 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Decide with AI Assistance under Human-Alignment
May 12, 2026It is widely agreed that when AI models assist decision-makers in high-stakes domains by predicting an outcome of interest, they should communicate the confidence of their predictions. However, empirical evidence suggests that decision-makers often struggle to determine when to trust a prediction based solely on this communicated confidence. In this context, recent theoretical and empirical work suggests a positive correlation between the utility of AI-assisted decision-making and the degree of alignment between the AI confidence and the decision-makers' confidence in their own predictions. Crucially, these findings do not yet elucidate the extent to which this alignment influences the complexity of learning to make optimal decisions through repeated interactions. In this paper, we address this question in the canonical case of binary predictions and binary decisions. We first show that this problem is equivalent to a two-armed online contextual learning problem with full feedback, and establish a lower bound of $Ω(\sqrt{|H| \cdot |B| \cdot T} )$ on the expected regret any learner can attain, where $H$ and $B$ denote the sets of human and AI confidence values. We then demonstrate that, under perfect alignment between AI and human confidence, a learner can attain an expected regret of $O(\sqrt{|H| \cdot T\log T})$ and, when $\sqrt{|H|} = O(\log T)$ and $B$ is countable, a non-trivial generalization of the Dvoretzky-Kiefer-Wolfowitz inequality improves the regret bound to $O(\sqrt{T\log T})$. Taken together, these results reveal that alignment can reduce the complexity of learning to make decisions with AI assistance. Experiments on real data from two different human-subject studies where participants solve simple decision-making tasks assisted by AI models show that our theoretical results are robust to violations of perfect alignment.
Canonical Autoregressive Generation
Jun 06, 2025State of the art large language models are trained using large amounts of tokens derived from raw text using what is called a tokenizer. Crucially, the tokenizer determines the (token) vocabulary a model will use during inference as well as, in principle, the (token) language. This is because, while the token vocabulary may allow for different tokenizations of a string, the tokenizer always maps the string to only one of these tokenizations--the canonical tokenization. However, multiple lines of empirical evidence suggest that large language models do not always generate canonical token sequences, and this comes with several negative consequences. In this work, we first show that, to generate a canonical token sequence, a model needs to generate (partial) canonical token sequences at each step of the autoregressive generation process underpinning its functioning. Building upon this theoretical result, we introduce canonical sampling, a simple and efficient sampling method that precludes a given model from generating non-canonical token sequences. Further, we also show that, in comparison with standard sampling, the distribution of token sequences generated using canonical sampling is provably closer to the true distribution of token sequences used during training.
Evaluation of Large Language Models via Coupled Token Generation
Feb 03, 2025



State of the art large language models rely on randomization to respond to a prompt. As an immediate consequence, a model may respond differently to the same prompt if asked multiple times. In this work, we argue that the evaluation and ranking of large language models should control for the randomization underpinning their functioning. Our starting point is the development of a causal model for coupled autoregressive generation, which allows different large language models to sample responses with the same source of randomness. Building upon our causal model, we first show that, on evaluations based on benchmark datasets, coupled autoregressive generation leads to the same conclusions as vanilla autoregressive generation but using provably fewer samples. However, we further show that, on evaluations based on (human) pairwise comparisons, coupled and vanilla autoregressive generation can surprisingly lead to different rankings when comparing more than two models, even with an infinite amount of samples. This suggests that the apparent advantage of a model over others in existing evaluation protocols may not be genuine but rather confounded by the randomness inherent to the generation process. To illustrate and complement our theoretical results, we conduct experiments with several large language models from the Llama family. We find that, across multiple knowledge areas from the popular MMLU benchmark dataset, coupled autoregressive generation requires up to 40% fewer samples to reach the same conclusions as vanilla autoregressive generation. Further, using data from the LMSYS Chatbot Arena platform, we find that the win-rates derived from pairwise comparisons by a strong large language model to prompts differ under coupled and vanilla autoregressive generation.
Counterfactual Token Generation in Large Language Models
Sep 25, 2024



"Sure, I am happy to generate a story for you: Captain Lyra stood at the helm of her trusty ship, the Maelstrom's Fury, gazing out at the endless sea. [...] Lyra's eyes welled up with tears as she realized the bitter truth - she had sacrificed everything for fleeting riches, and lost the love of her crew, her family, and herself." Although this story, generated by a large language model, is captivating, one may wonder -- how would the story have unfolded if the model had chosen "Captain Maeve" as the protagonist instead? We cannot know. State-of-the-art large language models are stateless -- they maintain no internal memory or state. Given a prompt, they generate a sequence of tokens as an output using an autoregressive process. As a consequence, they cannot reason about counterfactual alternatives to tokens they have generated in the past. In this work, our goal is to enhance them with this functionality. To this end, we develop a causal model of token generation that builds upon the Gumbel-Max structural causal model. Our model allows any large language model to perform counterfactual token generation at almost no cost in comparison with vanilla token generation, it is embarrassingly simple to implement, and it does not require any fine-tuning nor prompt engineering. We implement our model on Llama 3 8B-instruct and conduct both qualitative and quantitative analyses of counterfactually generated text. We conclude with a demonstrative application of counterfactual token generation for bias detection, unveiling interesting insights about the model of the world constructed by large language models.
Counterfactual Inference of Second Opinions
Mar 16, 2022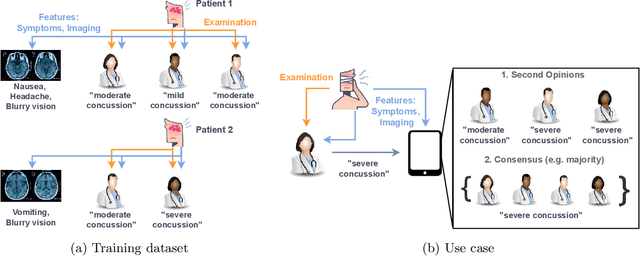


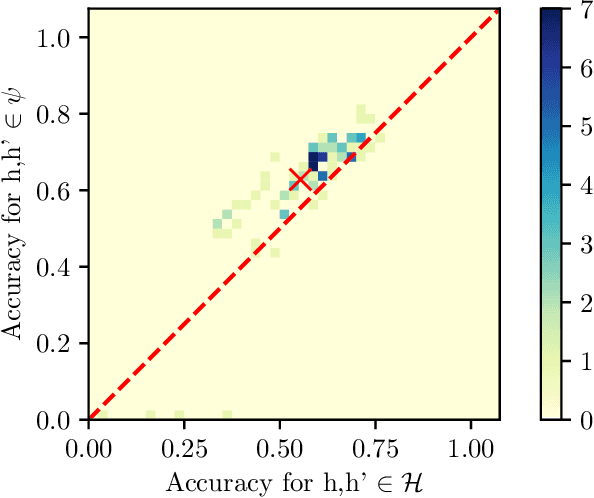
Automated decision support systems that are able to infer second opinions from experts can potentially facilitate a more efficient allocation of resources; they can help decide when and from whom to seek a second opinion. In this paper, we look at the design of this type of support systems from the perspective of counterfactual inference. We focus on a multiclass classification setting and first show that, if experts make predictions on their own, the underlying causal mechanism generating their predictions needs to satisfy a desirable set invariant property. Further, we show that, for any causal mechanism satisfying this property, there exists an equivalent mechanism where the predictions by each expert are generated by independent sub-mechanisms governed by a common noise. This motivates the design of a set invariant Gumbel-Max structural causal model where the structure of the noise governing the sub-mechanisms underpinning the model depends on an intuitive notion of similarity between experts which can be estimated from data. Experiments on both synthetic and real data show that our model can be used to infer second opinions more accurately than its non-causal counterpart.