 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Encodings for Gradient Boosting with Automunge
Sep 25, 2022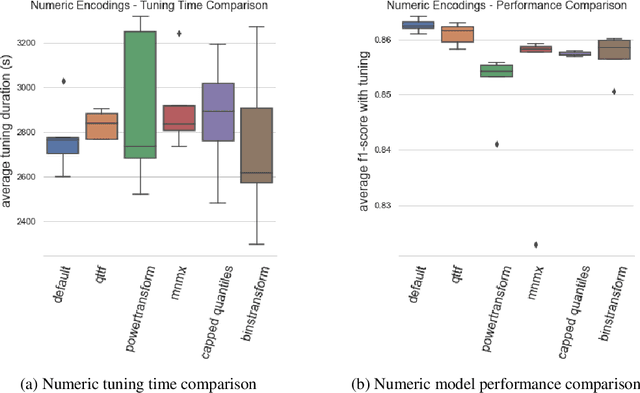
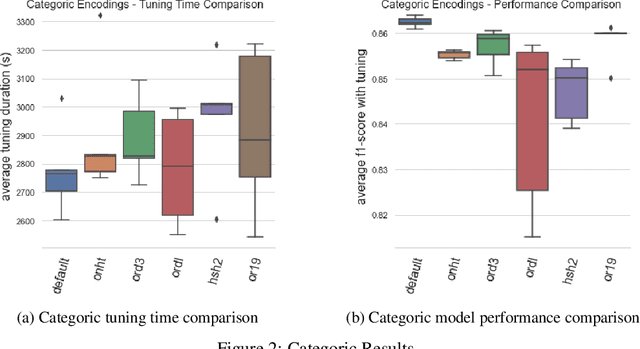
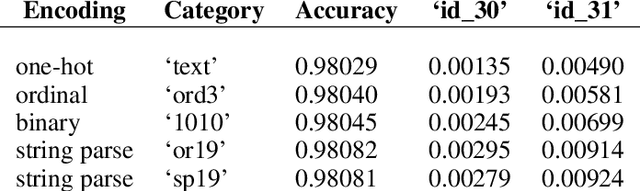
Selecting a default feature encoding strategy for gradient boosted learning may consider metrics of training duration and achieved predictive performance associated with the feature representations. The Automunge library for dataframe preprocessing offers a default of binarization for categoric features and z-score normalization for numeric. The presented study sought to validate those defaults by way of benchmarking on a series of diverse data sets by encoding variations with tuned gradient boosted learning. We found that on average our chosen defaults were top performers both from a tuning duration and a model performance standpoint. Another key finding was that one hot encoding did not perform in a manner consistent with suitability to serve as a categoric default in comparison to categoric binarization. We present here these and further benchmarks.
Numeric Encoding Options with Automunge
Feb 22, 2022

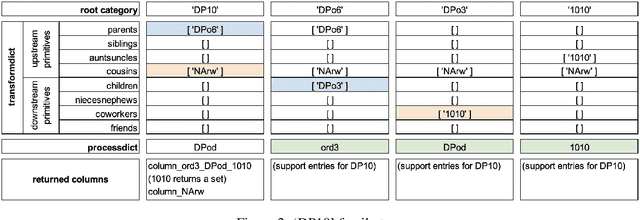
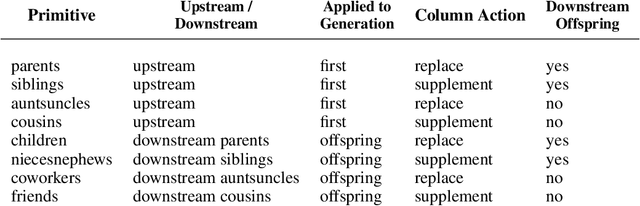
Mainstream practice in machine learning with tabular data may take for granted that any feature engineering beyond scaling for numeric sets is superfluous in context of deep neural networks. This paper will offer arguments for potential benefits of extended encodings of numeric streams in deep learning by way of a survey of options for numeric transformations as available in the Automunge open source python library platform for tabular data pipelines, where transformations may be applied to distinct columns in "family tree" sets with generations and branches of derivations. Automunge transformation options include normalization, binning, noise injection, derivatives, and more. The aggregation of these methods into family tree sets of transformations are demonstrated for use to present numeric features to machine learning in multiple configurations of varying information content, as may be applied to encode numeric sets of unknown interpretation. Experiments demonstrate the realization of a novel generalized solution to data augmentation by noise injection for tabular learning, as may materially benefit model performance in applications with underserved training data.
Parsed Categoric Encodings with Automunge
Feb 22, 2022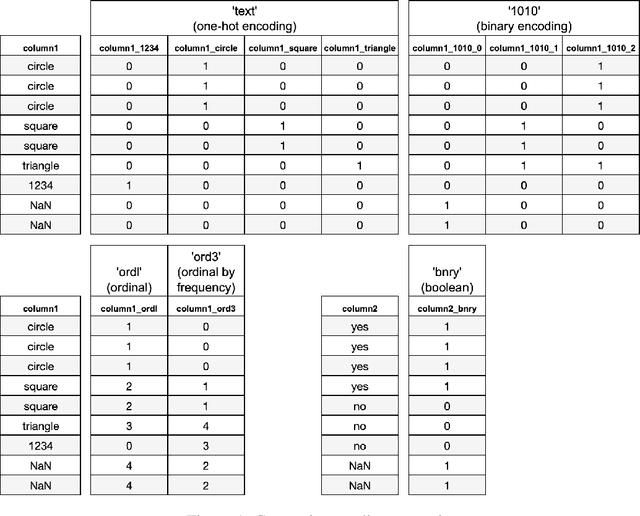
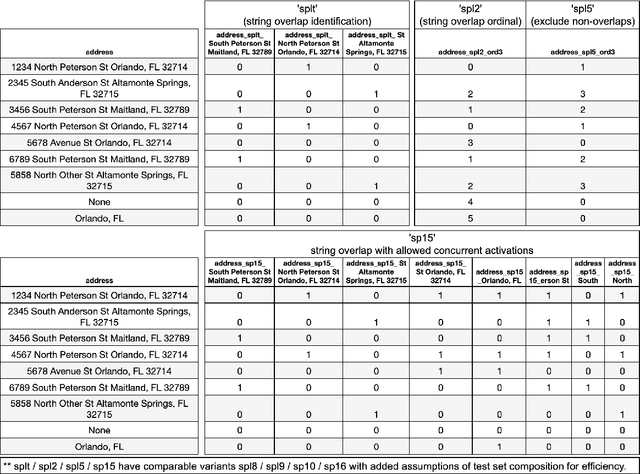
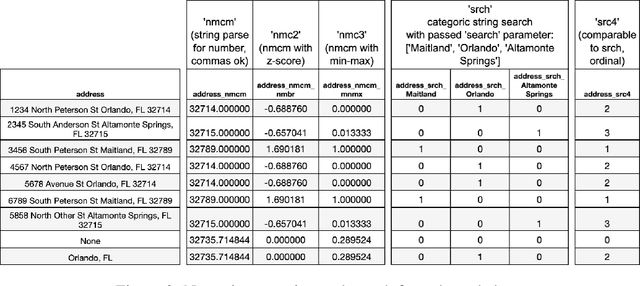
The Automunge open source python library platform for tabular data pre-processing automates feature engineering data transformations of numerical encoding and missing data infill to received tidy data on bases fit to properties of columns in a designated train set for consistent and efficient application to subsequent data pipelines such as for inference, where transformations may be applied to distinct columns in "family tree" sets with generations and branches of derivations. Included in the library of transformations are methods to extract structure from bounded categorical string sets by way of automated string parsing, in which comparisons between entries in the set of unique values are parsed to identify character subset overlaps which may be encoded by appended columns of boolean overlap detection activations or by replacing string entries with identified overlap partitions. Further string parsing options, which may also be applied to unbounded categoric sets, include extraction of numeric substring partitions from entries or search functions to identify presence of specified substring partitions. The aggregation of these methods into "family tree" sets of transformations are demonstrated for use to automatically extract structure from categoric string compositions in relation to the set of entries in a column, such as may be applied to prepare categoric string set encodings for machine learning without human intervention.
Missing Data Infill with Automunge
Feb 19, 2022
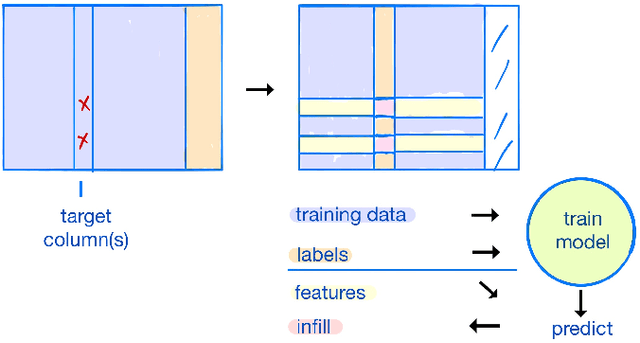
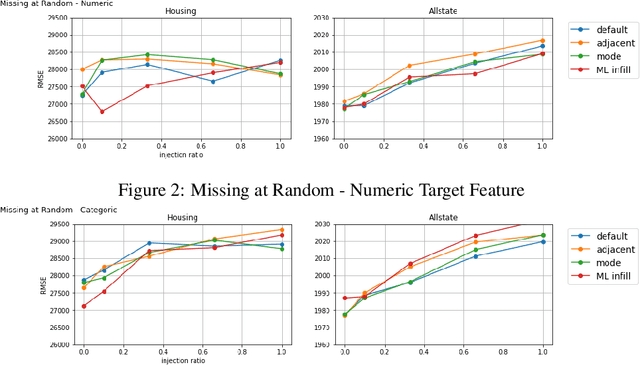
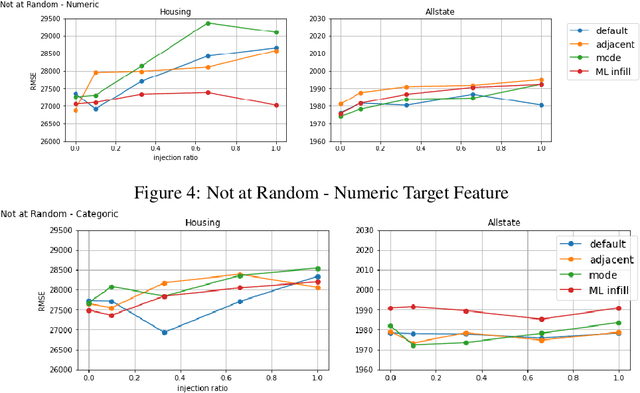
Missing data is a fundamental obstacle in the practice of data science. This paper surveys a few conventions for imputation as available in the Automunge open source python library platform for tabular data preprocessing, including "ML infill" in which auto ML models are trained for target features from partitioned extracts of a training set. A series of validation experiments were performed to benchmark imputation scenarios towards downstream model performance, in which it was found for the given benchmark sets that in many cases ML infill outperformed for both numeric and categoric target features, and was otherwise at minimum within noise distributions of the other imputation scenarios. Evidence also suggested supplementing ML infill with the addition of support columns with boolean integer markers signaling presence of infill was usually beneficial to downstream model performance. We consider these results sufficient to recommend defaulting to ML infill for tabular learning, and further recommend supplementing imputations with support columns signaling presence of infill, each as can be prepared with push-button operation in the Automunge library. Our contributions include an auto ML derived missing data imputation library for tabular learning in the python ecosystem, fully integrated into a preprocessing platform with an extensive library of feature transformations, with a novel production friendly implementation that bases imputation models on a designated train set for consistent basis towards additional data.
Geometric Regularization from Overparameterization explains Double Descent and other findings
Feb 18, 2022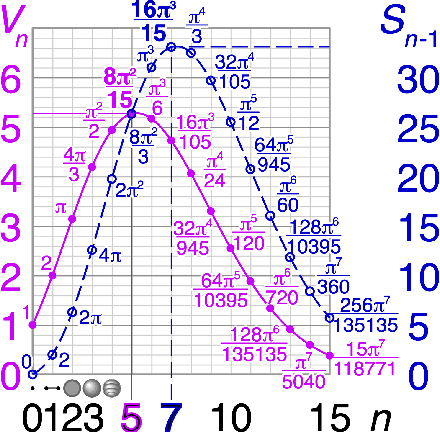
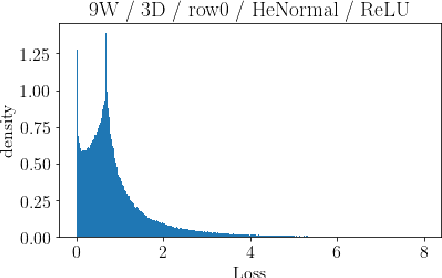
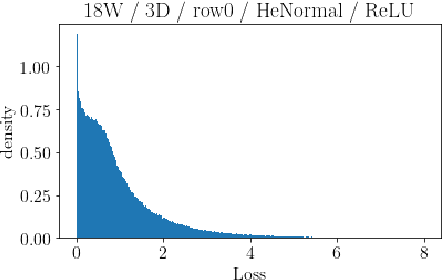
The volume of the distribution of possible weight configurations associated with a loss value may be the source of implicit regularization from overparameterization due to the phenomenon of contracting volume with increasing dimensions for geometric figures demonstrated by hyperspheres. This paper introduces geometric regularization and explores potential applicability to several unexplained phenomenon including double descent, the differences between wide and deep networks, the benefits of He initialization and retained proximity in training, gradient confusion, fitness landscape properties, double descent in other learning paradigms, and other findings for overparameterized learning. Experiments are conducted by aggregating histograms of loss values corresponding to randomly sampled initializations in small setups, which find directional correlations in zero or central mode dominance from deviations in width, depth, and initialization distributions. Double descent is likely due to a regularization phase change when a training path reaches low enough loss that the loss manifold volume contraction from a reduced range of potential weight sets is amplified by an overparameterized geometry.
Stochastic Perturbations of Tabular Features for Non-Deterministic Inference with Automunge
Feb 18, 2022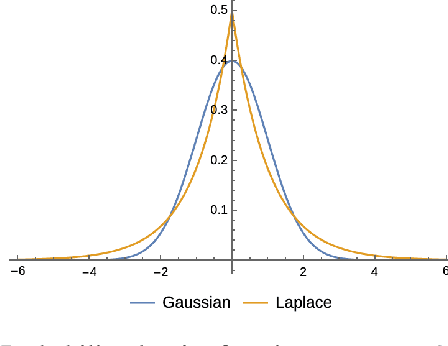
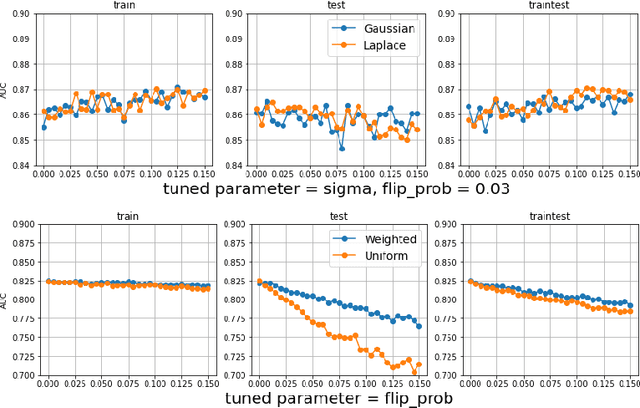
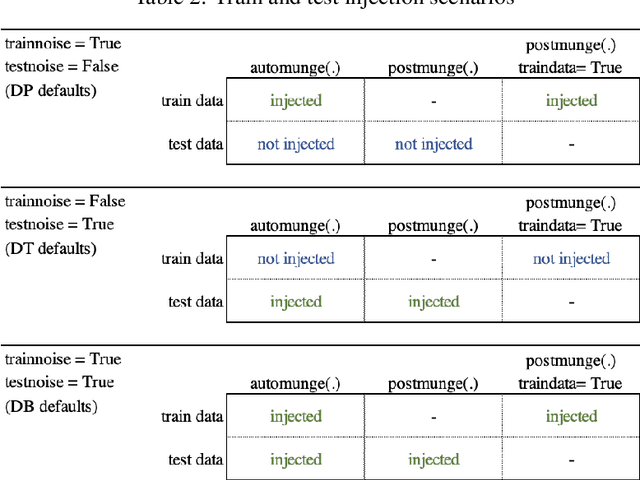
Injecting gaussian noise into training features is well known to have regularization properties. This paper considers noise injections to numeric or categoric tabular features as passed to inference, which translates inference to a non-deterministic outcome and may have relevance to fairness considerations, adversarial example protection, or other use cases benefiting from non-determinism. We offer the Automunge library for tabular preprocessing as a resource for the practice, which includes options to integrate random sampling or entropy seeding with the support of quantum circuits for an improved randomness profile in comparison to pseudo random number generators. Benchmarking shows that neural networks may demonstrate an improved performance when a known noise profile is mitigated with corresponding injections to both training and inference, and that gradient boosting appears to be robust to a mild noise profile in inference, suggesting that stochastic perturbations could be integrated into existing data pipelines for prior trained gradient boosting models.