrent framework, exploiting visuo-temporal features from sequential images of synthetic hands in motion and emphasizing temporal smoothness of estimations with a temporal consistency constraint. Our novel training strategy of detaching the recurrent layer of the framework during domain finetuning from synthetic to real allows preservation of the visuo-temporal features learned from sequential synthetic hand images. Hand poses that are sequentially estimated consequently produce natural and smooth hand movements which lead to more robust estimations. We show that utilizing temporal information for 3D hand pose estimation significantly enhances general pose estimations by outperforming state-of-the-art methods in experiments on hand pose estimation benchmarks.
Position-based Scaled Gradient for Model Quantization and Sparse Training
Jun 10, 2020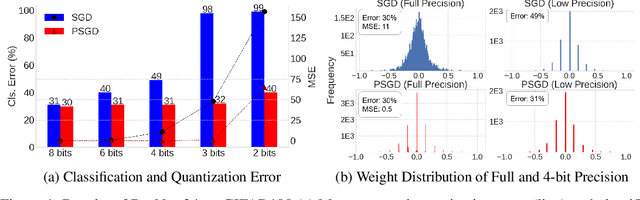
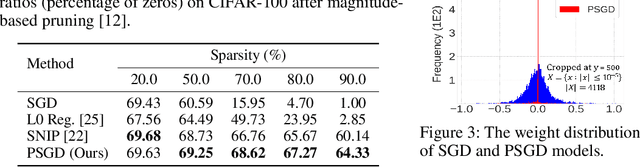
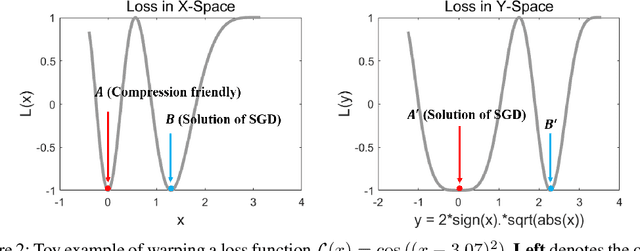
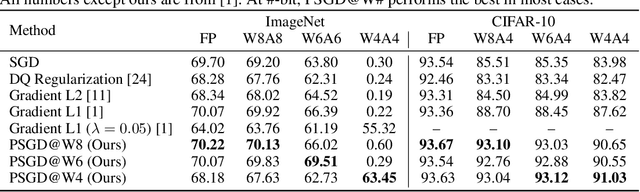
We propose the position-based scaled gradient (PSG) that scales the gradient depending on the position of a weight vector to make it more compression-friendly. First, we theoretically show that applying PSG to the standard gradient descent (GD), which is called PSGD, is equivalent to the GD in the warped weight space, a space made by warping the original weight space via an appropriately designed invertible function. Second, we empirically show that PSG acting as a regularizer to a weight vector is very useful in model compression domains such as quantization and sparse training. PSG reduces the gap between the weight distributions of a full-precision model and its compressed counterpart. This enables the versatile deployment of a model either as an uncompressed mode or as a compressed mode depending on the availability of resources. The experimental results on CIFAR-10/100 and Imagenet datasets show the effectiveness of the proposed PSG in both domains of sparse training and quantization even for extremely low bits.