 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of Linguistic Biases in LLM-Based Recommendations
Apr 28, 2026We investigate linguistic biases in LLM-based restaurant and product recommendations given prompts varying across Southern American English (AE), Indian English (IE), and Code-Switched Hindi-English dialects, using the Yelp Open dataset (Yelp Inc., 2023) and Walmart product reviews dataset (PromptCloud,2020). We add lists of restaurant and product names balanced by cuisine type and product category to the prompts given to the LLM, and we zero-shot prompt the LLMs in a cold-start setting to select the top-20 restaurant and product recommendations from these lists for each of the dialect-varied prompts. We prompt LLMs using different list samples across 20 seeds for better generalization, and aggregate per cuisine-type and per category response counts for each seed, question/prompt, and LLM model. We run mixed-effects regression models for each model family and topic (restaurant/product) with the aggregate response counts as the dependent, and conduct likelihood ratio tests for the fixed effects with post-hoc pairwise testing of estimated marginal means differences, to investigate group-level differences in recommendation counts by model size and dialect type. Results show that dialect plays a role in the type of restaurant selected across the models tested with the mistral-small-3.1 model and both the llama-3.1 family models tested showing more sensitivity to Indian English and Code-Switched prompts. In terms of product recommendations, the llama-3.1-70B-model is particularly sensitive to Code-Switched prompts in four out of seven categories, and more beauty and home category recommendations are seen when using the Indian English and Code-Switched prompts for larger and smaller models, respectively. No broad trends are seen in the model-size based differences, with differing recommendations based on model sizes conditioned by the type of dialect.
MASALA: Modelling and Analysing the Semantics of Adpositions in Linguistic Annotation of Hindi
May 08, 2022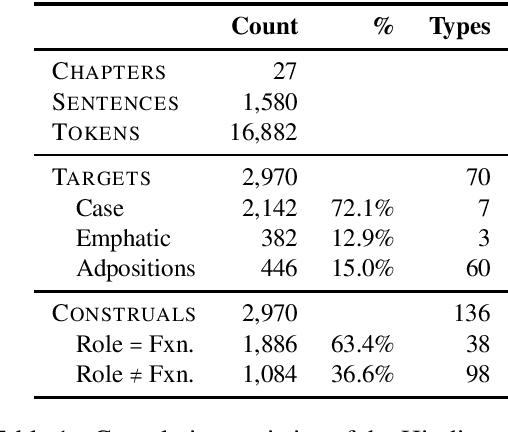
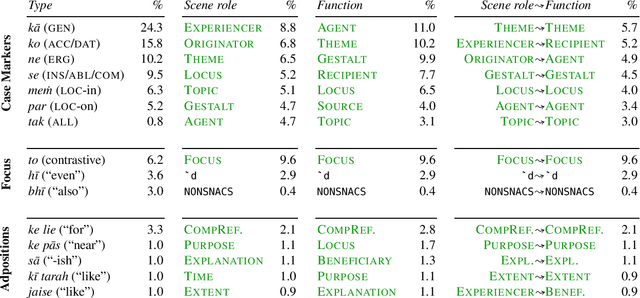
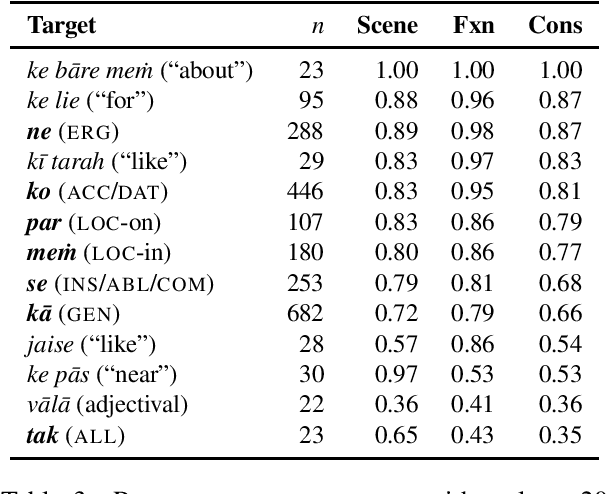
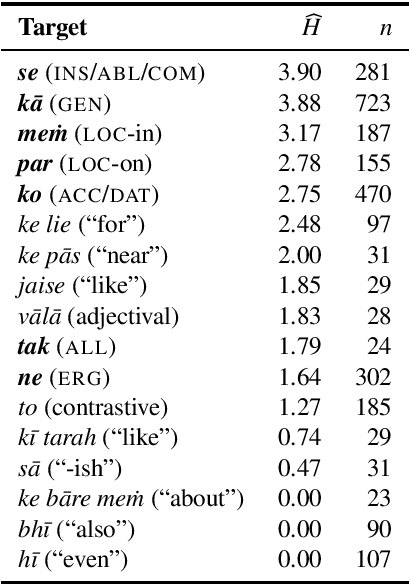
We present a completed, publicly available corpus of annotated semantic relations of adpositions and case markers in Hindi. We used the multilingual SNACS annotation scheme, which has been applied to a variety of typologically diverse languages. Building on past work examining linguistic problems in SNACS annotation, we use language models to attempt automatic labelling of SNACS supersenses in Hindi and achieve results competitive with past work on English. We look towards upstream applications in semantic role labelling and extension to related languages such as Gujarati.
Hindi-Urdu Adposition and Case Supersenses v1.0
Mar 02, 2021
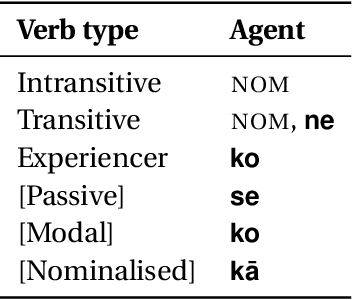
These are the guidelines for the application of SNACS (Semantic Network of Adposition and Case Supersenses; Schneider et al. 2018) to Modern Standard Hindi of Delhi. SNACS is an inventory of 50 supersenses (semantic labels) for labelling the use of adpositions and case markers with respect to both lexical-semantic function and relation to the underlying context. The English guidelines (Schneider et al., 2020) were used as a model for this document. Besides the case system, Hindi has an extremely rich adpositional system built on the oblique genitive, with productive incorporation of loanwords even in present-day Hinglish. This document is aligned with version 2.5 of the English guidelines.