 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Study of Biometric Spoofing Detection using Deep Learning
Jun 09, 2026Biometric systems are increasingly deployed in security applications; however, they remain vulnerable to spoofing attacks, in which attackers exploit counterfeit biometric data to gain unauthorized access. This research evaluates the effectiveness of state-of-the-art machine learning models, MobileNetV2, DenseNet-121, Inception-v3, and Spoof Trace Disentanglement (STD) in detecting spoofing attacks within facial recognition systems. Using the CelebA-Spoof dataset, the study evaluates model effectiveness using metrics such as accuracy, precision, recall, and F1 Score. Cross-dataset validation is carried out on the MSU-MFSD dataset to assess generalizability. The results show MobileNetV2 as the most efficient model, achieving 92% accuracy while balancing computational effectiveness, making it appropriate for real-life applications. Inception-v3 shows moderate robustness, while DenseNet-121 and STD struggle with generalization. The findings highlight the need for advances in domain adaptation and hybrid architectures to enhance biometric security systems.
Evaluating and Combating the Impact of Concept Drift on the Performance of Machine Learning-Based Phishing Detection Systems
Jun 09, 2026The expansion of the digital domain has resulted in a substantial increase in digital communication, with email emerging as one of the most prominent channels. The proliferation of email communication is apparent in both professional and personal contexts, thereby creating numerous vulnerabilities for malicious actors to exploit. Spam emails, a form of unsolicited correspondence often bearing malicious intent towards recipients, have been an ongoing challenge for email users since the inception of email technology, and this problem has been exacerbated by the growth of the digital landscape. Email spam filters are integral components of email clients, engineered to identify potentially harmful messages and alert users to their malicious content. Phishing, frequently the initial phase of malware-based attacks, is evolving rapidly, with malware becoming increasingly sophisticated over time. A widely adopted approach for detecting malicious activity within malware and spam domains is the application of machine learning. Our aim is to assess the impact of the evolution within the spam email domain on these machine learning-based detection systems and to explore strategies for mitigating associated performance degradation.
Evaluation of Fake News Detection with Knowledge-Enhanced Language Models
Apr 01, 2022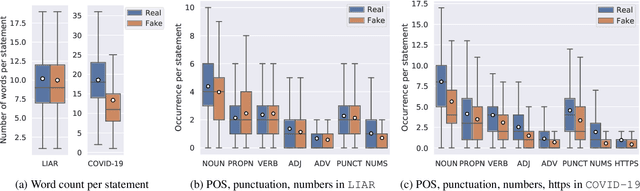
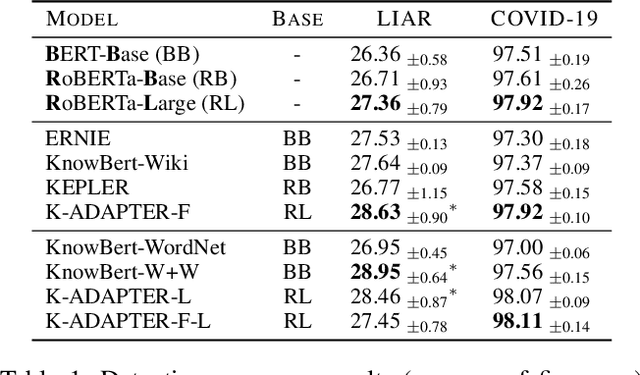
Recent advances in fake news detection have exploited the success of large-scale pre-trained language models (PLMs). The predominant state-of-the-art approaches are based on fine-tuning PLMs on labelled fake news datasets. However, large-scale PLMs are generally not trained on structured factual data and hence may not possess priors that are grounded in factually accurate knowledge. The use of existing knowledge bases (KBs) with rich human-curated factual information has thus the potential to make fake news detection more effective and robust. In this paper, we investigate the impact of knowledge integration into PLMs for fake news detection. We study several state-of-the-art approaches for knowledge integration, mostly using Wikidata as KB, on two popular fake news datasets - LIAR, a politics-based dataset, and COVID-19, a dataset of messages posted on social media relating to the COVID-19 pandemic. Our experiments show that knowledge-enhanced models can significantly improve fake news detection on LIAR where the KB is relevant and up-to-date. The mixed results on COVID-19 highlight the reliance on stylistic features and the importance of domain specific and current KBs.