 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction
May 22, 2026We introduce a new approach to high-fidelity 3D scene reconstruction from multi-view RGB images that tightly couples reconstruction with a strong generative 3D prior. We cast scene reconstruction as conditional 3D generation over a set of spatially-localized, overlapping chunks that together tile the scene, scaling generation to large scene extents. Crucially, we inherit the fidelity and completeness of state-of-the-art generative shape models -- we use Trellis.2 as an example -- which we generalize to the scene level. To this end, we propose a projection-based conditioning mechanism that lifts posed multi-view image features into a coherent 3D representation aligned with the generative model, independent of view ordering and spatially anchored to the scene, yielding high-fidelity, multi-view consistent generated geometry. This enables lifting the strong object-level prior of Trellis.2 to multi-view, scene-scale generation, producing faithful, editable PBR mesh reconstructions of indoor environments. As a result, we obtain high-fidelity results that outperform cutting-edge reconstruction methods by 16%.
GaussianGPT: Towards Autoregressive 3D Gaussian Scene Generation
Mar 27, 2026Most recent advances in 3D generative modeling rely on diffusion or flow-matching formulations. We instead explore a fully autoregressive alternative and introduce GaussianGPT, a transformer-based model that directly generates 3D Gaussians via next-token prediction, thus facilitating full 3D scene generation. We first compress Gaussian primitives into a discrete latent grid using a sparse 3D convolutional autoencoder with vector quantization. The resulting tokens are serialized and modeled using a causal transformer with 3D rotary positional embedding, enabling sequential generation of spatial structure and appearance. Unlike diffusion-based methods that refine scenes holistically, our formulation constructs scenes step-by-step, naturally supporting completion, outpainting, controllable sampling via temperature, and flexible generation horizons. This formulation leverages the compositional inductive biases and scalability of autoregressive modeling while operating on explicit representations compatible with modern neural rendering pipelines, positioning autoregressive transformers as a complementary paradigm for controllable and context-aware 3D generation.
LinPrim: Linear Primitives for Differentiable Volumetric Rendering
Jan 27, 2025

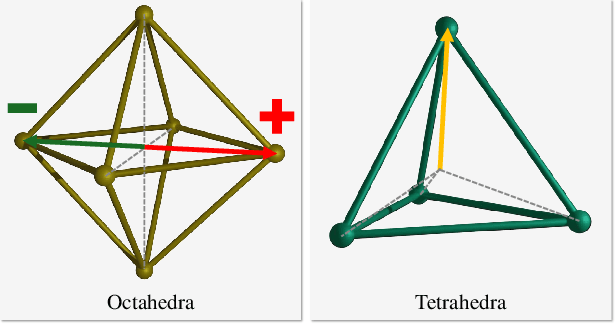
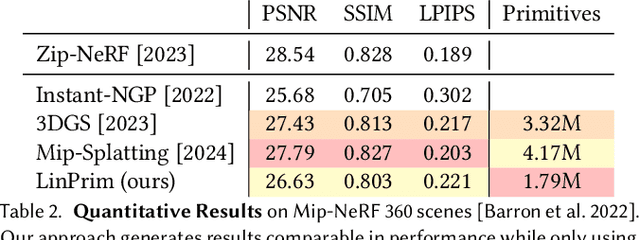
Volumetric rendering has become central to modern novel view synthesis methods, which use differentiable rendering to optimize 3D scene representations directly from observed views. While many recent works build on NeRF or 3D Gaussians, we explore an alternative volumetric scene representation. More specifically, we introduce two new scene representations based on linear primitives-octahedra and tetrahedra-both of which define homogeneous volumes bounded by triangular faces. This formulation aligns naturally with standard mesh-based tools, minimizing overhead for downstream applications. To optimize these primitives, we present a differentiable rasterizer that runs efficiently on GPUs, allowing end-to-end gradient-based optimization while maintaining realtime rendering capabilities. Through experiments on real-world datasets, we demonstrate comparable performance to state-of-the-art volumetric methods while requiring fewer primitives to achieve similar reconstruction fidelity. Our findings provide insights into the geometry of volumetric rendering and suggest that adopting explicit polyhedra can expand the design space of scene representations.