 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Redundancy in Cost Functions for Resilience in Distributed Optimization and Learning
Oct 21, 2021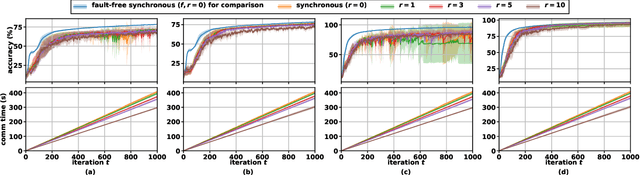
This paper considers the problem of resilient distributed optimization and stochastic machine learning in a server-based architecture. The system comprises a server and multiple agents, where each agent has a local cost function. The agents collaborate with the server to find a minimum of their aggregate cost functions. We consider the case when some of the agents may be asynchronous and/or Byzantine faulty. In this case, the classical algorithm of distributed gradient descent (DGD) is rendered ineffective. Our goal is to design techniques improving the efficacy of DGD with asynchrony and Byzantine failures. To do so, we start by proposing a way to model the agents' cost functions by the generic notion of $(f, \,r; \epsilon)$-redundancy where $f$ and $r$ are the parameters of Byzantine failures and asynchrony, respectively, and $\epsilon$ characterizes the closeness between agents' cost functions. This allows us to quantify the level of redundancy present amongst the agents' cost functions, for any given distributed optimization problem. We demonstrate, both theoretically and empirically, the merits of our proposed redundancy model in improving the robustness of DGD against asynchronous and Byzantine agents, and their extensions to distributed stochastic gradient descent (D-SGD) for robust distributed machine learning with asynchronous and Byzantine agents.
Byzantine Fault-Tolerance in Federated Local SGD under 2f-Redundancy
Aug 26, 2021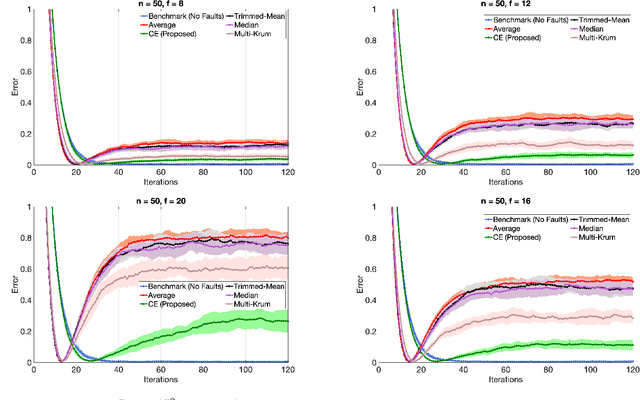

We consider the problem of Byzantine fault-tolerance in federated machine learning. In this problem, the system comprises multiple agents each with local data, and a trusted centralized coordinator. In fault-free setting, the agents collaborate with the coordinator to find a minimizer of the aggregate of their local cost functions defined over their local data. We consider a scenario where some agents ($f$ out of $N$) are Byzantine faulty. Such agents need not follow a prescribed algorithm correctly, and may communicate arbitrary incorrect information to the coordinator. In the presence of Byzantine agents, a more reasonable goal for the non-faulty agents is to find a minimizer of the aggregate cost function of only the non-faulty agents. This particular goal is commonly referred as exact fault-tolerance. Recent work has shown that exact fault-tolerance is achievable if only if the non-faulty agents satisfy the property of $2f$-redundancy. Now, under this property, techniques are known to impart exact fault-tolerance to the distributed implementation of the classical stochastic gradient-descent (SGD) algorithm. However, we do not know of any such techniques for the federated local SGD algorithm - a more commonly used method for federated machine learning. To address this issue, we propose a novel technique named comparative elimination (CE). We show that, under $2f$-redundancy, the federated local SGD algorithm with CE can indeed obtain exact fault-tolerance in the deterministic setting when the non-faulty agents can accurately compute gradients of their local cost functions. In the general stochastic case, when agents can only compute unbiased noisy estimates of their local gradients, our algorithm achieves approximate fault-tolerance with approximation error proportional to the variance of stochastic gradients and the fraction of Byzantine agents.