 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online Learning in Interacting Particle Systems
Feb 24, 2026We introduce a new method for online parameter estimation in stochastic interacting particle systems, based on continuous observation of a small number of particles from the system. Our method recursively updates the model parameters using a stochastic approximation of the gradient of the asymptotic log likelihood, which is computed using the continuous stream of observations. Under suitable assumptions, we rigorously establish convergence of our method to the stationary points of the asymptotic log-likelihood of the interacting particle system. We consider asymptotics both in the limit as the time horizon $t\rightarrow\infty$, for a fixed and finite number of particles, and in the joint limit as the number of particles $N\rightarrow\infty$ and the time horizon $t\rightarrow\infty$. Under additional assumptions on the asymptotic log-likelihood, we also establish an $\mathrm{L}^2$ convergence rate and a central limit theorem. Finally, we present several numerical examples of practical interest, including a model for systemic risk, a model of interacting FitzHugh--Nagumo neurons, and a Cucker--Smale flocking model. Our numerical results corroborate our theoretical results, and also suggest that our estimator is effective even in cases where the assumptions required for our theoretical analysis do not hold.
Scalarisation-based risk concepts for robust multi-objective optimisation
May 16, 2024Robust optimisation is a well-established framework for optimising functions in the presence of uncertainty. The inherent goal of this problem is to identify a collection of inputs whose outputs are both desirable for the decision maker, whilst also being robust to the underlying uncertainties in the problem. In this work, we study the multi-objective extension of this problem from a computational standpoint. We identify that the majority of all robust multi-objective algorithms rely on two key operations: robustification and scalarisation. Robustification refers to the strategy that is used to marginalise over the uncertainty in the problem. Whilst scalarisation refers to the procedure that is used to encode the relative importance of each objective. As these operations are not necessarily commutative, the order that they are performed in has an impact on the resulting solutions that are identified and the final decisions that are made. This work aims to give an exposition on the philosophical differences between these two operations and highlight when one should opt for one ordering over the other. As part of our analysis, we showcase how many existing risk concepts can be easily integrated into the specification and solution of a robust multi-objective optimisation problem. Besides this, we also demonstrate how one can principally define the notion of a robust Pareto front and a robust performance metric based on our robustify and scalarise methodology. To illustrate the efficacy of these new ideas, we present two insightful numerical case studies which are based on real-world data sets.
Random Pareto front surfaces
May 02, 2024The Pareto front of a set of vectors is the subset which is comprised solely of all of the best trade-off points. By interpolating this subset, we obtain the optimal trade-off surface. In this work, we prove a very useful result which states that all Pareto front surfaces can be explicitly parametrised using polar coordinates. In particular, our polar parametrisation result tells us that we can fully characterise any Pareto front surface using the length function, which is a scalar-valued function that returns the projected length along any positive radial direction. Consequently, by exploiting this representation, we show how it is possible to generalise many useful concepts from linear algebra, probability and statistics, and decision theory to function over the space of Pareto front surfaces. Notably, we focus our attention on the stochastic setting where the Pareto front surface itself is a stochastic process. Among other things, we showcase how it is possible to define and estimate many statistical quantities of interest such as the expectation, covariance and quantile of any Pareto front surface distribution. As a motivating example, we investigate how these statistics can be used within a design of experiments setting, where the goal is to both infer and use the Pareto front surface distribution in order to make effective decisions. Besides this, we also illustrate how these Pareto front ideas can be used within the context of extreme value theory. Finally, as a numerical example, we applied some of our new methodology on a real-world air pollution data set.
Multi-Objective Optimization Using the R2 Utility
May 19, 2023



The goal of multi-objective optimization is to identify a collection of points which describe the best possible trade-offs between the multiple objectives. In order to solve this vector-valued optimization problem, practitioners often appeal to the use of scalarization functions in order to transform the multi-objective problem into a collection of single-objective problems. This set of scalarized problems can then be solved using traditional single-objective optimization techniques. In this work, we formalise this convention into a general mathematical framework. We show how this strategy effectively recasts the original multi-objective optimization problem into a single-objective optimization problem defined over sets. An appropriate class of objective functions for this new problem is the R2 utility function, which is defined as a weighted integral over the scalarized optimization problems. We show that this utility function is a monotone and submodular set function, which can be optimised effectively using greedy optimization algorithms. We analyse the performance of these greedy algorithms both theoretically and empirically. Our analysis largely focusses on Bayesian optimization, which is a popular probabilistic framework for black-box optimization.
Privacy Risk for anisotropic Langevin dynamics using relative entropy bounds
Feb 01, 2023The privacy preserving properties of Langevin dynamics with additive isotropic noise have been extensively studied. However, the isotropic noise assumption is very restrictive: (a) when adding noise to existing learning algorithms to preserve privacy and maintain the best possible accuracy one should take into account the relative magnitude of the outputs and their correlations; (b) popular algorithms such as stochastic gradient descent (and their continuous time limits) appear to possess anisotropic covariance properties. To study the privacy risks for the anisotropic noise case, one requires general results on the relative entropy between the laws of two Stochastic Differential Equations with different drifts and diffusion coefficients. Our main contribution is to establish such a bound using stability estimates for solutions to the Fokker-Planck equations via functional inequalities. With additional assumptions, the relative entropy bound implies an $(\epsilon,\delta)$-differential privacy bound. We discuss the practical implications of our bound related to privacy risk in different contexts.Finally, the benefits of anisotropic noise are illustrated using numerical results on optimising a quadratic loss or calibrating a neural network.
Joint Entropy Search for Multi-objective Bayesian Optimization
Oct 06, 2022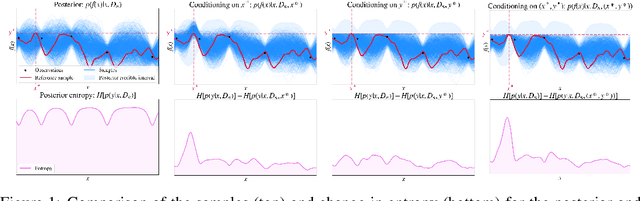

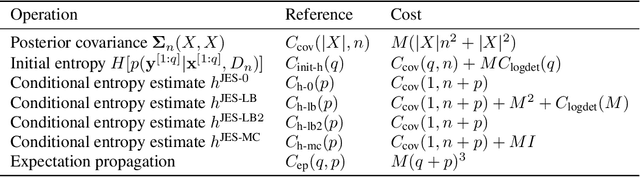
Many real-world problems can be phrased as a multi-objective optimization problem, where the goal is to identify the best set of compromises between the competing objectives. Multi-objective Bayesian optimization (BO) is a sample efficient strategy that can be deployed to solve these vector-valued optimization problems where access is limited to a number of noisy objective function evaluations. In this paper, we propose a novel information-theoretic acquisition function for BO called Joint Entropy Search (JES), which considers the joint information gain for the optimal set of inputs and outputs. We present several analytical approximations to the JES acquisition function and also introduce an extension to the batch setting. We showcase the effectiveness of this new approach on a range of synthetic and real-world problems in terms of the hypervolume and its weighted variants.
On stochastic mirror descent with interacting particles: convergence properties and variance reduction
Jul 15, 2020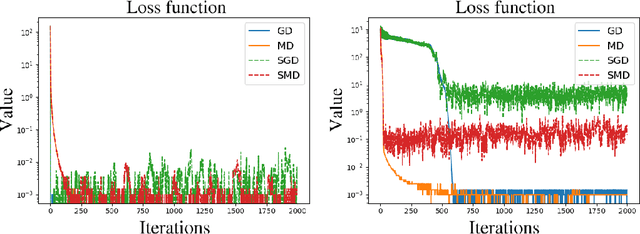
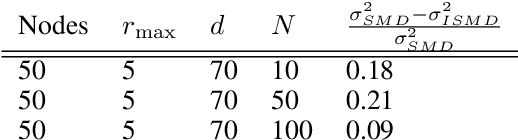
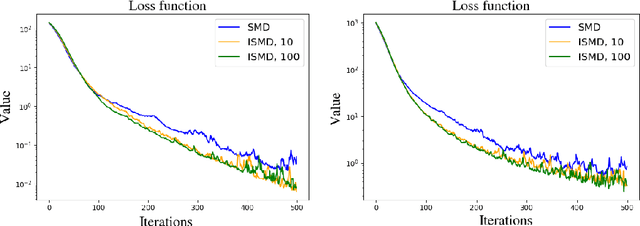
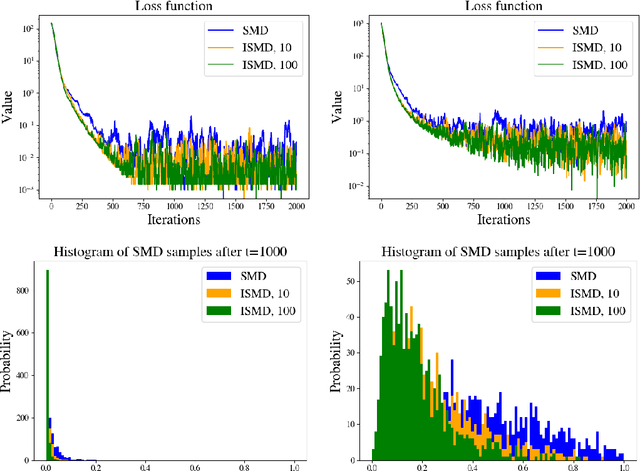
An open problem in optimization with noisy information is the computation of an exact minimizer that is independent of the amount of noise. A standard practice in stochastic approximation algorithms is to use a decreasing step-size. However, to converge the step-size must decrease exponentially slow, and therefore this approach is not useful in practice. A second alternative is to use a fixed step-size and run independent replicas of the algorithm and average these. A third option is to run replicas of the algorithm and allow them to interact. It is unclear which of these options works best. To address this question, we reduce the problem of the computation of an exact minimizer with noisy gradient information to the study of stochastic mirror descent with interacting particles. We study the convergence of stochastic mirror descent and make explicit the tradeoffs between communication and variance reduction. We provide theoretical and numerical evidence to suggest that interaction helps to improve convergence and reduce the variance of the estimate.
The sharp, the flat and the shallow: Can weakly interacting agents learn to escape bad minima?
May 10, 2019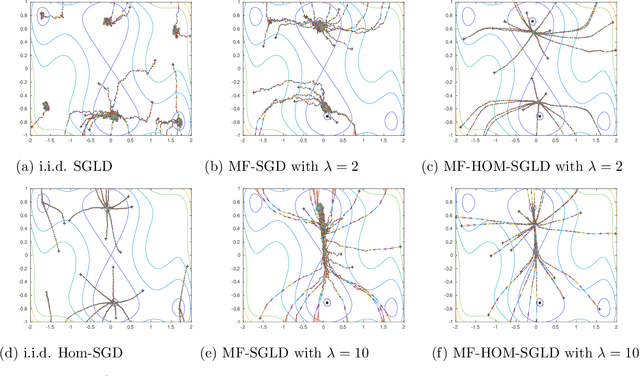
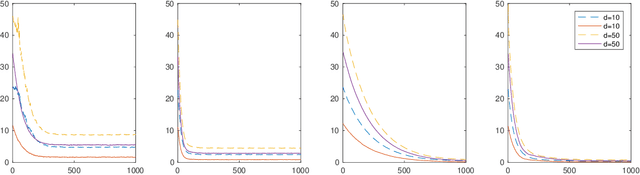
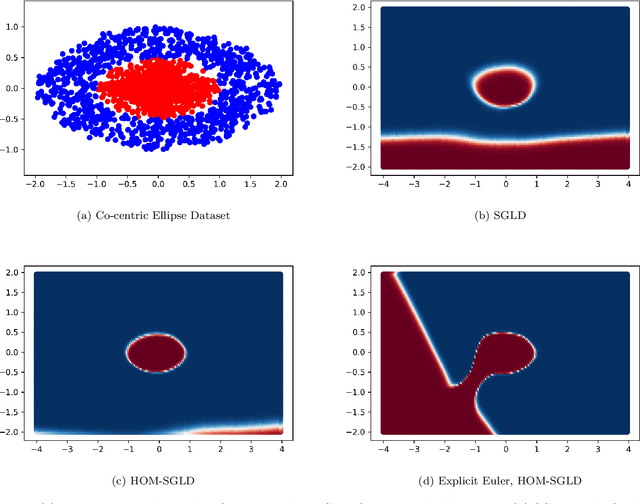
An open problem in machine learning is whether flat minima generalize better and how to compute such minima efficiently. This is a very challenging problem. As a first step towards understanding this question we formalize it as an optimization problem with weakly interacting agents. We review appropriate background material from the theory of stochastic processes and provide insights that are relevant to practitioners. We propose an algorithmic framework for an extended stochastic gradient Langevin dynamics and illustrate its potential. The paper is written as a tutorial, and presents an alternative use of multi-agent learning. Our primary focus is on the design of algorithms for machine learning applications; however the underlying mathematical framework is suitable for the understanding of large scale systems of agent based models that are popular in the social sciences, economics and finance.
On Adaptive Estimation for Dynamic Bernoulli Bandits
May 15, 2018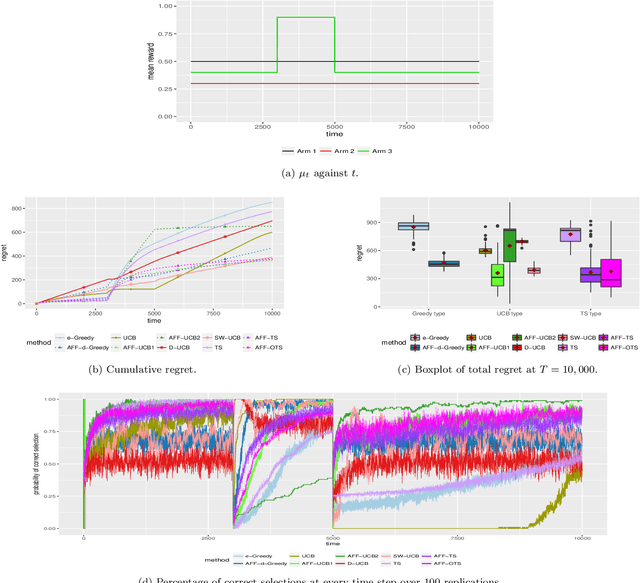

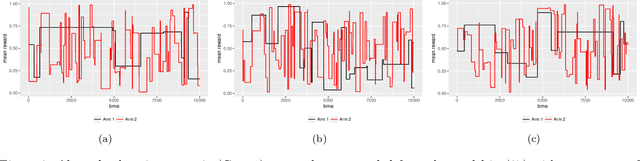
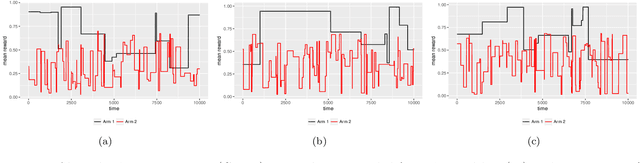
The multi-armed bandit (MAB) problem is a classic example of the exploration-exploitation dilemma. It is concerned with maximising the total rewards for a gambler by sequentially pulling an arm from a multi-armed slot machine where each arm is associated with a reward distribution. In static MABs, the reward distributions do not change over time, while in dynamic MABs, each arm's reward distribution can change, and the optimal arm can switch over time. Motivated by many real applications where rewards are binary, we focus on dynamic Bernoulli bandits. Standard methods like $\epsilon$-Greedy and Upper Confidence Bound (UCB), which rely on the sample mean estimator, often fail to track changes in the underlying reward for dynamic problems. In this paper, we overcome the shortcoming of slow response to change by deploying adaptive estimation in the standard methods and propose a new family of algorithms, which are adaptive versions of $\epsilon$-Greedy, UCB, and Thompson sampling. These new methods are simple and easy to implement. Moreover, they do not require any prior knowledge about the dynamic reward process, which is important for real applications. We examine the new algorithms numerically in different scenarios and the results show solid improvements of our algorithms in dynamic environments.