 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn a Possible Similarity between Gene and Semantic Networks
Apr 27, 2015


In several domains such as linguistics, molecular biology or social sciences, holistic effects are hardly well-defined by modeling with single units, but more and more studies tend to understand macro structures with the help of meaningful and useful associations in fields such as social networks, systems biology or semantic web. A stochastic multi-agent system offers both accurate theoretical framework and operational computing implementations to model large-scale associations, their dynamics and patterns extraction. We show that clustering around a target object in a set of associations of object prove some similarity in specific data and two case studies about gene-gene and term-term relationships leading to an idea of a common organizing principle of cognition with random and deterministic effects.
svcR: An R Package for Support Vector Clustering improved with Geometric Hashing applied to Lexical Pattern Discovery
Apr 23, 2015
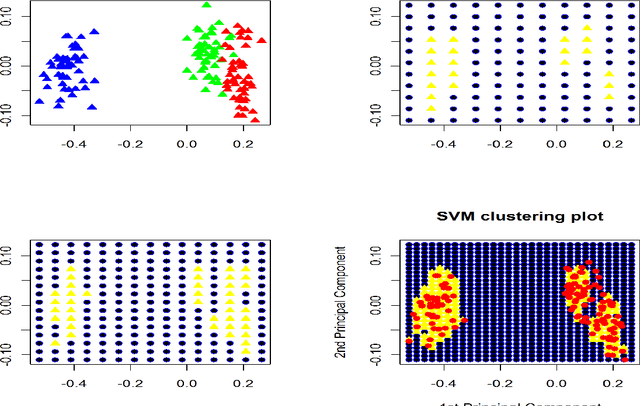

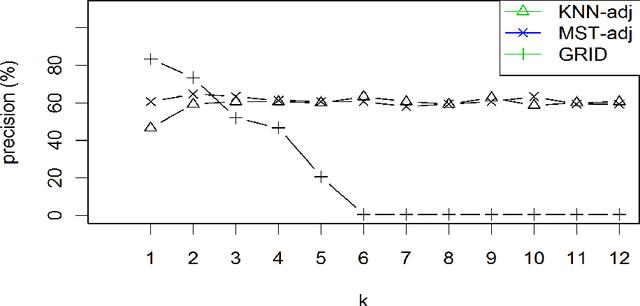
We present a new R package which takes a numerical matrix format as data input, and computes clusters using a support vector clustering method (SVC). We have implemented an original 2D-grid labeling approach to speed up cluster extraction. In this sense, SVC can be seen as an efficient cluster extraction if clusters are separable in a 2-D map. Secondly we showed that this SVC approach using a Jaccard-Radial base kernel can help to classify well enough a set of terms into ontological classes and help to define regular expression rules for information extraction in documents; our case study concerns a set of terms and documents about developmental and molecular biology.
x.ent: R Package for Entities and Relations Extraction based on Unsupervised Learning and Document Structure
Apr 23, 2015
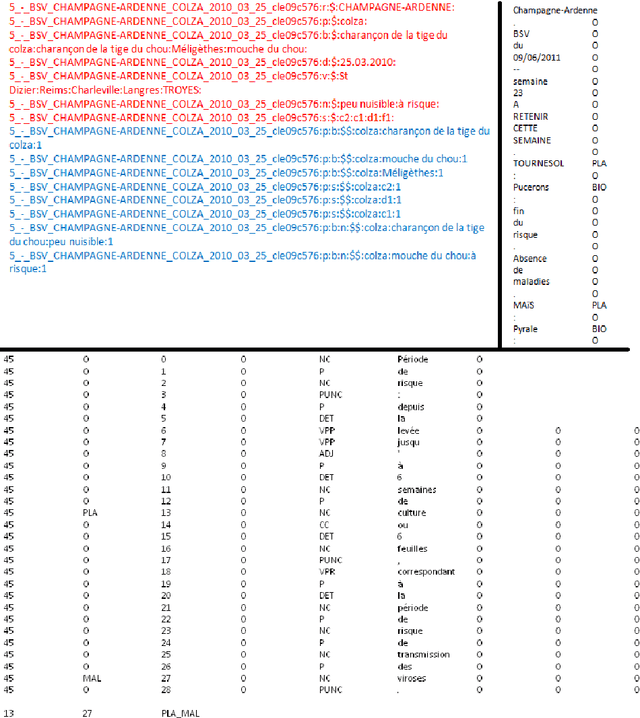

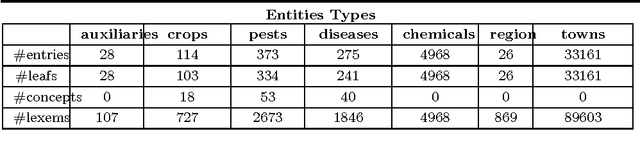
Relation extraction with accurate precision is still a challenge when processing full text databases. We propose an approach based on cooccurrence analysis in each document for which we used document organization to improve accuracy of relation extraction. This approach is implemented in a R package called \emph{x.ent}. Another facet of extraction relies on use of extracted relation into a querying system for expert end-users. Two datasets had been used. One of them gets interest from specialists of epidemiology in plant health. For this dataset usage is dedicated to plant-disease exploration through agricultural information news. An open-data platform exploits exports from \emph{x.ent} and is publicly available.
Open Data Platform for Knowledge Access in Plant Health Domain : VESPA Mining
Apr 23, 2015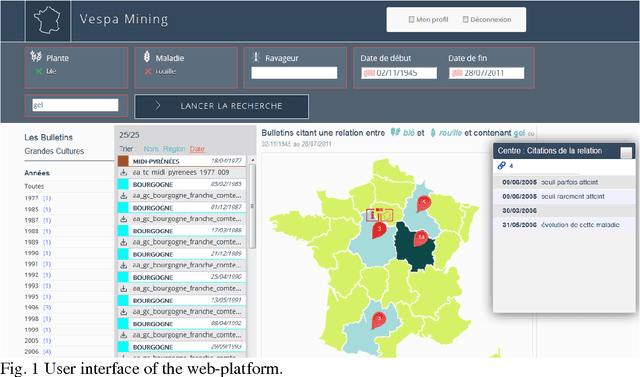
Important data are locked in ancient literature. It would be uneconomic to produce these data again and today or to extract them without the help of text mining technologies. Vespa is a text mining project whose aim is to extract data on pest and crops interactions, to model and predict attacks on crops, and to reduce the use of pesticides. A few attempts proposed an agricultural information access. Another originality of our work is to parse documents with a dependency of the document architecture.
Clustering and Relational Ambiguity: from Text Data to Natural Data
Apr 10, 2014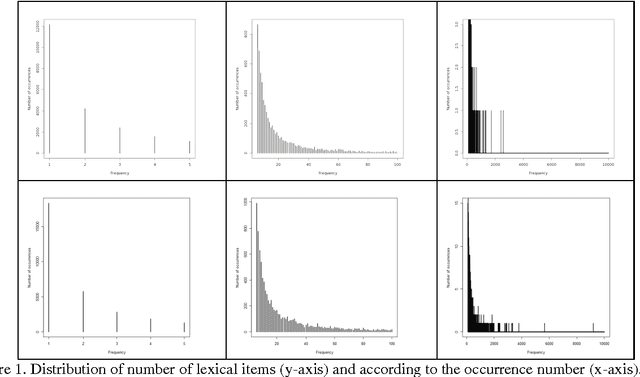



Text data is often seen as "take-away" materials with little noise and easy to process information. Main questions are how to get data and transform them into a good document format. But data can be sensitive to noise oftenly called ambiguities. Ambiguities are aware from a long time, mainly because polysemy is obvious in language and context is required to remove uncertainty. I claim in this paper that syntactic context is not suffisant to improve interpretation. In this paper I try to explain that firstly noise can come from natural data themselves, even involving high technology, secondly texts, seen as verified but meaningless, can spoil content of a corpus; it may lead to contradictions and background noise.