 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-Assisted Bulk Resource Allocation: Custom Outage-Based Loss Function and Reliability Analysis
Feb 28, 2026Machine learning (ML)-assisted outage-based resource allocation has recently emerged as an effective alternative to conventional scheduling methods in reliability-critical wireless systems. However, existing approaches are fundamentally limited to single-resource allocation, whereas modern and emerging systems increasingly require the simultaneous allocation of multiple resources to meet aggregate rate and reliability constraints. In this paper, we extend outage-based learning to the bulk resource allocation regime, where a user requires at least $D$ reliable resources from a pool of $R$ candidates. We first introduce a practical allocation policy, termed gate + top-$D$ allocation (GTBA), which combines threshold-based admission control with ranking-based selection. We then propose a novel ranking-aware bulk outage loss (RBOL) that provides a differentiable surrogate for the bulk outage event induced by GTBA, explicitly accounting for both gate failures and ranking errors near the selection boundary. An exact reliability analysis is developed, establishing a decomposition of bulk outage probability (BOP), identifying dominant failure mechanisms and deriving an oracle lower bound that characterizes the fundamental performance limit. Extensive simulations under balanced, light and heavy stress regimes demonstrate that RBOL consistently outperforms conventional pointwise losses and baselines, achieving substantial reductions in BOP and remaining significantly closer to the oracle bound across a wide range of operating conditions. These results confirm that set-level, ranking-aware training objectives are essential for reliable ML-assisted bulk resource allocation.
To Trust or Not to Trust: On Calibration in ML-based Resource Allocation for Wireless Networks
Jul 23, 2025



In next-generation communications and networks, machine learning (ML) models are expected to deliver not only accurate predictions but also well-calibrated confidence scores that reflect the true likelihood of correct decisions. This paper studies the calibration performance of an ML-based outage predictor within a single-user, multi-resource allocation framework. We first establish key theoretical properties of this system's outage probability (OP) under perfect calibration. Importantly, we show that as the number of resources grows, the OP of a perfectly calibrated predictor approaches the expected output conditioned on it being below the classification threshold. In contrast, when only one resource is available, the system's OP equals the model's overall expected output. We then derive the OP conditions for a perfectly calibrated predictor. These findings guide the choice of the classification threshold to achieve a desired OP, helping system designers meet specific reliability requirements. We also demonstrate that post-processing calibration cannot improve the system's minimum achievable OP, as it does not introduce new information about future channel states. Additionally, we show that well-calibrated models are part of a broader class of predictors that necessarily improve OP. In particular, we establish a monotonicity condition that the accuracy-confidence function must satisfy for such improvement to occur. To demonstrate these theoretical properties, we conduct a rigorous simulation-based analysis using post-processing calibration techniques: Platt scaling and isotonic regression. As part of this framework, the predictor is trained using an outage loss function specifically designed for this system. Furthermore, this analysis is performed on Rayleigh fading channels with temporal correlation captured by Clarke's 2D model, which accounts for receiver mobility.
Outage Performance and Novel Loss Function for an ML-Assisted Resource Allocation: An Exact Analytical Framework
May 16, 2023Machine Learning (ML) is a popular tool that will be pivotal in enabling 6G and beyond communications. This paper focuses on applying ML solutions to address outage probability issues commonly encountered in these systems. In particular, we consider a single-user multi-resource greedy allocation strategy, where an ML binary classification predictor assists in seizing an adequate resource. With no access to future channel state information, this predictor foresees each resource's likely future outage status. When the predictor encounters a resource it believes will be satisfactory, it allocates it to the user. Critically, the goal of the predictor is to ensure that a user avoids an unsatisfactory resource since this is likely to cause an outage. Our main result establishes exact and asymptotic expressions for this system's outage probability. With this, we formulate a theoretically optimal, differentiable loss function to train our predictor. We then compare predictors trained using this and traditional loss functions; namely, binary cross-entropy (BCE), mean squared error (MSE), and mean absolute error (MAE). Predictors trained using our novel loss function provide superior outage probability in all scenarios. Our loss function sometimes outperforms predictors trained with the BCE, MAE, and MSE loss functions by multiple orders of magnitude.
AI-Based Channel Prediction in D2D Links: An Empirical Validation
Jun 16, 2022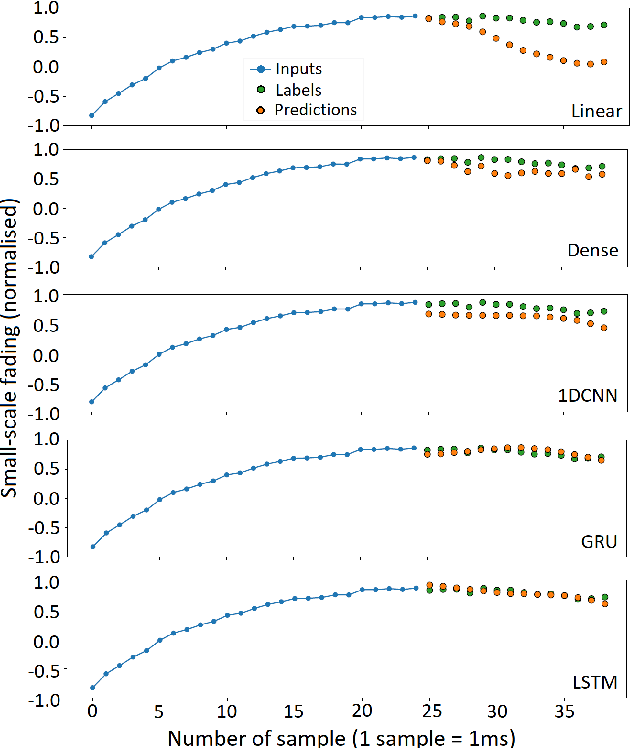
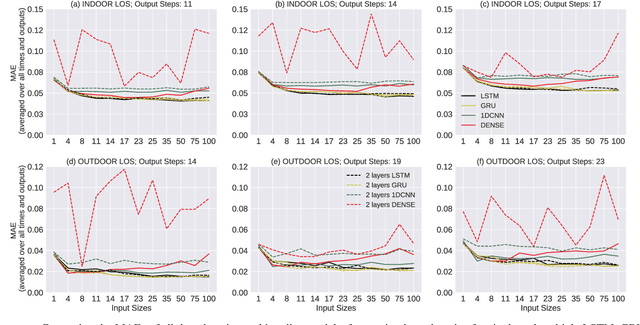
Device-to-Device (D2D) communication propelled by artificial intelligence (AI) will be an allied technology that will improve system performance and support new services in advanced wireless networks (5G, 6G and beyond). In this paper, AI-based deep learning techniques are applied to D2D links operating at 5.8 GHz with the aim at providing potential answers to the following questions concerning the prediction of the received signal strength variations: i) how effective is the prediction as a function of the coherence time of the channel? and ii) what is the minimum number of input samples required for a target prediction performance? To this end, a variety of measurement environments and scenarios are considered, including an indoor open-office area, an outdoor open-space, line of sight (LOS), non-LOS (NLOS), and mobile scenarios. Four deep learning models are explored, namely long short-term memory networks (LSTMs), gated recurrent units (GRUs), convolutional neural networks (CNNs), and dense or feedforward networks (FFNs). Linear regression is used as a baseline model. It is observed that GRUs and LSTMs present equivalent performance, and both are superior when compared to CNNs, FFNs and linear regression. This indicates that GRUs and LSTMs are able to better account for temporal dependencies in the D2D data sets. We also provide recommendations on the minimum input lengths that yield the required performance given the channel coherence time. For instance, to predict 17 and 23 ms into the future, in indoor and outdoor LOS environments, respectively, an input length of 25 ms is recommended. This indicates that the bulk of the learning is done within the coherence time of the channel, and that large input lengths may not always be beneficial.