 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of counteracting vehicles on the characteristics of a smart city transport system
Mar 22, 2022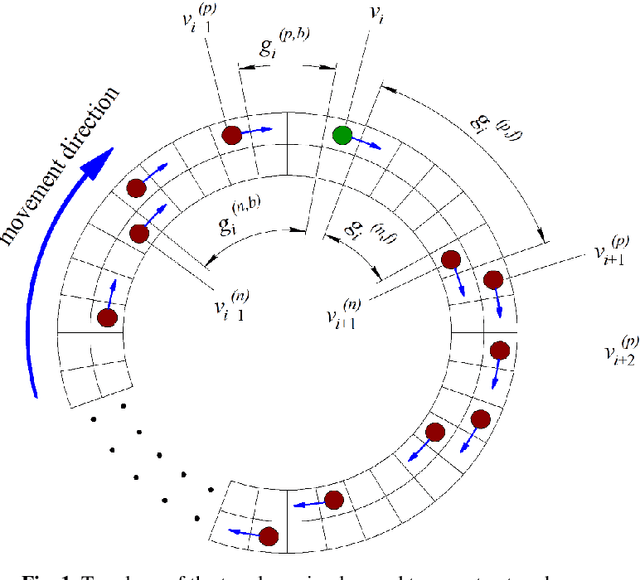

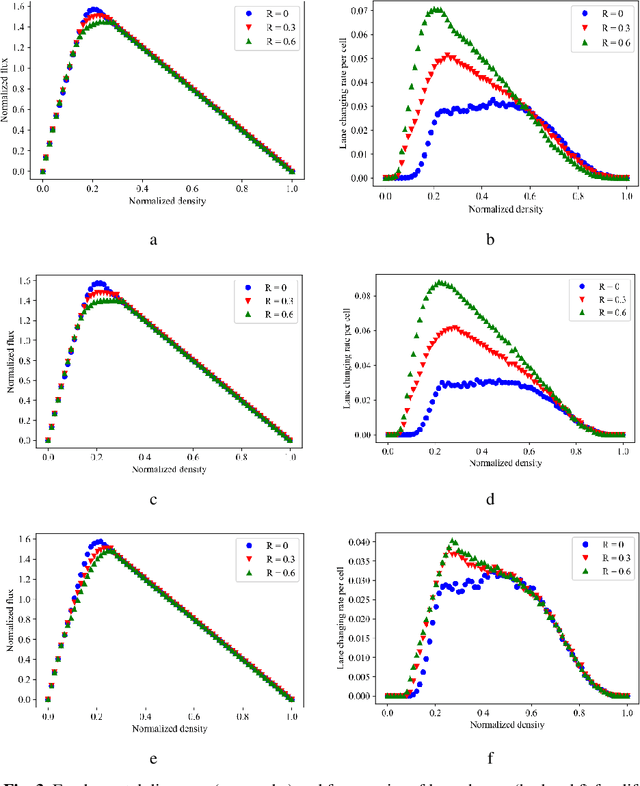
The development of smart city transport systems, including self-driving cars, leads to an increase in the threat of hostile interference in the processes of vehicle control. This interference may disrupt the normal functioning of the transport system, and, if is performed covertly, the system can be negatively affected for a long period of time. This paper develops a simulation stochastic cellular automata model of traffic on a circular two-lane road based on the Sakai-Nishinari-Fukui-Schadschneider (S-NFS) rules. In the presented model, in addition to ordinary vehicles, there are covertly counteracting vehicles; their task is to reduce the quantity indicators (such as traffic flux) of the transport system using special rules of behavior. Three such rules are considered and compared: two lane-changing rules and one slow-down rule. It is shown that such counteracting vehicles can affect the traffic flow, mainly in the region of the maximum of the fundamental diagram, that is, at average values of the vehicle density. In free-flowing traffic or in a traffic jam, the influence of the counteracting vehicle is negligible regardless of its rules of behavior.
Reinforcement learning reward function in unmanned aerial vehicle control tasks
Mar 20, 2022



This paper presents a new reward function that can be used for deep reinforcement learning in unmanned aerial vehicle (UAV) control and navigation problems. The reward function is based on the construction and estimation of the time of simplified trajectories to the target, which are third-order Bezier curves. This reward function can be applied unchanged to solve problems in both two-dimensional and three-dimensional virtual environments. The effectiveness of the reward function was tested in a newly developed virtual environment, namely, a simplified two-dimensional environment describing the dynamics of UAV control and flight, taking into account the forces of thrust, inertia, gravity, and aerodynamic drag. In this formulation, three tasks of UAV control and navigation were successfully solved: UAV flight to a given point in space, avoidance of interception by another UAV, and organization of interception of one UAV by another. The three most relevant modern deep reinforcement learning algorithms, Soft actor-critic, Deep Deterministic Policy Gradient, and Twin Delayed Deep Deterministic Policy Gradient were used. All three algorithms performed well, indicating the effectiveness of the selected reward function.
The Problem of Adhesion Methods and Locomotion Mechanism Development for Wall-Climbing Robots
May 22, 2019



This review considers a problem in the development of mobile robot adhesion methods with vertical surfaces and the appropriate locomotion mechanism design. The evolution of adhesion methods for wall-climbing robots (based on friction, magnetic forces, air pressure, electrostatic adhesion, molecular forces, rheological properties of fluids and their combinations) and their locomotion principles (wheeled, tracked, walking, sliding framed and hybrid) is studied. Wall-climbing robots are classified according to the applications, adhesion methods and locomotion mechanisms. The advantages and disadvantages of various adhesion methods and locomotion mechanisms are analyzed in terms of mobility, noiselessness, autonomy and energy efficiency. Focus is placed on the physical and technical aspects of the adhesion methods and the possibility of combining adhesion and locomotion methods.