 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA relaxed proximal gradient descent algorithm for convergent plug-and-play with proximal denoiser
Jan 31, 2023


This paper presents a new convergent Plug-and-Play (PnP) algorithm. PnP methods are efficient iterative algorithms for solving image inverse problems formulated as the minimization of the sum of a data-fidelity term and a regularization term. PnP methods perform regularization by plugging a pre-trained denoiser in a proximal algorithm, such as Proximal Gradient Descent (PGD). To ensure convergence of PnP schemes, many works study specific parametrizations of deep denoisers. However, existing results require either unverifiable or suboptimal hypotheses on the denoiser, or assume restrictive conditions on the parameters of the inverse problem. Observing that these limitations can be due to the proximal algorithm in use, we study a relaxed version of the PGD algorithm for minimizing the sum of a convex function and a weakly convex one. When plugged with a relaxed proximal denoiser, we show that the proposed PnP-$\alpha$PGD algorithm converges for a wider range of regularization parameters, thus allowing more accurate image restoration.
SCOTCH and SODA: A Transformer Video Shadow Detection Framework
Nov 13, 2022



Shadows in videos are difficult to detect because of the large shadow deformation between frames. In this work, we argue that accounting for the shadow deformation is essential when designing a video shadow detection method. To this end, we introduce the shadow deformation attention trajectory (SODA), a new type of video self-attention module, specially designed to handle the large shadow deformations in videos. Moreover, we present a shadow contrastive learning mechanism (SCOTCH) which aims at guiding the network to learn a high-level representation of shadows, unified across different videos. We demonstrate empirically the effectiveness of our two contributions in an ablation study. Furthermore, we show that SCOTCH and SODA significantly outperforms existing techniques for video shadow detection. Code will be available upon the acceptance of this work.
A patch-based architecture for multi-label classification from single label annotations
Sep 14, 2022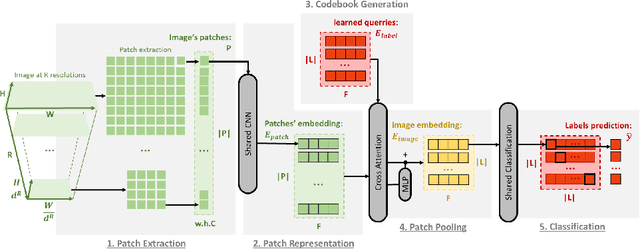
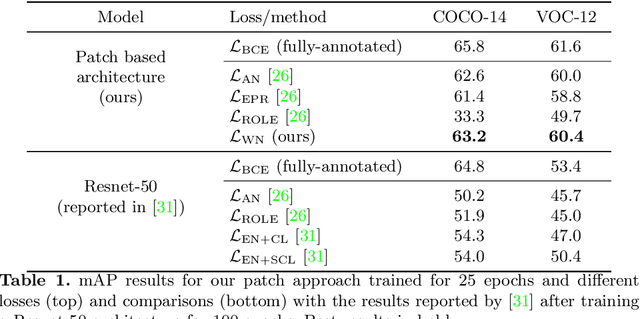
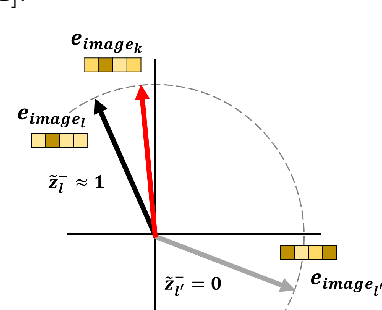

In this paper, we propose a patch-based architecture for multi-label classification problems where only a single positive label is observed in images of the dataset. Our contributions are twofold. First, we introduce a light patch architecture based on the attention mechanism. Next, leveraging on patch embedding self-similarities, we provide a novel strategy for estimating negative examples and deal with positive and unlabeled learning problems. Experiments demonstrate that our architecture can be trained from scratch, whereas pre-training on similar databases is required for related methods from the literature.
Diverse super-resolution with pretrained deep hiererarchical VAEs
May 20, 2022


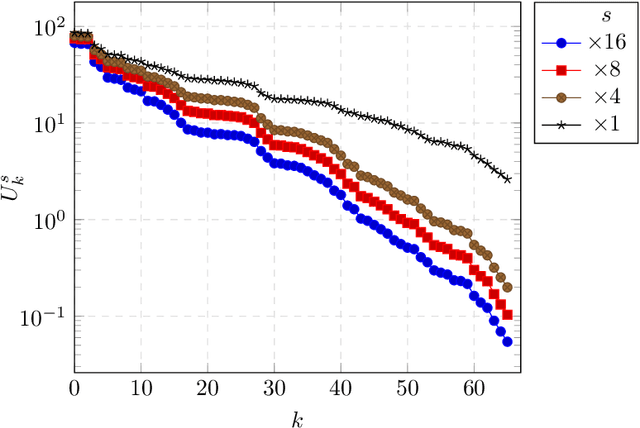
Image super-resolution is a one-to-many problem, but most deep-learning based methods only provide one single solution to this problem. In this work, we tackle the problem of diverse super-resolution by reusing VD-VAE, a state-of-the art variational autoencoder (VAE). We find that the hierarchical latent representation learned by VD-VAE naturally separates the image low-frequency information, encoded in the latent groups at the top of the hierarchy, from the image high-frequency details, determined by the latent groups at the bottom of the latent hierarchy. Starting from this observation, we design a super-resolution model exploiting the specific structure of VD-VAE latent space. Specifically, we train an encoder to encode low-resolution images in the subset of VD-VAE latent space encoding the low-frequency information, and we combine this encoder with VD-VAE generative model to sample diverse super-resolved version of a low-resolution input. We demonstrate the ability of our method to generate diverse solutions to the super-resolution problem on face super-resolution with upsampling factors x4, x8, and x16.
Multi-Modal Hypergraph Diffusion Network with Dual Prior for Alzheimer Classification
Apr 04, 2022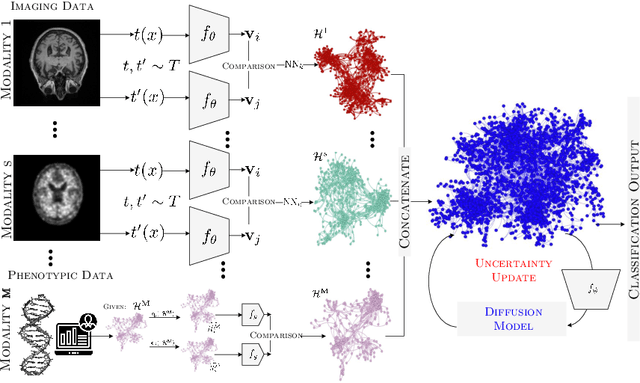
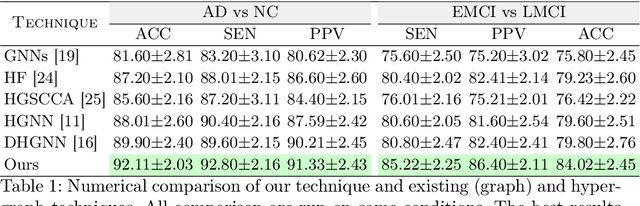
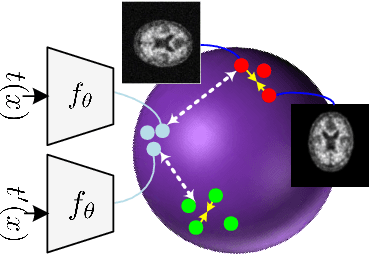
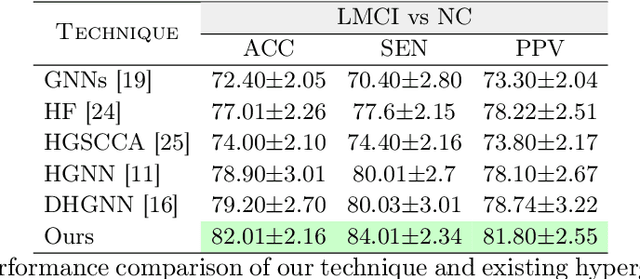
The automatic early diagnosis of prodromal stages of Alzheimer's disease is of great relevance for patient treatment to improve quality of life. We address this problem as a multi-modal classification task. Multi-modal data provides richer and complementary information. However, existing techniques only consider either lower order relations between the data and single/multi-modal imaging data. In this work, we introduce a novel semi-supervised hypergraph learning framework for Alzheimer's disease diagnosis. Our framework allows for higher-order relations among multi-modal imaging and non-imaging data whilst requiring a tiny labelled set. Firstly, we introduce a dual embedding strategy for constructing a robust hypergraph that preserves the data semantics. We achieve this by enforcing perturbation invariance at the image and graph levels using a contrastive based mechanism. Secondly, we present a dynamically adjusted hypergraph diffusion model, via a semi-explicit flow, to improve the predictive uncertainty. We demonstrate, through our experiments, that our framework is able to outperform current techniques for Alzheimer's disease diagnosis.
Proximal denoiser for convergent plug-and-play optimization with nonconvex regularization
Jan 31, 2022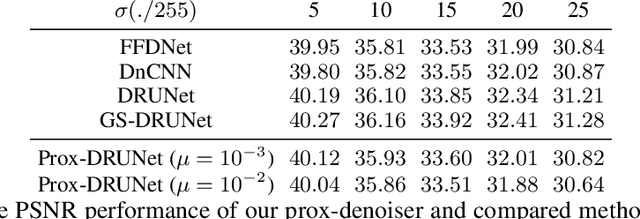
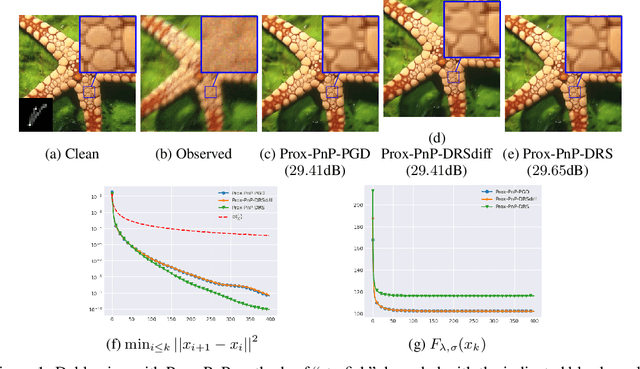
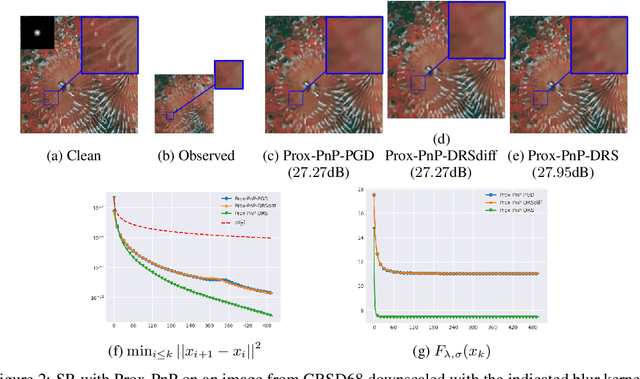
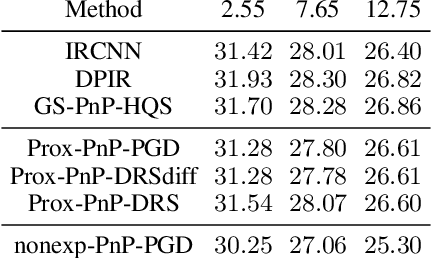
Plug-and-Play (PnP) methods solve ill-posed inverse problems through iterative proximal algorithms by replacing a proximal operator by a denoising operation. When applied with deep neural network denoisers, these methods have shown state-of-the-art visual performance for image restoration problems. However, their theoretical convergence analysis is still incomplete. Most of the existing convergence results consider nonexpansive denoisers, which is non-realistic, or limit their analysis to strongly convex data-fidelity terms in the inverse problem to solve. Recently, it was proposed to train the denoiser as a gradient descent step on a functional parameterized by a deep neural network. Using such a denoiser guarantees the convergence of the PnP version of the Half-Quadratic-Splitting (PnP-HQS) iterative algorithm. In this paper, we show that this gradient denoiser can actually correspond to the proximal operator of another scalar function. Given this new result, we exploit the convergence theory of proximal algorithms in the nonconvex setting to obtain convergence results for PnP-PGD (Proximal Gradient Descent) and PnP-ADMM (Alternating Direction Method of Multipliers). When built on top of a smooth gradient denoiser, we show that PnP-PGD and PnP-ADMM are convergent and target stationary points of an explicit functional. These convergence results are confirmed with numerical experiments on deblurring, super-resolution and inpainting.
Gradient Step Denoiser for convergent Plug-and-Play
Oct 07, 2021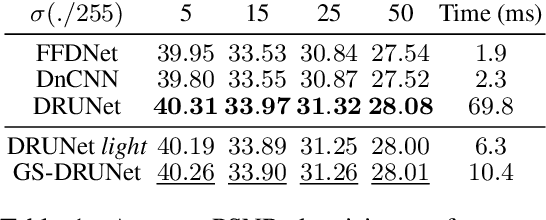
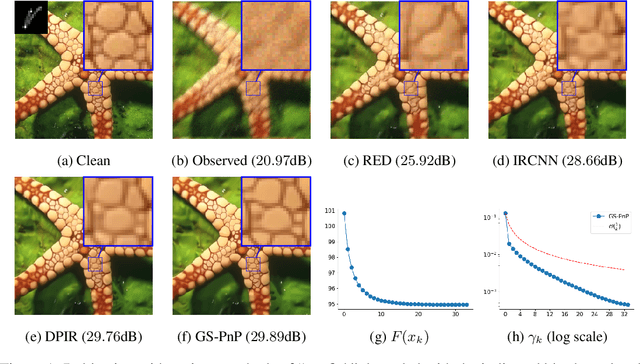
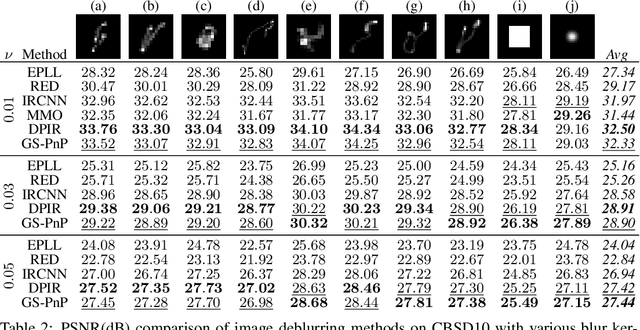
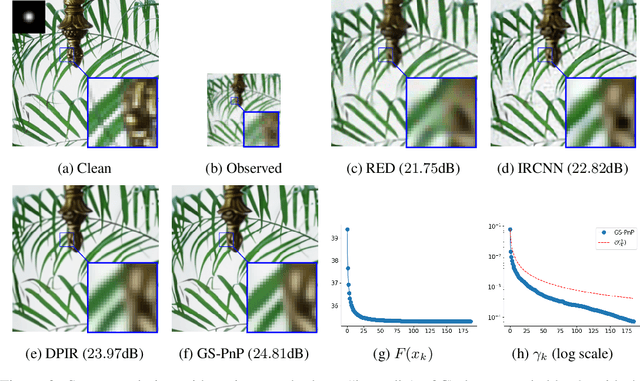
Plug-and-Play methods constitute a class of iterative algorithms for imaging problems where regularization is performed by an off-the-shelf denoiser. Although Plug-and-Play methods can lead to tremendous visual performance for various image problems, the few existing convergence guarantees are based on unrealistic (or suboptimal) hypotheses on the denoiser, or limited to strongly convex data terms. In this work, we propose a new type of Plug-and-Play methods, based on half-quadratic splitting, for which the denoiser is realized as a gradient descent step on a functional parameterized by a deep neural network. Exploiting convergence results for proximal gradient descent algorithms in the non-convex setting, we show that the proposed Plug-and-Play algorithm is a convergent iterative scheme that targets stationary points of an explicit global functional. Besides, experiments show that it is possible to learn such a deep denoiser while not compromising the performance in comparison to other state-of-the-art deep denoisers used in Plug-and-Play schemes. We apply our proximal gradient algorithm to various ill-posed inverse problems, e.g. deblurring, super-resolution and inpainting. For all these applications, numerical results empirically confirm the convergence results. Experiments also show that this new algorithm reaches state-of-the-art performance, both quantitatively and qualitatively.
POPCORN: Progressive Pseudo-labeling with Consistency Regularization and Neighboring
Sep 13, 2021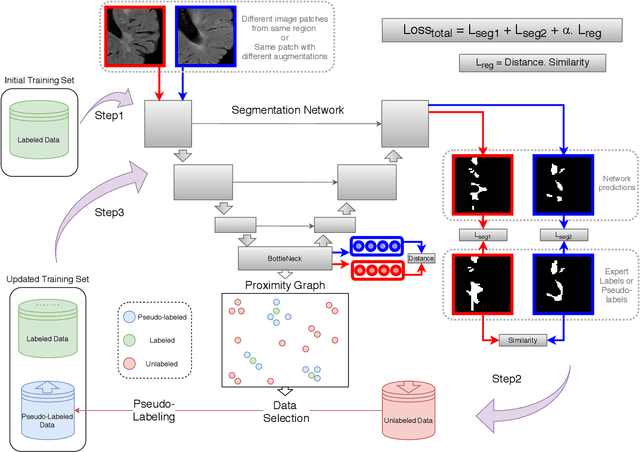

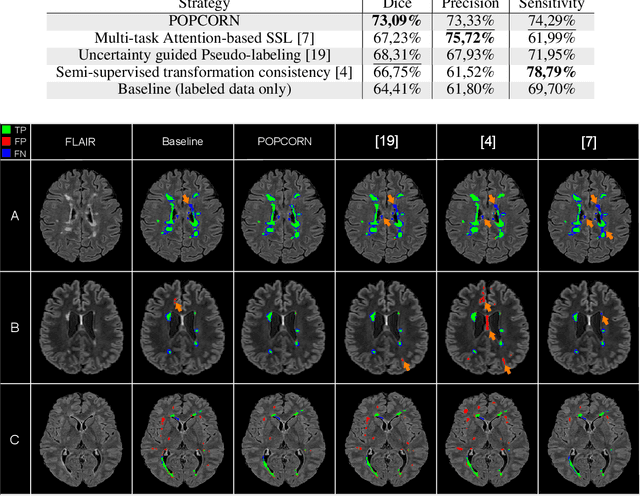
Semi-supervised learning (SSL) uses unlabeled data to compensate for the scarcity of annotated images and the lack of method generalization to unseen domains, two usual problems in medical segmentation tasks. In this work, we propose POPCORN, a novel method combining consistency regularization and pseudo-labeling designed for image segmentation. The proposed framework uses high-level regularization to constrain our segmentation model to use similar latent features for images with similar segmentations. POPCORN estimates a proximity graph to select data from easiest ones to more difficult ones, in order to ensure accurate pseudo-labeling and to limit confirmation bias. Applied to multiple sclerosis lesion segmentation, our method demonstrates competitive results compared to other state-of-the-art SSL strategies.
Learning local regularization for variational image restoration
Feb 11, 2021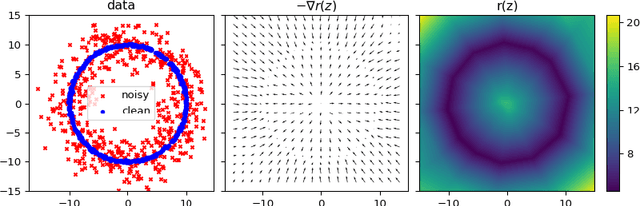

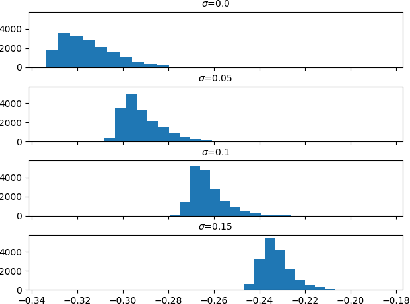

In this work, we propose a framework to learn a local regularization model for solving general image restoration problems. This regularizer is defined with a fully convolutional neural network that sees the image through a receptive field corresponding to small image patches. The regularizer is then learned as a critic between unpaired distributions of clean and degraded patches using a Wasserstein generative adversarial networks based energy. This yields a regularization function that can be incorporated in any image restoration problem. The efficiency of the framework is finally shown on denoising and deblurring applications.
On the Existence of Optimal Transport Gradient for Learning Generative Models
Feb 10, 2021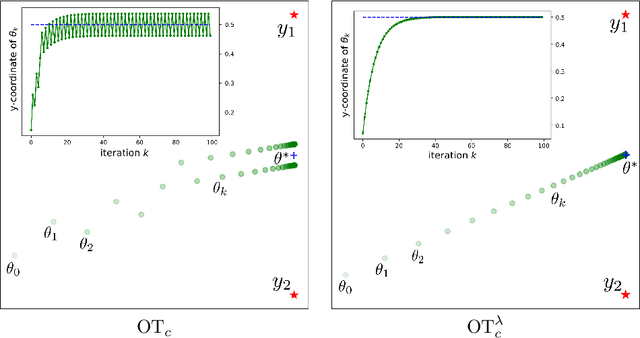

The use of optimal transport cost for learning generative models has become popular with Wasserstein Generative Adversarial Networks (WGAN). Training of WGAN relies on a theoretical background: the calculation of the gradient of the optimal transport cost with respect to the generative model parameters. We first demonstrate that such gradient may not be defined, which can result in numerical instabilities during gradient-based optimization. We address this issue by stating a valid differentiation theorem in the case of entropic regularized transport and specify conditions under which existence is ensured. By exploiting the discrete nature of empirical data, we formulate the gradient in a semi-discrete setting and propose an algorithm for the optimization of the generative model parameters. Finally, we illustrate numerically the advantage of the proposed framework.