 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of Binary Neural Networks: Enabling Low-Cost Inference
Mar 16, 2026Federated Learning (FL) preserves privacy by distributing training across devices. However, using DNNs is computationally intensive at the low-powered edge during inference. Edge deployment demands models that simultaneously optimize memory footprint and computational efficiency, a dilemma where conventional DNNs fail by exceeding resource limits. Traditional post-training binarization reduces model size but suffers from severe accuracy loss due to quantization errors. To address these challenges, we propose FedBNN, a rotation-aware binary neural network framework that learns binary representations directly during local training. By encoding each weight as a single bit $\{+1, -1\}$ instead of a $32$-bit float, FedBNN shrinks the model footprint, significantly reducing runtime (during inference) FLOPs and memory requirements in comparison to federated methods using real models. Evaluations across multiple benchmark datasets demonstrate that FedBNN significantly reduces resource consumption while performing similarly to existing federated methods using real-valued models.
Golden Ratio Search: A Low-Power Adversarial Attack for Deep Learning based Modulation Classification
Sep 17, 2024



We propose a minimal power white box adversarial attack for Deep Learning based Automatic Modulation Classification (AMC). The proposed attack uses the Golden Ratio Search (GRS) method to find powerful attacks with minimal power. We evaluate the efficacy of the proposed method by comparing it with existing adversarial attack approaches. Additionally, we test the robustness of the proposed attack against various state-of-the-art architectures, including defense mechanisms such as adversarial training, binarization, and ensemble methods. Experimental results demonstrate that the proposed attack is powerful, requires minimal power, and can be generated in less time, significantly challenging the resilience of current AMC methods.
Binarized ResNet: Enabling Automatic Modulation Classification at the resource-constrained Edge
Oct 27, 2021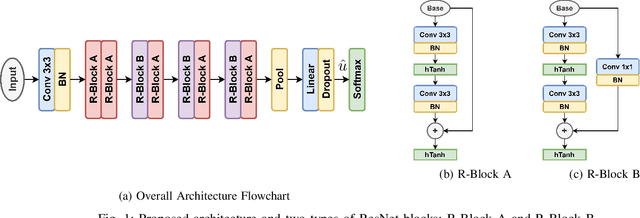
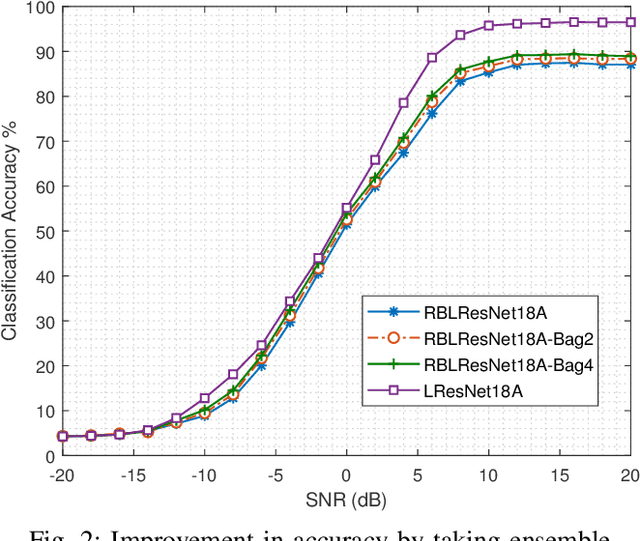
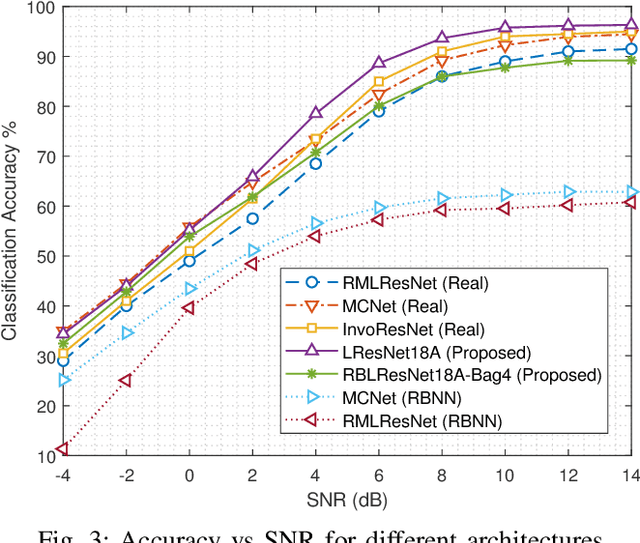
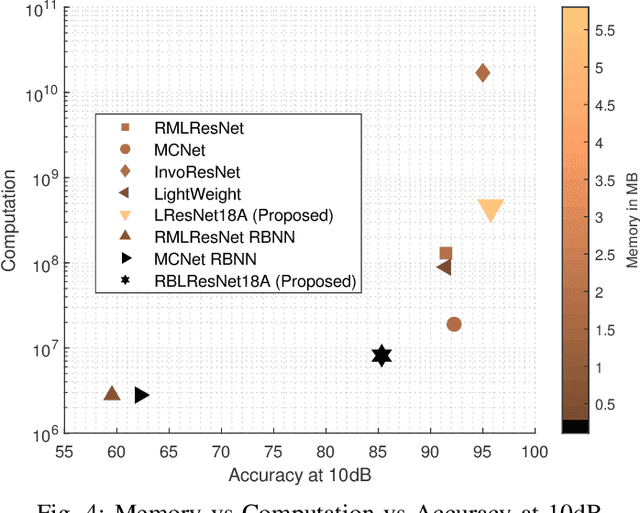
In this paper, we propose a ResNet based neural architecture to solve the problem of Automatic Modulation Classification. We showed that our architecture outperforms the state-of-the-art (SOTA) architectures. We further propose to binarize the network to deploy it in the Edge network where the devices are resource-constrained i.e. have limited memory and computing power. Instead of simple binarization, rotated binarization is applied to the network which helps to close the significant performance gap between the real and the binarized network. Because of the immense representation capability or the real network, its rotated binarized version achieves $85.33\%$ accuracy compared to $95.76\%$ accuracy of the proposed real network with $2.33$ and $16$ times lesser computing power than two of the SOTA architectures, MCNet and RMLResNet respectively, and approximately $16$ times less memory than both. The performance can be improved further to $87.74\%$ by taking an ensemble of four such rotated binarized networks.