 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable-by-design Semi-Supervised Representation Learning for COVID-19 Diagnosis from CT Imaging
Dec 02, 2020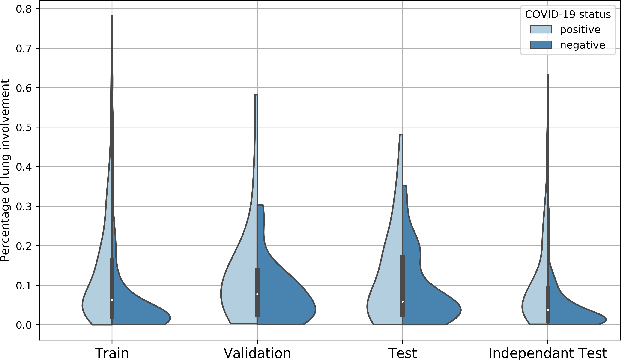
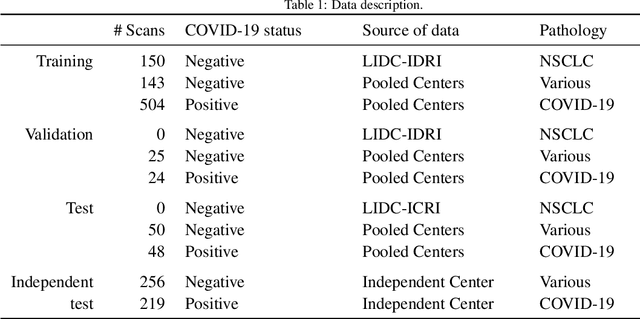
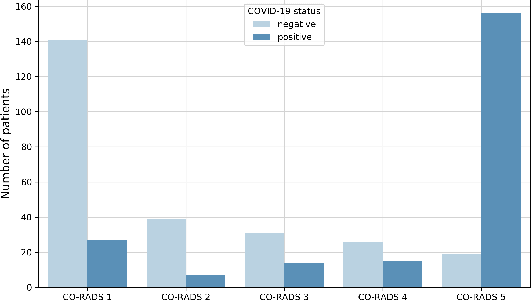
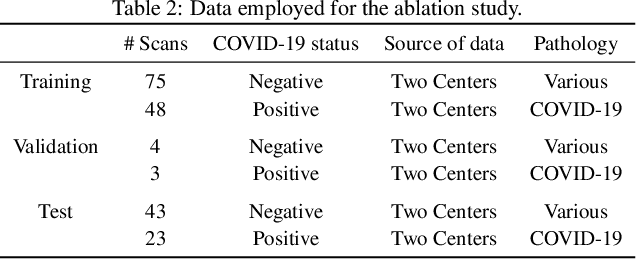
Our motivating application is a real-world problem: COVID-19 classification from CT imaging, for which we present an explainable Deep Learning approach based on a semi-supervised classification pipeline that employs variational autoencoders to extract efficient feature embedding. We have optimized the architecture of two different networks for CT images: (i) a novel conditional variational autoencoder (CVAE) with a specific architecture that integrates the class labels inside the encoder layers and uses side information with shared attention layers for the encoder, which make the most of the contextual clues for representation learning, and (ii) a downstream convolutional neural network for supervised classification using the encoder structure of the CVAE. With the explainable classification results, the proposed diagnosis system is very effective for COVID-19 classification. Based on the promising results obtained qualitatively and quantitatively, we envisage a wide deployment of our developed technique in large-scale clinical studies.Code is available at https://git.etrovub.be/AVSP/ct-based-covid-19-diagnostic-tool.git.
A Review on Fact Extraction and VERification: The FEVER case
Oct 19, 2020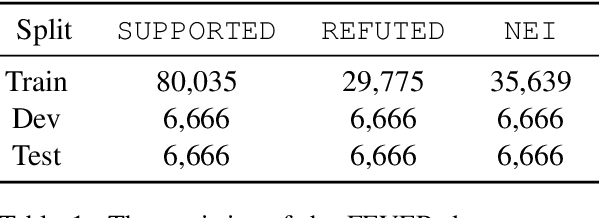
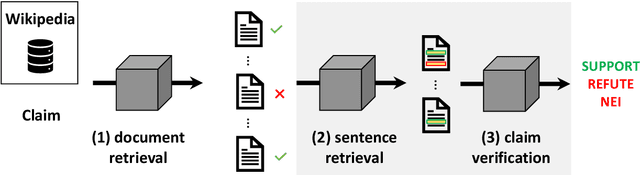
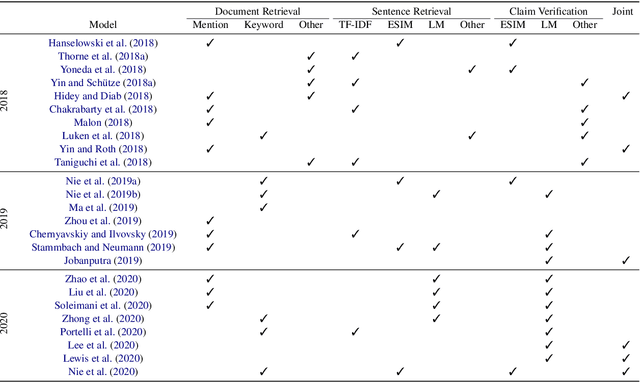
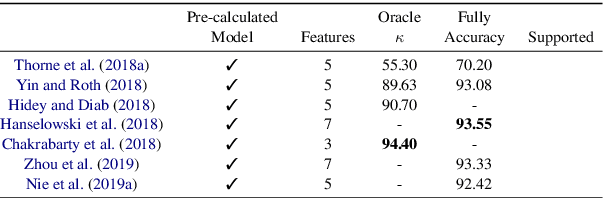
Fact Extraction and VERification (FEVER) is a recently introduced task which aims to identify the veracity of a given claim based on Wikipedia documents. A lot of methods have been proposed to address this problem which consists of the subtasks of (i) retrieving the relevant documents (and sentences) from Wikipedia and (ii) validating whether the information in the documents supports or refutes a given claim. This task is essential since it can be the building block of applications that require a deep understanding of the language such as fake news detection and medical claim verification. In this paper, we aim to get a better understanding of the challenges in the task by presenting the literature in a structured and comprehensive way. In addition, we describe the proposed methods by analyzing the technical perspectives of the different approaches and discussing the performance results on the FEVER dataset.
Temporal Collaborative Filtering with Graph Convolutional Neural Networks
Oct 13, 2020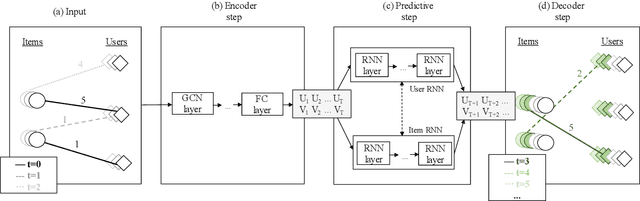
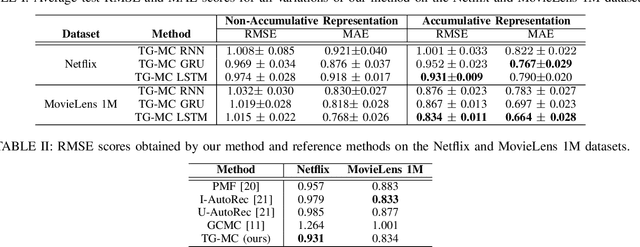
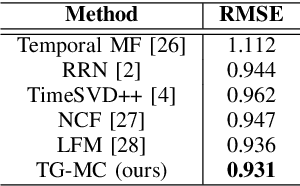
Temporal collaborative filtering (TCF) methods aim at modelling non-static aspects behind recommender systems, such as the dynamics in users' preferences and social trends around items. State-of-the-art TCF methods employ recurrent neural networks (RNNs) to model such aspects. These methods deploy matrix-factorization-based (MF-based) approaches to learn the user and item representations. Recently, graph-neural-network-based (GNN-based) approaches have shown improved performance in providing accurate recommendations over traditional MF-based approaches in non-temporal CF settings. Motivated by this, we propose a novel TCF method that leverages GNNs to learn user and item representations, and RNNs to model their temporal dynamics. A challenge with this method lies in the increased data sparsity, which negatively impacts obtaining meaningful quality representations with GNNs. To overcome this challenge, we train a GNN model at each time step using a set of observed interactions accumulated time-wise. Comprehensive experiments on real-world data show the improved performance obtained by our method over several state-of-the-art temporal and non-temporal CF models.
A Deep-Unfolded Reference-Based RPCA Network For Video Foreground-Background Separation
Oct 02, 2020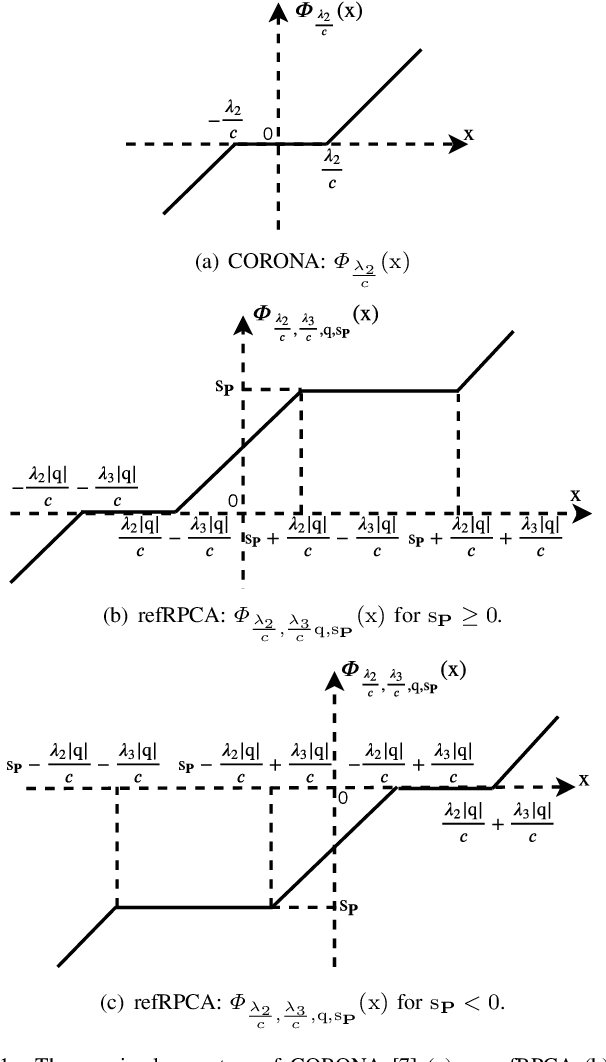
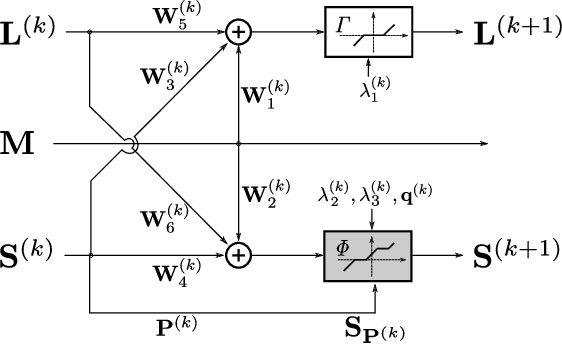
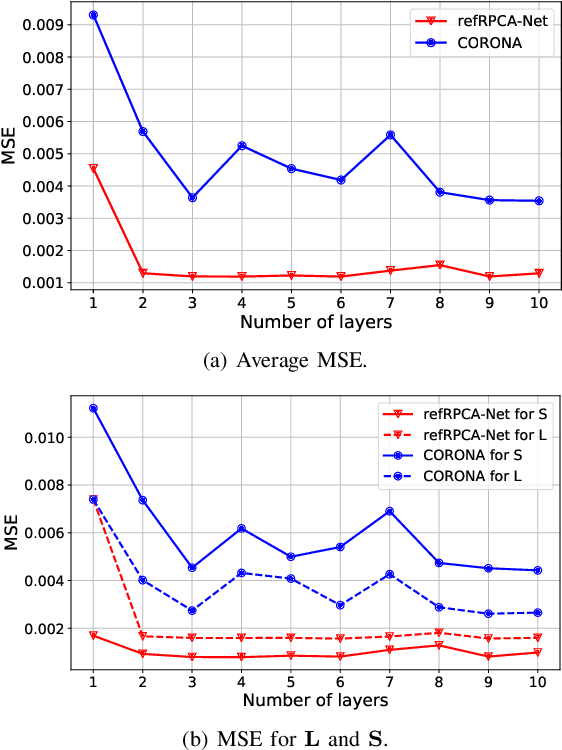

Deep unfolded neural networks are designed by unrolling the iterations of optimization algorithms. They can be shown to achieve faster convergence and higher accuracy than their optimization counterparts. This paper proposes a new deep-unfolding-based network design for the problem of Robust Principal Component Analysis (RPCA) with application to video foreground-background separation. Unlike existing designs, our approach focuses on modeling the temporal correlation between the sparse representations of consecutive video frames. To this end, we perform the unfolding of an iterative algorithm for solving reweighted $\ell_1$-$\ell_1$ minimization; this unfolding leads to a different proximal operator (a.k.a. different activation function) adaptively learned per neuron. Experimentation using the moving MNIST dataset shows that the proposed network outperforms a recently proposed state-of-the-art RPCA network in the task of video foreground-background separation.
Interpretable Deep Multimodal Image Super-Resolution
Sep 07, 2020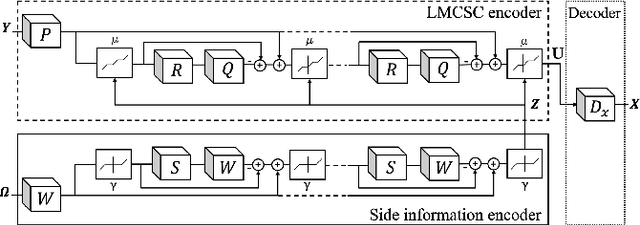
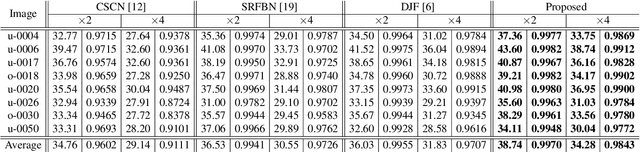

Multimodal image super-resolution (SR) is the reconstruction of a high resolution image given a low-resolution observation with the aid of another image modality. While existing deep multimodal models do not incorporate domain knowledge about image SR, we present a multimodal deep network design that integrates coupled sparse priors and allows the effective fusion of information from another modality into the reconstruction process. Our method is inspired by a novel iterative algorithm for coupled convolutional sparse coding, resulting in an interpretable network by design. We apply our model to the super-resolution of near-infrared image guided by RGB images. Experimental results show that our model outperforms state-of-the-art methods.
Graph Convolutional Neural Networks with Node Transition Probability-based Message Passing and DropNode Regularization
Aug 28, 2020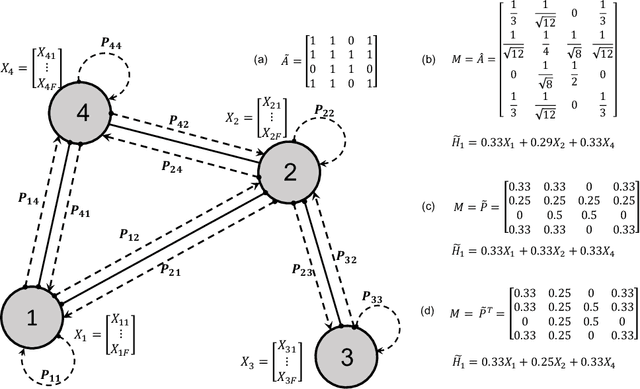
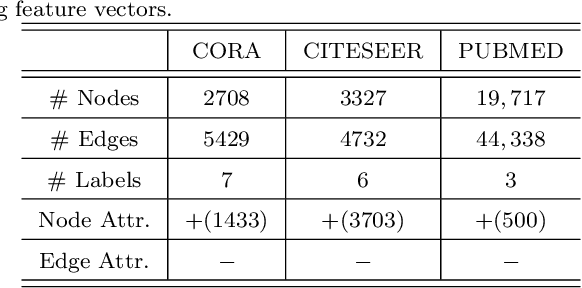
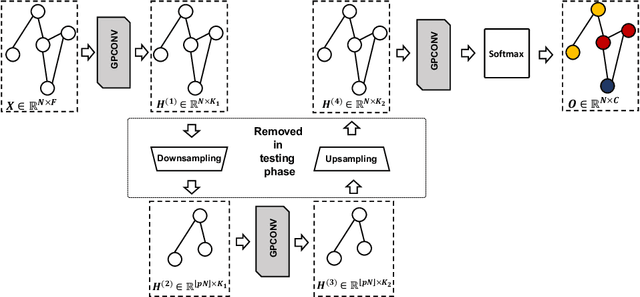
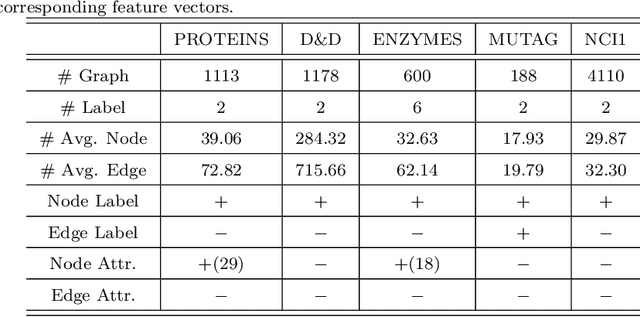
Graph convolutional neural networks (GCNNs) have received much attention recently, owing to their capability in handling graph-structured data. Among the existing GCNNs, many methods can be viewed as instances of a neural message passing motif; features of nodes are passed around their neighbors, aggregated and transformed to produce better nodes' representations. Nevertheless, these methods seldom use node transition probabilities, a measure that has been found useful in exploring graphs. Furthermore, when the transition probabilities are used, their transition direction is often improperly considered in the feature aggregation step, resulting in an inefficient weighting scheme. In addition, although a great number of GCNN models with increasing level of complexity have been introduced, the GCNNs often suffer from over-fitting when being trained on small graphs. Another issue of the GCNNs is over-smoothing, which tends to make nodes' representations indistinguishable. This work presents a new method to improve the message passing process based on node transition probabilities by properly considering the transition direction, leading to a better weighting scheme in nodes' features aggregation compared to the existing counterpart. Moreover, we propose a novel regularization method termed DropNode to address the over-fitting and over-smoothing issues simultaneously. DropNode randomly discards part of a graph, thus it creates multiple deformed versions of the graph, leading to data augmentation regularization effect. Additionally, DropNode lessens the connectivity of the graph, mitigating the effect of over-smoothing in deep GCNNs. Extensive experiments on eight benchmark datasets for node and graph classification tasks demonstrate the effectiveness of the proposed methods in comparison with the state of the art.
Interpretable Deep Recurrent Neural Networks via Unfolding Reweighted $\ell_1$-$\ell_1$ Minimization: Architecture Design and Generalization Analysis
Mar 18, 2020



Deep unfolding methods---for example, the learned iterative shrinkage thresholding algorithm (LISTA)---design deep neural networks as learned variations of optimization methods. These networks have been shown to achieve faster convergence and higher accuracy than the original optimization methods. In this line of research, this paper develops a novel deep recurrent neural network (coined reweighted-RNN) by the unfolding of a reweighted $\ell_1$-$\ell_1$ minimization algorithm and applies it to the task of sequential signal reconstruction. To the best of our knowledge, this is the first deep unfolding method that explores reweighted minimization. Due to the underlying reweighted minimization model, our RNN has a different soft-thresholding function (alias, different activation functions) for each hidden unit in each layer. Furthermore, it has higher network expressivity than existing deep unfolding RNN models due to the over-parameterizing weights. Importantly, we establish theoretical generalization error bounds for the proposed reweighted-RNN model by means of Rademacher complexity. The bounds reveal that the parameterization of the proposed reweighted-RNN ensures good generalization. We apply the proposed reweighted-RNN to the problem of video frame reconstruction from low-dimensional measurements, that is, sequential frame reconstruction. The experimental results on the moving MNIST dataset demonstrate that the proposed deep reweighted-RNN significantly outperforms existing RNN models.
Multimodal Deep Unfolding for Guided Image Super-Resolution
Jan 21, 2020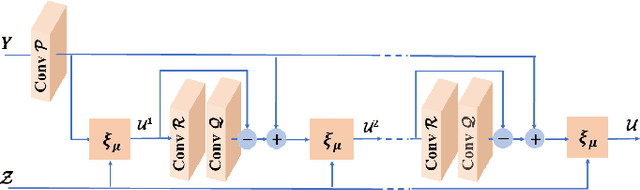
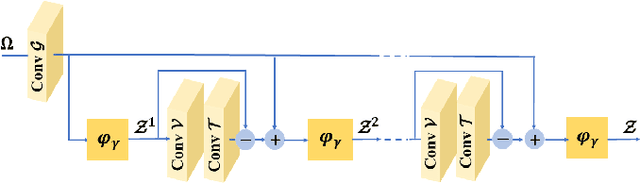
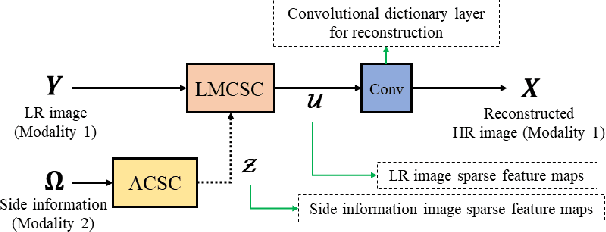
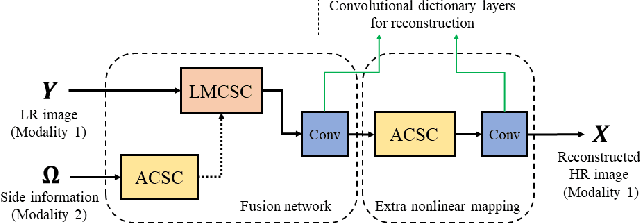
The reconstruction of a high resolution image given a low resolution observation is an ill-posed inverse problem in imaging. Deep learning methods rely on training data to learn an end-to-end mapping from a low-resolution input to a high-resolution output. Unlike existing deep multimodal models that do not incorporate domain knowledge about the problem, we propose a multimodal deep learning design that incorporates sparse priors and allows the effective integration of information from another image modality into the network architecture. Our solution relies on a novel deep unfolding operator, performing steps similar to an iterative algorithm for convolutional sparse coding with side information; therefore, the proposed neural network is interpretable by design. The deep unfolding architecture is used as a core component of a multimodal framework for guided image super-resolution. An alternative multimodal design is investigated by employing residual learning to improve the training efficiency. The presented multimodal approach is applied to super-resolution of near-infrared and multi-spectral images as well as depth upsampling using RGB images as side information. Experimental results show that our model outperforms state-of-the-art methods.
DeepFPC: Deep Unfolding of a Fixed-Point Continuation Algorithm for Sparse Signal Recovery from Quantized Measurements
Dec 04, 2019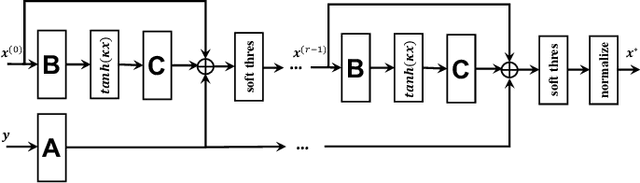
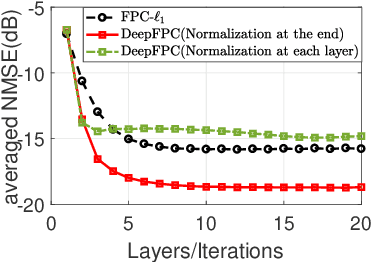
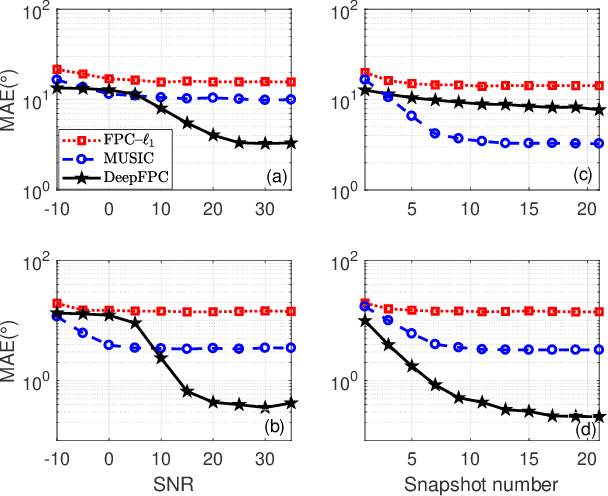
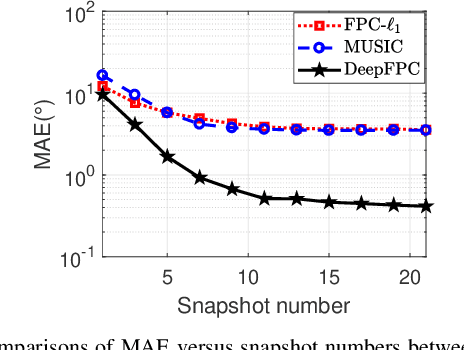
We present DeepFPC, a novel deep neural network designed by unfolding the iterations of the fixed-point continuation algorithm with one-sided l1-norm (FPC-l1), which has been proposed for solving the 1-bit compressed sensing problem. The network architecture resembles that of deep residual learning and incorporates prior knowledge about the signal structure (i.e., sparsity), thereby offering interpretability by design. Once DeepFPC is properly trained, a sparse signal can be recovered fast and accurately from quantized measurements. The proposed model is evaluated in the task of direction-of-arrival (DOA) estimation and is shown to outperform state-of-the-art algorithms, namely, the iterative FPC-l1 algorithm and the 1-bit MUSIC method.
Multimodal Image Super-resolution via Deep Unfolding with Side Information
Oct 18, 2019
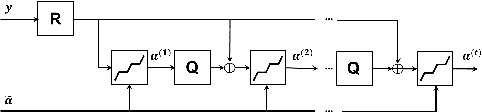
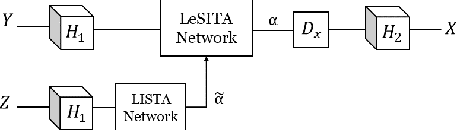
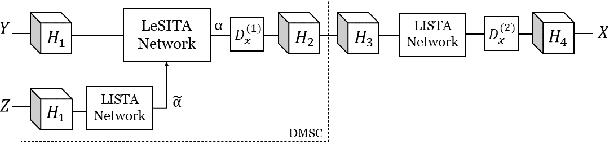
Deep learning methods have been successfully applied to various computer vision tasks. However, existing neural network architectures do not per se incorporate domain knowledge about the addressed problem, thus, understanding what the model has learned is an open research topic. In this paper, we rely on the unfolding of an iterative algorithm for sparse approximation with side information, and design a deep learning architecture for multimodal image super-resolution that incorporates sparse priors and effectively utilizes information from another image modality. We develop two deep models performing reconstruction of a high-resolution image of a target image modality from its low-resolution variant with the aid of a high-resolution image from a second modality. We apply the proposed models to super-resolve near-infrared images using as side information high-resolution RGB\ images. Experimental results demonstrate the superior performance of the proposed models against state-of-the-art methods including unimodal and multimodal approaches.