 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring possible vector systems for faster training of neural networks with preconfigured latent spaces
Dec 10, 2025



The overall neural network (NN) performance is closely related to the properties of its embedding distribution in latent space (LS). It has recently been shown that predefined vector systems, specifically An root system vectors, can be used as targets for latent space configurations (LSC) to ensure the desired LS structure. One of the main LSC advantage is the possibility of training classifier NNs without classification layers, which facilitates training NNs on datasets with extremely large numbers of classes. This paper provides a more general overview of possible vector systems for NN training along with their properties and methods for vector system construction. These systems are used to configure LS of encoders and visual transformers to significantly speed up ImageNet-1K and 50k-600k classes LSC training. It is also shown that using the minimum number of LS dimensions for a specific number of classes results in faster convergence. The latter has potential advantages for reducing the size of vector databases used to store NN embeddings.
The effects of Hessian eigenvalue spectral density type on the applicability of Hessian analysis to generalization capability assessment of neural networks
Apr 24, 2025



Hessians of neural network (NN) contain essential information about the curvature of NN loss landscapes which can be used to estimate NN generalization capabilities. We have previously proposed generalization criteria that rely on the observation that Hessian eigenvalue spectral density (HESD) behaves similarly for a wide class of NNs. This paper further studies their applicability by investigating factors that can result in different types of HESD. We conduct a wide range of experiments showing that HESD mainly has positive eigenvalues (MP-HESD) for NN training and fine-tuning with various optimizers on different datasets with different preprocessing and augmentation procedures. We also show that mainly negative HESD (MN-HESD) is a consequence of external gradient manipulation, indicating that the previously proposed Hessian analysis methodology cannot be applied in such cases. We also propose criteria and corresponding conditions to determine HESD type and estimate NN generalization potential. These HESD types and previously proposed generalization criteria are combined into a unified HESD analysis methodology. Finally, we discuss how HESD changes during training, and show the occurrence of quasi-singular (QS) HESD and its influence on the proposed methodology and on the conventional assumptions about the relation between Hessian eigenvalues and NN loss landscape curvature.
Investigating generalization capabilities of neural networks by means of loss landscapes and Hessian analysis
Dec 13, 2024



This paper studies generalization capabilities of neural networks (NNs) using new and improved PyTorch library Loss Landscape Analysis (LLA). LLA facilitates visualization and analysis of loss landscapes along with the properties of NN Hessian. Different approaches to NN loss landscape plotting are discussed with particular focus on normalization techniques showing that conventional methods cannot always ensure correct visualization when batch normalization layers are present in NN architecture. The use of Hessian axes is shown to be able to mitigate this effect, and methods for choosing Hessian axes are proposed. In addition, spectra of Hessian eigendecomposition are studied and it is shown that typical spectra exist for a wide range of NNs. This allows to propose quantitative criteria for Hessian analysis that can be applied to evaluate NN performance and assess its generalization capabilities. Generalization experiments are conducted using ImageNet-1K pre-trained models along with several models trained as part of this study. The experiment include training models on one dataset and testing on another one to maximize experiment similarity to model performance in the Wild. It is shown that when datasets change, the changes in criteria correlate with the changes in accuracy, making the proposed criteria a computationally efficient estimate of generalization ability, which is especially useful for extremely large datasets.
Improving analytical color and texture similarity estimation methods for dataset-agnostic person reidentification
Dec 06, 2024



This paper studies a combined person reidentification (re-id) method that uses human parsing, analytical feature extraction and similarity estimation schemes. One of its prominent features is its low computational requirements so it can be implemented on edge devices. The method allows direct comparison of specific image regions using interpretable features which consist of color and texture channels. It is proposed to analyze and compare colors in CIE-Lab color space using histogram smoothing for noise reduction. A novel pre-configured latent space (LS) supervised autoencoder (SAE) is proposed for texture analysis which encodes input textures as LS points. This allows to obtain more accurate similarity measures compared to simplistic label comparison. The proposed method also does not rely upon photos or other re-id data for training, which makes it completely re-id dataset-agnostic. The viability of the proposed method is verified by computing rank-1, rank-10, and mAP re-id metrics on Market1501 dataset. The results are comparable to those of conventional deep learning methods and the potential ways to further improve the method are discussed.
NIDS Neural Networks Using Sliding Time Window Data Processing with Trainable Activations and its Generalization Capability
Oct 24, 2024



This paper presents neural networks for network intrusion detection systems (NIDS), that operate on flow data preprocessed with a time window. It requires only eleven features which do not rely on deep packet inspection and can be found in most NIDS datasets and easily obtained from conventional flow collectors. The time window aggregates information with respect to hosts facilitating the identification of flow signatures that are missed by other aggregation methods. Several network architectures are studied and the use of Kalmogorov-Arnold Network (KAN)-inspired trainable activation functions that help to achieve higher accuracy with simpler network structure is proposed. The reported training accuracy exceeds 99% for the proposed method with as little as twenty neural network input features. This work also studies the generalization capability of NIDS, a crucial aspect that has not been adequately addressed in the previous studies. The generalization experiments are conducted using CICIDS2017 dataset and a custom dataset collected as part of this study. It is shown that the performance metrics decline significantly when changing datasets, and the reduction in performance metrics can be attributed to the difference in signatures of the same type flows in different datasets, which in turn can be attributed to the differences between the underlying networks. It is shown that the generalization accuracy of some neural networks can be very unstable and sensitive to random initialization parameters, and neural networks with fewer parameters and well-tuned activations are more stable and achieve higher accuracy.
Latent space configuration for improved generalization in supervised autoencoder neural networks
Feb 22, 2024



Autoencoders (AE) are simple yet powerful class of neural networks that compress data by projecting input into low-dimensional latent space (LS). Whereas LS is formed according to the loss function minimization during training, its properties and topology are not controlled directly. In this paper we focus on AE LS properties and propose two methods for obtaining LS with desired topology, called LS configuration. The proposed methods include loss configuration using a geometric loss term that acts directly in LS, and encoder configuration. We show that the former allows to reliably obtain LS with desired configuration by defining the positions and shapes of LS clusters for supervised AE (SAE). Knowing LS configuration allows to define similarity measure in LS to predict labels or estimate similarity for multiple inputs without using decoders or classifiers. We also show that this leads to more stable and interpretable training. We show that SAE trained for clothes texture classification using the proposed method generalizes well to unseen data from LIP, Market1501, and WildTrack datasets without fine-tuning, and even allows to evaluate similarity for unseen classes. We further illustrate the advantages of pre-configured LS similarity estimation with cross-dataset searches and text-based search using a text query without language models.
Investigation and rectification of NIDS datasets and standardized feature set derivation for network attack detection with graph neural networks
Dec 29, 2022


Network Intrusion and Detection Systems (NIDS) are essential for malicious traffic and cyberattack detection in modern networks. Artificial intelligence-based NIDS are powerful tools that can learn complex data correlations for accurate attack prediction. Graph Neural Networks (GNNs) provide an opportunity to analyze network topology along with flow features which makes them particularly suitable for NIDS applications. However, successful application of such tool requires large amounts of carefully collected and labeled data for training and testing. In this paper we inspect different versions of ToN-IoT dataset and point out inconsistencies in some versions. We filter the full version of ToN-IoT and present a new version labeled ToN-IoT-R. To ensure generalization we propose a new standardized and compact set of flow features which are derived solely from NetFlowv5-compatible data. We separate numeric data and flags into different categories and propose a new dataset-agnostic normalization approach for numeric features. This allows us to preserve meaning of flow flags and we propose to conduct targeted analysis based on, for instance, network protocols. For flow classification we use E-GraphSage algorithm with modified node initialization technique that allows us to add node degree to node features. We achieve high classification accuracy on ToN-IoT-R and compare it with previously published results for ToN-IoT, NF-ToN-IoT, and NF-ToN-IoT-v2. We highlight the importance of careful data collection and labeling and appropriate data preprocessing choice and conclude that the proposed set of features is more applicable for real NIDS due to being less demanding to traffic monitoring equipment while preserving high flow classification accuracy.
Google Coral-based edge computing person reidentification using human parsing combined with analytical method
Sep 22, 2022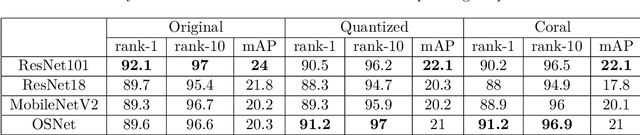

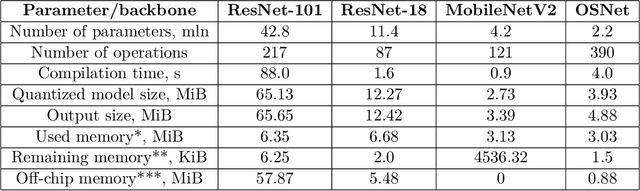
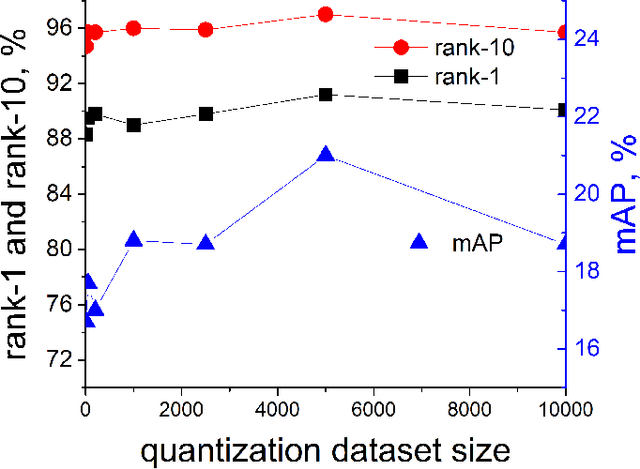
Person reidentification (re-ID) is becoming one of the most significant application areas of computer vision due to its importance for science and social security. Due to enormous size and scale of camera systems it is beneficial to develop edge computing re-ID applications where at least part of the analysis could be performed by the cameras. However, conventional re-ID relies heavily on deep learning (DL) computationally demanding models which are not readily applicable for edge computing. In this paper we adapt a recently proposed re-ID method that combines DL human parsing with analytical feature extraction and ranking schemes to be more suitable for edge computing re-ID. First, we compare parsers that use ResNet101, ResNet18, MobileNetV2, and OSNet backbones and show that parsing can be performed using compact backbones with sufficient accuracy. Second, we transfer parsers to tensor processing unit (TPU) of Google Coral Dev Board and show that it can act as a portable edge computing re-ID station. We also implement the analytical part of re-ID method on Coral CPU to ensure that it can perform a complete re-ID cycle. For quantitative analysis we compare inference speed, parsing masks, and re-ID accuracy on GPU and Coral TPU depending on parser backbone. We also discuss possible application scenarios of edge computing in re-ID taking into account known limitations mainly related to memory and storage space of portable devices.
Combining human parsing with analytical feature extraction and ranking schemes for high-generalization person reidentification
Jul 28, 2022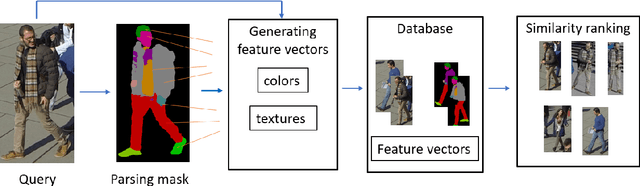


Person reidentification (re-ID) has been receiving increasing attention in recent years due to its importance for both science and society. Machine learning and particularly Deep Learning (DL) has become the main re-id tool that allowed researches to achieve unprecedented accuracy levels on benchmark datasets. However, there is a known problem of poor generalization of DL models. That is, models trained to achieve high accuracy on one dataset perform poorly on other ones and require re-training. To address this issue, we present a model without trainable parameters which shows great potential for high generalization. It combines a fully analytical feature extraction and similarity ranking scheme with DL-based human parsing used to obtain the initial subregion classification. We show that such combination to a high extent eliminates the drawbacks of existing analytical methods. We use interpretable color and texture features which have human-readable similarity measures associated with them. To verify the proposed method we conduct experiments on Market1501 and CUHK03 datasets achieving competitive rank-1 accuracy comparable with that of DL-models. Most importantly we show that our method achieves 63.9% and 93.5% rank-1 cross-domain accuracy when applied to transfer learning tasks. It is significantly higher than previously reported 30-50% transfer accuracy. We discuss the potential ways of adding new features to further improve the model. We also show the advantage of interpretable features for constructing human-generated queries from verbal description to conduct search without a query image.