 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Categorizing Offensive Language in Social Media
Apr 10, 2021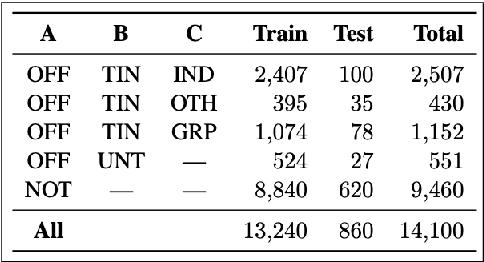

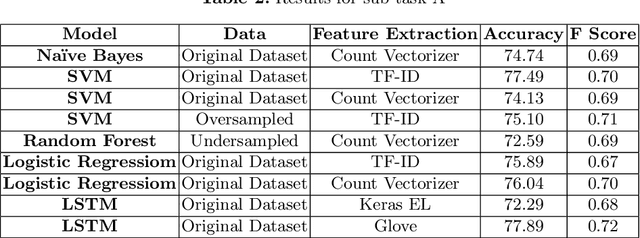
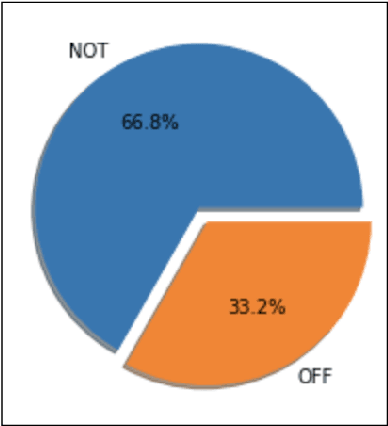
Offensive language is pervasive in social media. Individuals frequently take advantage of the perceived anonymity of computer-mediated communication, using this to engage in behavior that many of them would not consider in real life. The automatic identification of offensive content online is an important task that has gained more attention in recent years. This task can be modeled as a supervised classification problem in which systems are trained using a dataset containing posts that are annotated with respect to the presence of some form(s) of abusive or offensive content. The objective of this study is to provide a description of a classification system built for SemEval-2019 Task 6: OffensEval. This system classifies a tweet as either offensive or not offensive (Sub-task A) and further classifies offensive tweets into categories (Sub-tasks B \& C). We trained machine learning and deep learning models along with data preprocessing and sampling techniques to come up with the best results. Models discussed include Naive Bayes, SVM, Logistic Regression, Random Forest and LSTM.
Detect Toxic Content to Improve Online Conversations
Oct 29, 2019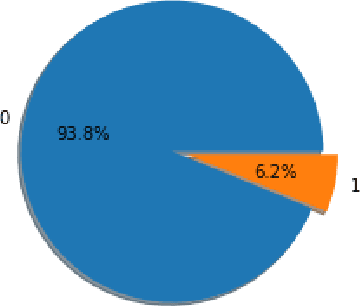
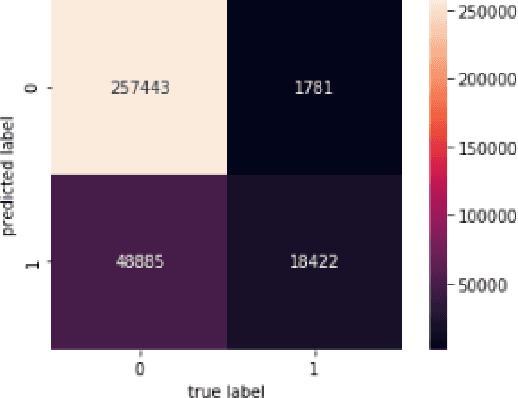
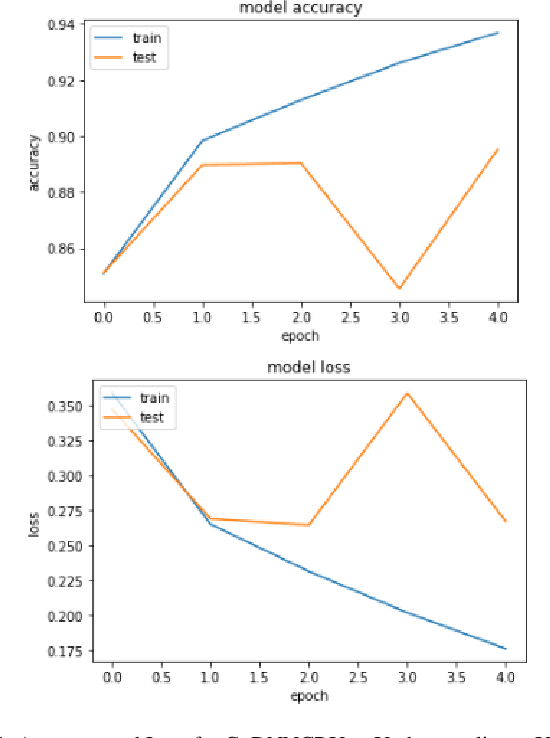
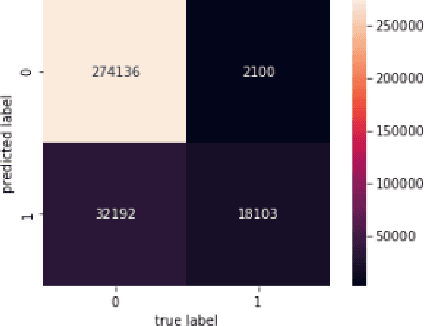
Social media is filled with toxic content. The aim of this paper is to build a model that can detect insincere questions. We use the 'Quora Insincere Questions Classification' dataset for our analysis. The dataset is composed of sincere and insincere questions, with the majority of sincere questions. The dataset is processed and analyzed using Python and its libraries such as sklearn, numpy, pandas, keras etc. The dataset is converted to vector form using word embeddings such as GloVe, Wiki-news and TF-IDF. The imbalance in the dataset is handled by resampling techniques. We train and compare various machine learning and deep learning models to come up with the best results. Models discussed include SVM, Naive Bayes, GRU and LSTM.
Predicting Rainfall using Machine Learning Techniques
Oct 29, 2019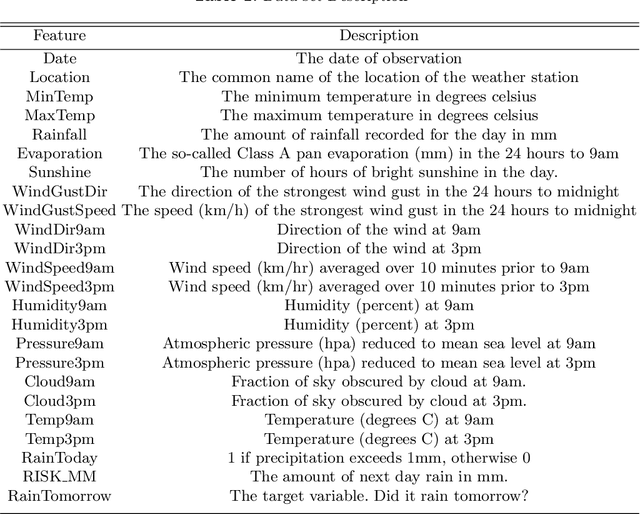
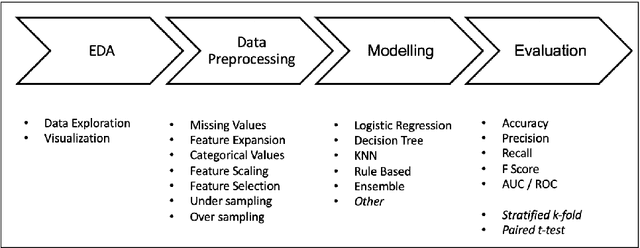

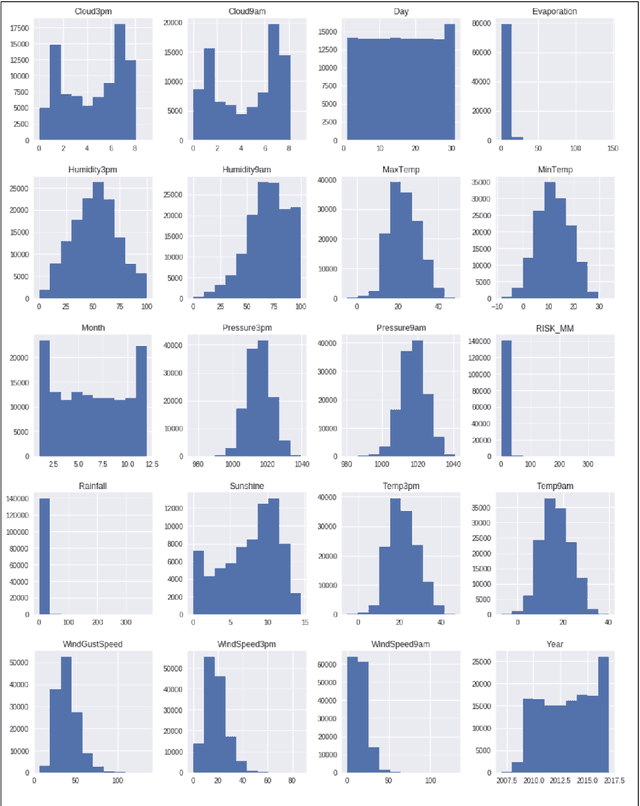
Rainfall prediction is one of the challenging and uncertain tasks which has a significant impact on human society. Timely and accurate predictions can help to proactively reduce human and financial loss. This study presents a set of experiments which involve the use of prevalent machine learning techniques to build models to predict whether it is going to rain tomorrow or not based on weather data for that particular day in major cities of Australia. This comparative study is conducted concentrating on three aspects: modeling inputs, modeling methods, and pre-processing techniques. The results provide a comparison of various evaluation metrics of these machine learning techniques and their reliability to predict the rainfall by analyzing the weather data.