 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptUI: LLM Agents as Human-Aligned Synthetic Users for UI/UX Evaluation
Jun 04, 2026User interface (UI) and user experience (UX) evaluation is central to product development, yet reliable feedback still relies on recruiting human participants or running online A/B tests, making early-stage iteration slow and costly. In light of this, recent work has explored Multimodal Large Language Models as proxy evaluators. However, existing approaches either produce surface-level critiques or a judgment that reflects the model's own biases rather than the genuine response of a particular user. We introduce PerceptUI, a framework for persona-conditioned UI/UX evaluation that predicts how a specific user would answer interface-related questions and produces natural-language rationales. PerceptUI is trained in two stages: (i) contrastive reflection fine-tuning distills teacher-generated rationales by extracting lessons from human decisions, and (ii) a reflective prompt-evolution step from the model's own failure traces. Across multiple domains and datasets, PerceptUI achieves human-level realism, generalizes to unseen questions and personas, and yields population-level response distributions.
AlignUSER: Human-Aligned LLM Agents via World Models for Recommender System Evaluation
Jan 02, 2026Evaluating recommender systems remains challenging due to the gap between offline metrics and real user behavior, as well as the scarcity of interaction data. Recent work explores large language model (LLM) agents as synthetic users, yet they typically rely on few-shot prompting, which yields a shallow understanding of the environment and limits their ability to faithfully reproduce user actions. We introduce AlignUSER, a framework that learns world-model-driven agents from human interactions. Given rollout sequences of actions and states, we formalize world modeling as a next state prediction task that helps the agent internalize the environment. To align actions with human personas, we generate counterfactual trajectories around demonstrations and prompt the LLM to compare its decisions with human choices, identify suboptimal actions, and extract lessons. The learned policy is then used to drive agent interactions with the recommender system. We evaluate AlignUSER across multiple datasets and demonstrate closer alignment with genuine humans than prior work, both at the micro and macro levels.
MobileCity: An Efficient Framework for Large-Scale Urban Behavior Simulation
Apr 18, 2025Generative agents offer promising capabilities for simulating realistic urban behaviors. However, existing methods oversimplify transportation choices in modern cities, and require prohibitive computational resources for large-scale population simulation. To address these limitations, we first present a virtual city that features multiple functional buildings and transportation modes. Then, we conduct extensive surveys to model behavioral choices and mobility preferences among population groups. Building on these insights, we introduce a simulation framework that captures the complexity of urban mobility while remaining scalable, enabling the simulation of over 4,000 agents. To assess the realism of the generated behaviors, we perform a series of micro and macro-level analyses. Beyond mere performance comparison, we explore insightful experiments, such as predicting crowd density from movement patterns and identifying trends in vehicle preferences across agent demographics.
SimUSER: Simulating User Behavior with Large Language Models for Recommender System Evaluation
Apr 17, 2025



Recommender systems play a central role in numerous real-life applications, yet evaluating their performance remains a significant challenge due to the gap between offline metrics and online behaviors. Given the scarcity and limits (e.g., privacy issues) of real user data, we introduce SimUSER, an agent framework that serves as believable and cost-effective human proxies. SimUSER first identifies self-consistent personas from historical data, enriching user profiles with unique backgrounds and personalities. Then, central to this evaluation are users equipped with persona, memory, perception, and brain modules, engaging in interactions with the recommender system. SimUSER exhibits closer alignment with genuine humans than prior work, both at micro and macro levels. Additionally, we conduct insightful experiments to explore the effects of thumbnails on click rates, the exposure effect, and the impact of reviews on user engagement. Finally, we refine recommender system parameters based on offline A/B test results, resulting in improved user engagement in the real world.
Deep Reinforcement Learning Boosted by External Knowledge
Dec 12, 2017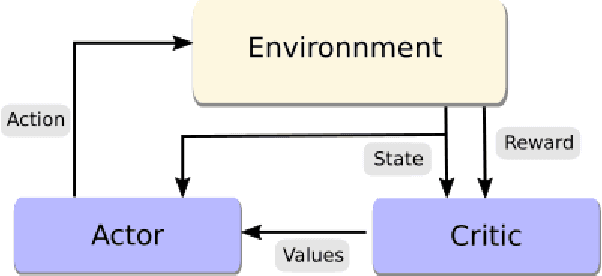

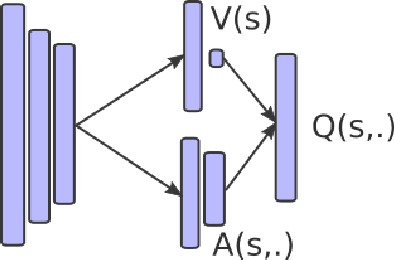

Recent improvements in deep reinforcement learning have allowed to solve problems in many 2D domains such as Atari games. However, in complex 3D environments, numerous learning episodes are required which may be too time consuming or even impossible especially in real-world scenarios. We present a new architecture to combine external knowledge and deep reinforcement learning using only visual input. A key concept of our system is augmenting image input by adding environment feature information and combining two sources of decision. We evaluate the performances of our method in a 3D partially-observable environment from the Microsoft Malmo platform. Experimental evaluation exhibits higher performance and faster learning compared to a single reinforcement learning model.