 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving HPC services to enable ML workloads on HPE Cray EX
Jul 02, 2025



The Alps Research Infrastructure leverages GH200 technology at scale, featuring 10,752 GPUs. Accessing Alps provides a significant computational advantage for researchers in Artificial Intelligence (AI) and Machine Learning (ML). While Alps serves a broad range of scientific communities, traditional HPC services alone are not sufficient to meet the dynamic needs of the ML community. This paper presents an initial investigation into extending HPC service capabilities to better support ML workloads. We identify key challenges and gaps we have observed since the early-access phase (2023) of Alps by the Swiss AI community and propose several technological enhancements. These include a user environment designed to facilitate the adoption of HPC for ML workloads, balancing performance with flexibility; a utility for rapid performance screening of ML applications during development; observability capabilities and data products for inspecting ongoing large-scale ML workloads; a utility to simplify the vetting of allocated nodes for compute readiness; a service plane infrastructure to deploy various types of workloads, including support and inference services; and a storage infrastructure tailored to the specific needs of ML workloads. These enhancements aim to facilitate the execution of ML workloads on HPC systems, increase system usability and resilience, and better align with the needs of the ML community. We also discuss our current approach to security aspects. This paper concludes by placing these proposals in the broader context of changes in the communities served by HPC infrastructure like ours.
Optimising AI Training Deployments using Graph Compilers and Containers
Sep 17, 2020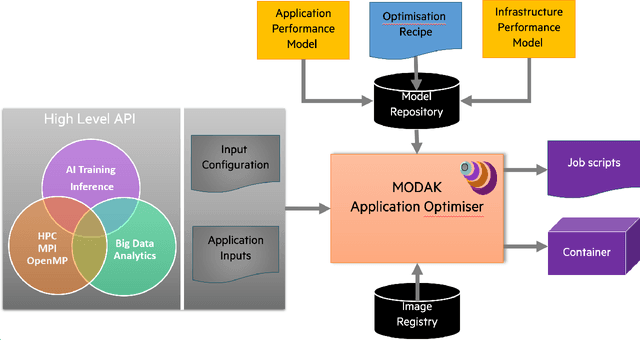
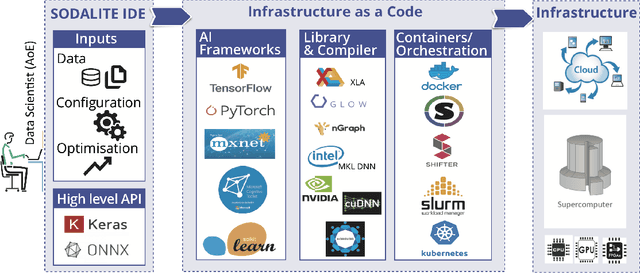
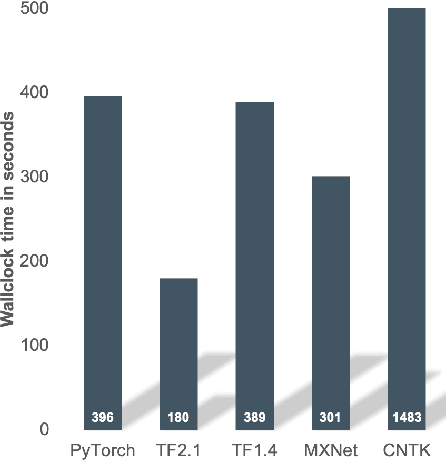
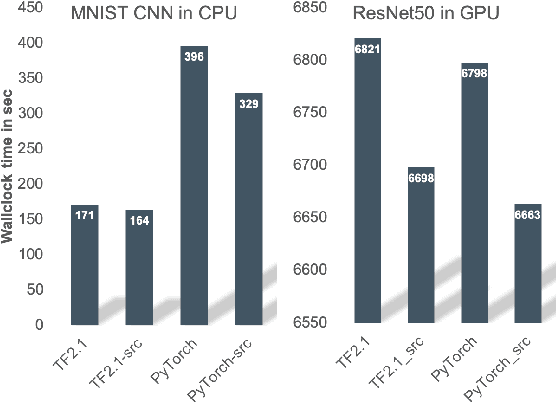
Artificial Intelligence (AI) applications based on Deep Neural Networks (DNN) or Deep Learning (DL) have become popular due to their success in solving problems likeimage analysis and speech recognition. Training a DNN is computationally intensive and High Performance Computing(HPC) has been a key driver in AI growth. Virtualisation and container technology have led to the convergence of cloud and HPC infrastructure. These infrastructures with diverse hardware increase the complexity of deploying and optimising AI training workloads. AI training deployments in HPC or cloud can be optimised with target-specific libraries, graph compilers, andby improving data movement or IO. Graph compilers aim to optimise the execution of a DNN graph by generating an optimised code for a target hardware/backend. As part of SODALITE (a Horizon 2020 project), MODAK tool is developed to optimise application deployment in software defined infrastructures. Using input from the data scientist and performance modelling, MODAK maps optimal application parameters to a target infrastructure and builds an optimised container. In this paper, we introduce MODAK and review container technologies and graph compilers for AI. We illustrate optimisation of AI training deployments using graph compilers and Singularity containers. Evaluation using MNIST-CNN and ResNet50 training workloads shows that custom built optimised containers outperform the official images from DockerHub. We also found that the performance of graph compilers depends on the target hardware and the complexity of the neural network.