 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Decomposition of Compressive Streaming Data Using $n$-$\ell_1$ Cluster-Weighted Minimization
Feb 08, 2018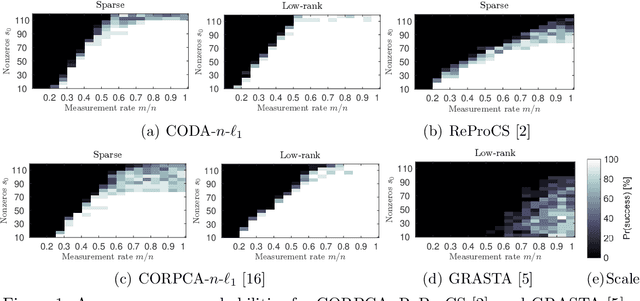

We consider a decomposition method for compressive streaming data in the context of online compressive Robust Principle Component Analysis (RPCA). The proposed decomposition solves an $n$-$\ell_1$ cluster-weighted minimization to decompose a sequence of frames (or vectors), into sparse and low-rank components, from compressive measurements. Our method processes a data vector of the stream per time instance from a small number of measurements in contrast to conventional batch RPCA, which needs to access full data. The $n$-$\ell_1$ cluster-weighted minimization leverages the sparse components along with their correlations with multiple previously-recovered sparse vectors. Moreover, the proposed minimization can exploit the structures of sparse components via clustering and re-weighting iteratively. The method outperforms the existing methods for both numerical data and actual video data.
Multiview Deep Learning for Predicting Twitter Users' Location
Dec 21, 2017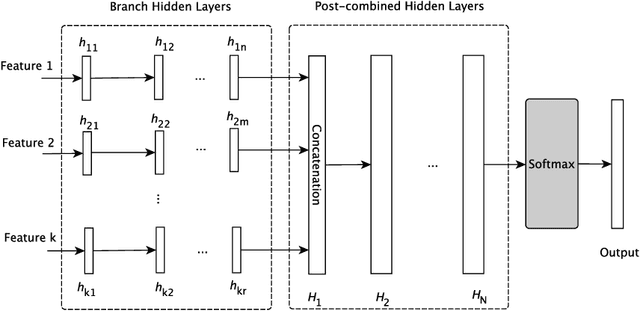

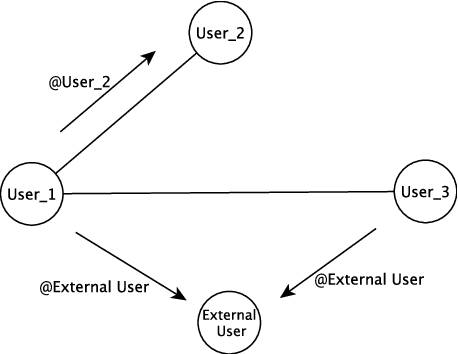
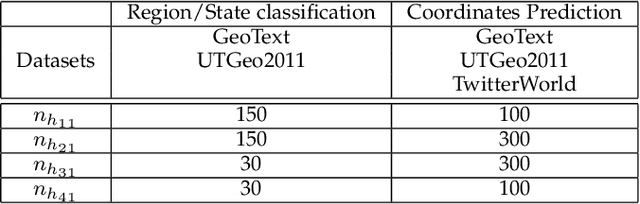
The problem of predicting the location of users on large social networks like Twitter has emerged from real-life applications such as social unrest detection and online marketing. Twitter user geolocation is a difficult and active research topic with a vast literature. Most of the proposed methods follow either a content-based or a network-based approach. The former exploits user-generated content while the latter utilizes the connection or interaction between Twitter users. In this paper, we introduce a novel method combining the strength of both approaches. Concretely, we propose a multi-entry neural network architecture named MENET leveraging the advances in deep learning and multiview learning. The generalizability of MENET enables the integration of multiple data representations. In the context of Twitter user geolocation, we realize MENET with textual, network, and metadata features. Considering the natural distribution of Twitter users across the concerned geographical area, we subdivide the surface of the earth into multi-scale cells and train MENET with the labels of the cells. We show that our method outperforms the state of the art by a large margin on three benchmark datasets.
Deep Learning Sparse Ternary Projections for Compressed Sensing of Images
Aug 28, 2017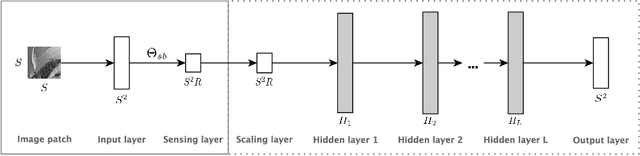
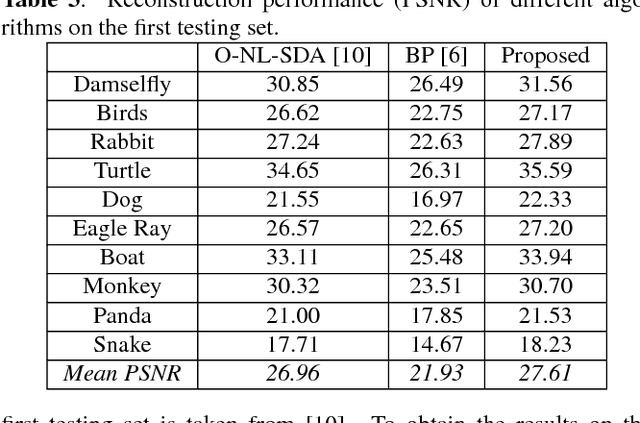
Compressed sensing (CS) is a sampling theory that allows reconstruction of sparse (or compressible) signals from an incomplete number of measurements, using of a sensing mechanism implemented by an appropriate projection matrix. The CS theory is based on random Gaussian projection matrices, which satisfy recovery guarantees with high probability; however, sparse ternary {0, -1, +1} projections are more suitable for hardware implementation. In this paper, we present a deep learning approach to obtain very sparse ternary projections for compressed sensing. Our deep learning architecture jointly learns a pair of a projection matrix and a reconstruction operator in an end-to-end fashion. The experimental results on real images demonstrate the effectiveness of the proposed approach compared to state-of-the-art methods, with significant advantage in terms of complexity.
Incorporating Prior Information in Compressive Online Robust Principal Component Analysis
May 27, 2017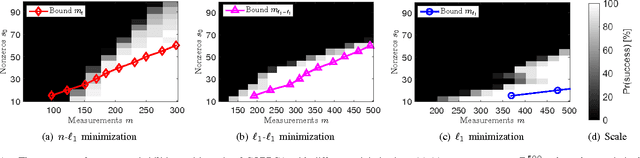
We consider an online version of the robust Principle Component Analysis (PCA), which arises naturally in time-varying source separations such as video foreground-background separation. This paper proposes a compressive online robust PCA with prior information for recursively separating a sequences of frames into sparse and low-rank components from a small set of measurements. In contrast to conventional batch-based PCA, which processes all the frames directly, the proposed method processes measurements taken from each frame. Moreover, this method can efficiently incorporate multiple prior information, namely previous reconstructed frames, to improve the separation and thereafter, update the prior information for the next frame. We utilize multiple prior information by solving $n\text{-}\ell_{1}$ minimization for incorporating the previous sparse components and using incremental singular value decomposition ($\mathrm{SVD}$) for exploiting the previous low-rank components. We also establish theoretical bounds on the number of measurements required to guarantee successful separation under assumptions of static or slowly-changing low-rank components. Using numerical experiments, we evaluate our bounds and the performance of the proposed algorithm. In addition, we apply the proposed algorithm to online video foreground and background separation from compressive measurements. Experimental results show that the proposed method outperforms the existing methods.
Measurement Bounds for Sparse Signal Reconstruction with Multiple Side Information
Jan 18, 2017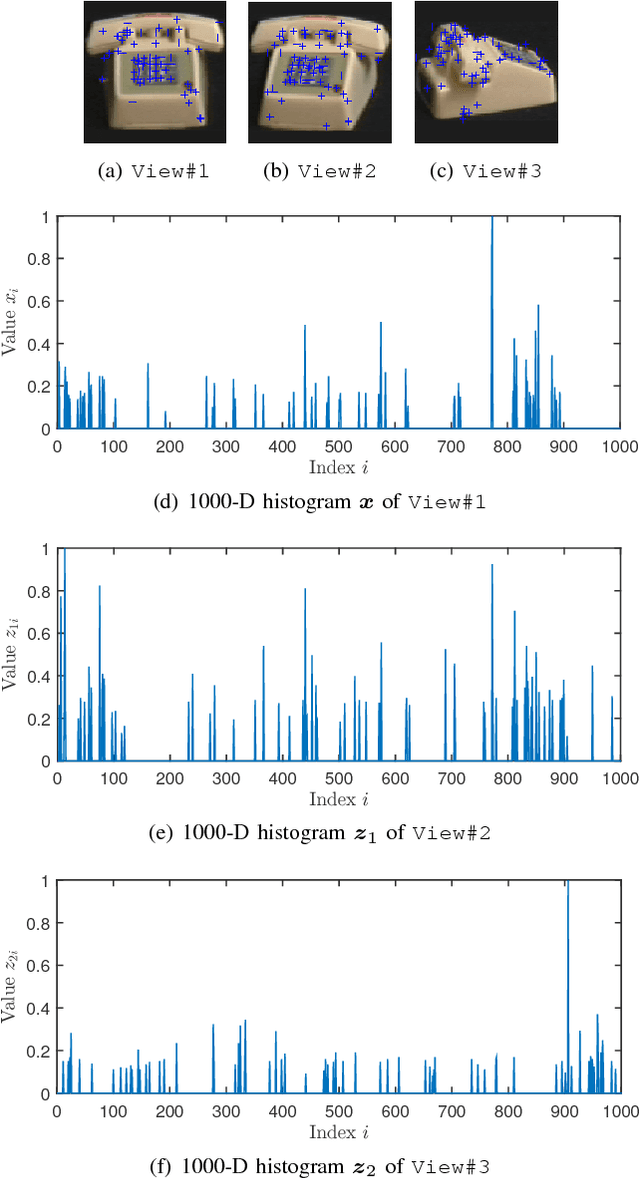
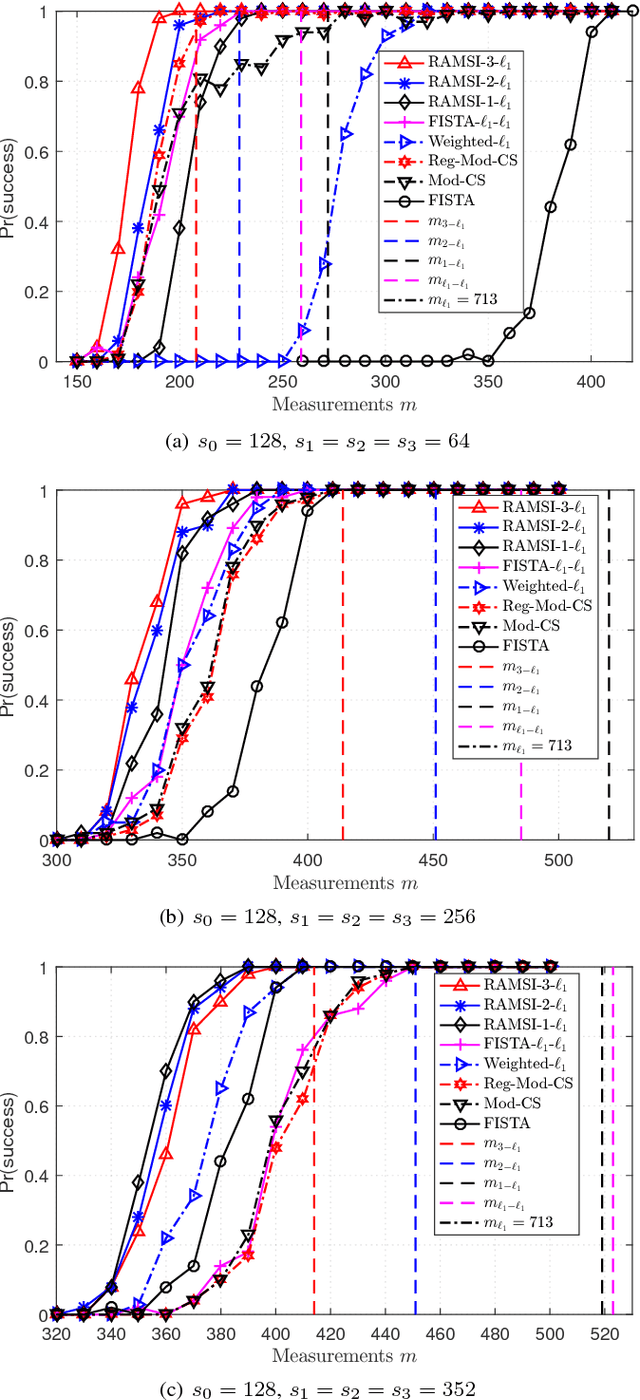
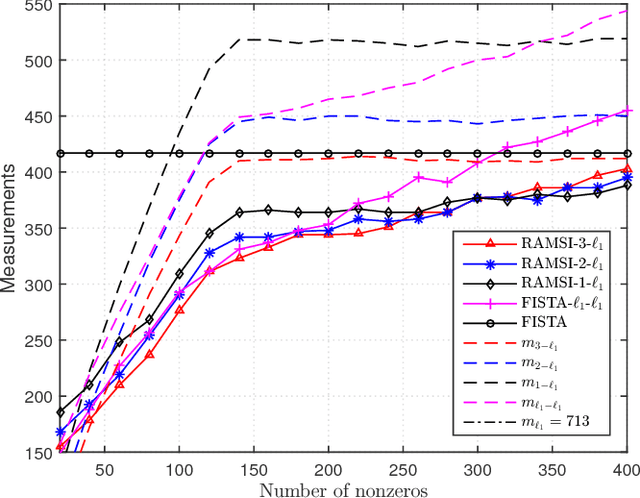
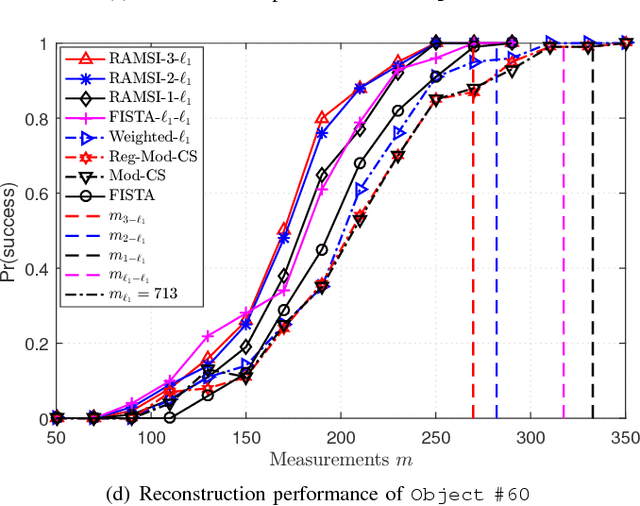
In the context of compressed sensing (CS), this paper considers the problem of reconstructing sparse signals with the aid of other given correlated sources as multiple side information. To address this problem, we theoretically study a generic \textcolor{black}{weighted $n$-$\ell_{1}$ minimization} framework and propose a reconstruction algorithm that leverages multiple side information signals (RAMSI). The proposed RAMSI algorithm computes adaptively optimal weights among the side information signals at every reconstruction iteration. In addition, we establish theoretical bounds on the number of measurements that are required to successfully reconstruct the sparse source by using \textcolor{black}{weighted $n$-$\ell_{1}$ minimization}. The analysis of the established bounds reveal that \textcolor{black}{weighted $n$-$\ell_{1}$ minimization} can achieve sharper bounds and significant performance improvements compared to classical CS. We evaluate experimentally the proposed RAMSI algorithm and the established bounds using synthetic sparse signals as well as correlated feature histograms, extracted from a multiview image database for object recognition. The obtained results show clearly that the proposed algorithm outperforms state-of-the-art algorithms---\textcolor{black}{including classical CS, $\ell_1\text{-}\ell_1$ minimization, Modified-CS, regularized Modified-CS, and weighted $\ell_1$ minimization}---in terms of both the theoretical bounds and the practical performance.
Distributed Coding of Multiview Sparse Sources with Joint Recovery
Jul 18, 2016


In support of applications involving multiview sources in distributed object recognition using lightweight cameras, we propose a new method for the distributed coding of sparse sources as visual descriptor histograms extracted from multiview images. The problem is challenging due to the computational and energy constraints at each camera as well as the limitations regarding inter-camera communication. Our approach addresses these challenges by exploiting the sparsity of the visual descriptor histograms as well as their intra- and inter-camera correlations. Our method couples distributed source coding of the sparse sources with a new joint recovery algorithm that incorporates multiple side information signals, where prior knowledge (low quality) of all the sparse sources is initially sent to exploit their correlations. Experimental evaluation using the histograms of shift-invariant feature transform (SIFT) descriptors extracted from multiview images shows that our method leads to bit-rate saving of up to 43% compared to the state-of-the-art distributed compressed sensing method with independent encoding of the sources.
Multi-modal dictionary learning for image separation with application in art investigation
Jul 14, 2016
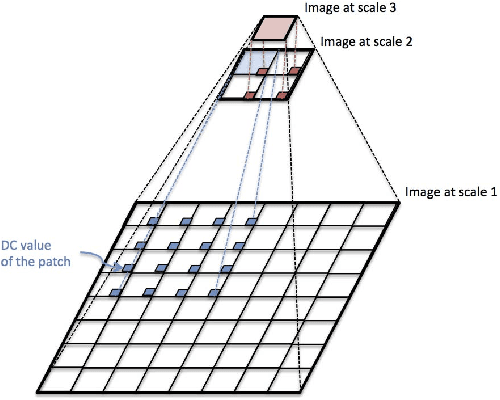


In support of art investigation, we propose a new source separation method that unmixes a single X-ray scan acquired from double-sided paintings. In this problem, the X-ray signals to be separated have similar morphological characteristics, which brings previous source separation methods to their limits. Our solution is to use photographs taken from the front and back-side of the panel to drive the separation process. The crux of our approach relies on the coupling of the two imaging modalities (photographs and X-rays) using a novel coupled dictionary learning framework able to capture both common and disparate features across the modalities using parsimonious representations; the common component models features shared by the multi-modal images, whereas the innovation component captures modality-specific information. As such, our model enables the formulation of appropriately regularized convex optimization procedures that lead to the accurate separation of the X-rays. Our dictionary learning framework can be tailored both to a single- and a multi-scale framework, with the latter leading to a significant performance improvement. Moreover, to improve further on the visual quality of the separated images, we propose to train coupled dictionaries that ignore certain parts of the painting corresponding to craquelure. Experimentation on synthetic and real data - taken from digital acquisition of the Ghent Altarpiece (1432) - confirms the superiority of our method against the state-of-the-art morphological component analysis technique that uses either fixed or trained dictionaries to perform image separation.
X-ray image separation via coupled dictionary learning
May 20, 2016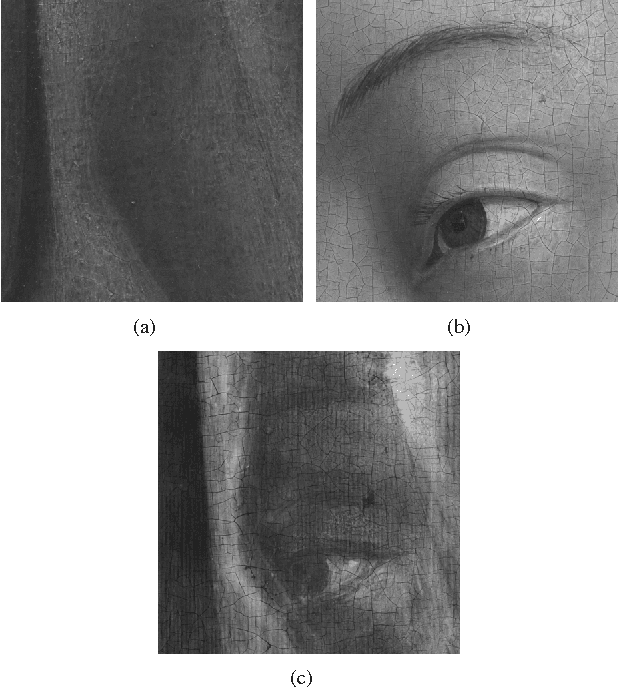
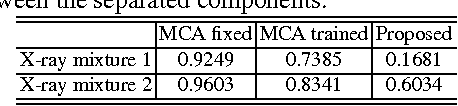
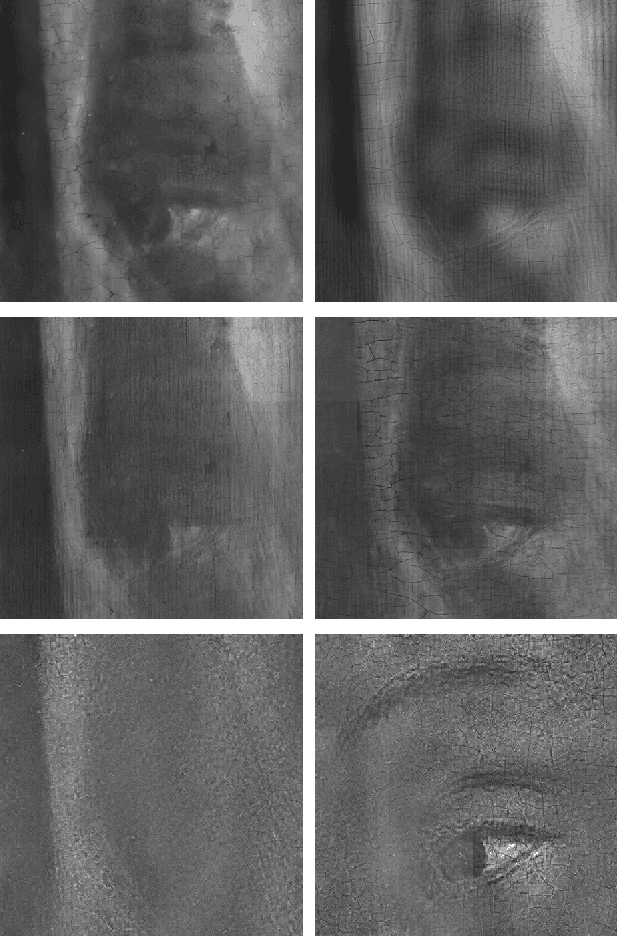
In support of art investigation, we propose a new source sepa- ration method that unmixes a single X-ray scan acquired from double-sided paintings. Unlike prior source separation meth- ods, which are based on statistical or structural incoherence of the sources, we use visual images taken from the front- and back-side of the panel to drive the separation process. The coupling of the two imaging modalities is achieved via a new multi-scale dictionary learning method. Experimental results demonstrate that our method succeeds in the discrimination of the sources, while state-of-the-art methods fail to do so.
Vectors of Locally Aggregated Centers for Compact Video Representation
Sep 13, 2015


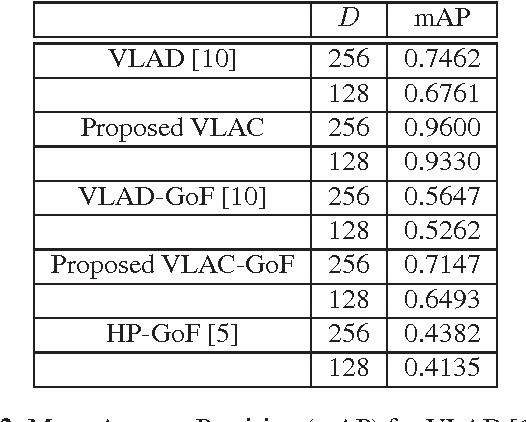
We propose a novel vector aggregation technique for compact video representation, with application in accurate similarity detection within large video datasets. The current state-of-the-art in visual search is formed by the vector of locally aggregated descriptors (VLAD) of Jegou et. al. VLAD generates compact video representations based on scale-invariant feature transform (SIFT) vectors (extracted per frame) and local feature centers computed over a training set. With the aim to increase robustness to visual distortions, we propose a new approach that operates at a coarser level in the feature representation. We create vectors of locally aggregated centers (VLAC) by first clustering SIFT features to obtain local feature centers (LFCs) and then encoding the latter with respect to given centers of local feature centers (CLFCs), extracted from a training set. The sum-of-differences between the LFCs and the CLFCs are aggregated to generate an extremely-compact video description used for accurate video segment similarity detection. Experimentation using a video dataset, comprising more than 1000 minutes of content from the Open Video Project, shows that VLAC obtains substantial gains in terms of mean Average Precision (mAP) against VLAD and the hyper-pooling method of Douze et. al., under the same compaction factor and the same set of distortions.
Adaptive-Rate Sparse Signal Reconstruction With Application in Compressive Background Subtraction
Mar 11, 2015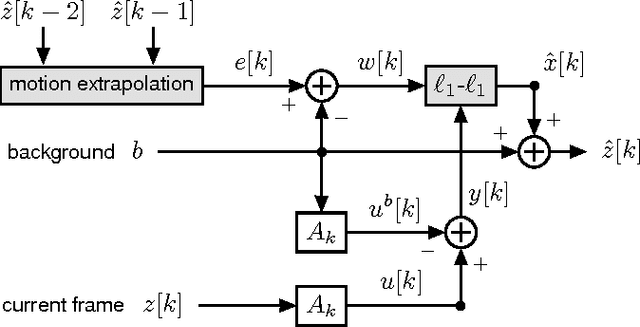
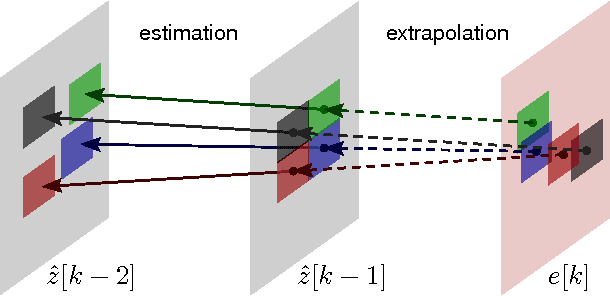

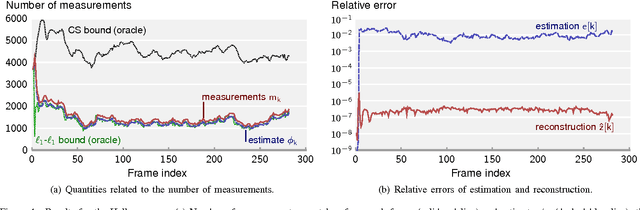
We propose and analyze an online algorithm for reconstructing a sequence of signals from a limited number of linear measurements. The signals are assumed sparse, with unknown support, and evolve over time according to a generic nonlinear dynamical model. Our algorithm, based on recent theoretical results for $\ell_1$-$\ell_1$ minimization, is recursive and computes the number of measurements to be taken at each time on-the-fly. As an example, we apply the algorithm to compressive video background subtraction, a problem that can be stated as follows: given a set of measurements of a sequence of images with a static background, simultaneously reconstruct each image while separating its foreground from the background. The performance of our method is illustrated on sequences of real images: we observe that it allows a dramatic reduction in the number of measurements with respect to state-of-the-art compressive background subtraction schemes.