 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAGE: Geometry Preserving Attributed Graph Embeddings
Nov 03, 2020


Node representation learning is the task of extracting concise and informative feature embeddings of certain entities that are connected in a network. Many real world network datasets include information about both node connectivity and certain node attributes, in the form of features or time-series data. Modern representation learning techniques utilize both connectivity and attribute information of the nodes to produce embeddings in an unsupervised manner. In this context, deriving embeddings that preserve the geometry of the network and the attribute vectors would be highly desirable, as they would reflect both the topological neighborhood structure and proximity in feature space. While this is fairly straightforward to maintain when only observing the connectivity or attributed information of the network, preserving the geometry of both types of information is challenging. A novel tensor factorization approach for node embedding in attributed networks that preserves the distances of both the connections and the attributes is proposed in this paper, along with an effective and lightweight algorithm to tackle the learning task. Judicious experiments with multiple state-of-art baselines suggest that the proposed algorithm offers significant performance improvements in node classification and link prediction tasks.
Information-theoretic Feature Selection via Tensor Decomposition and Submodularity
Oct 30, 2020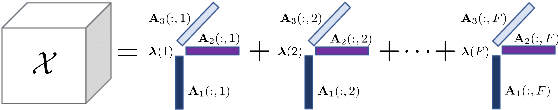
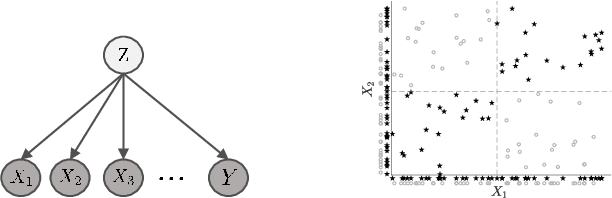
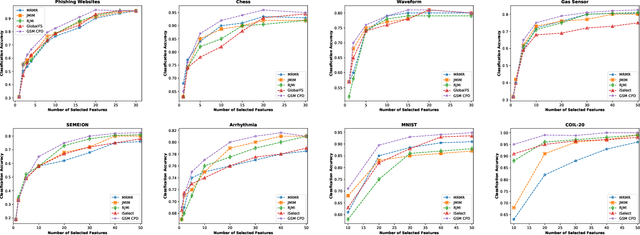
Feature selection by maximizing high-order mutual information between the selected feature vector and a target variable is the gold standard in terms of selecting the best subset of relevant features that maximizes the performance of prediction models. However, such an approach typically requires knowledge of the multivariate probability distribution of all features and the target, and involves a challenging combinatorial optimization problem. Recent work has shown that any joint Probability Mass Function (PMF) can be represented as a naive Bayes model, via Canonical Polyadic (tensor rank) Decomposition. In this paper, we introduce a low-rank tensor model of the joint PMF of all variables and indirect targeting as a way of mitigating complexity and maximizing the classification performance for a given number of features. Through low-rank modeling of the joint PMF, it is possible to circumvent the curse of dimensionality by learning principal components of the joint distribution. By indirectly aiming to predict the latent variable of the naive Bayes model instead of the original target variable, it is possible to formulate the feature selection problem as maximization of a monotone submodular function subject to a cardinality constraint - which can be tackled using a greedy algorithm that comes with performance guarantees. Numerical experiments with several standard datasets suggest that the proposed approach compares favorably to the state-of-art for this important problem.
TeX-Graph: Coupled tensor-matrix knowledge-graph embedding for COVID-19 drug repurposing
Oct 25, 2020


Knowledge graphs (KGs) are powerful tools that codify relational behaviour between entities in knowledge bases. KGs can simultaneously model many different types of subject-predicate-object and higher-order relations. As such, they offer a flexible modeling framework that has been applied to many areas, including biology and pharmacology -- most recently, in the fight against COVID-19. The flexibility of KG modeling is both a blessing and a challenge from the learning point of view. In this paper we propose a novel coupled tensor-matrix framework for KG embedding. We leverage tensor factorization tools to learn concise representations of entities and relations in knowledge bases and employ these representations to perform drug repurposing for COVID-19. Our proposed framework is principled, elegant, and achieves 100% improvement over the best baseline in the COVID-19 drug repurposing task using a recently developed biological KG.
PHASED: Phase-Aware Submodularity-Based Energy Disaggregation
Oct 01, 2020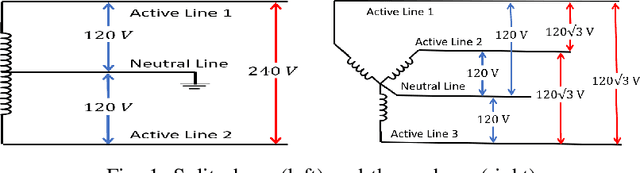
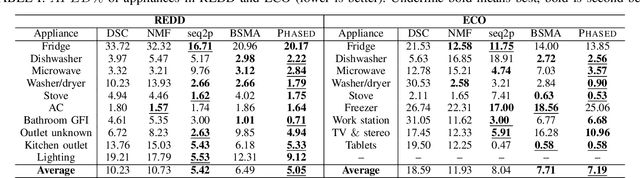
Energy disaggregation is the task of discerning the energy consumption of individual appliances from aggregated measurements, which holds promise for understanding and reducing energy usage. In this paper, we propose PHASED, an optimization approach for energy disaggregation that has two key features: PHASED (i) exploits the structure of power distribution systems to make use of readily available measurements that are neglected by existing methods, and (ii) poses the problem as a minimization of a difference of submodular functions. We leverage this form by applying a discrete optimization variant of the majorization-minimization algorithm to iteratively minimize a sequence of global upper bounds of the cost function to obtain high-quality approximate solutions. PHASED improves the disaggregation accuracy of state-of-the-art models by up to 61% and achieves better prediction on heavy load appliances.
Nonparametric Multivariate Density Estimation: A Low-Rank Characteristic Function Approach
Aug 27, 2020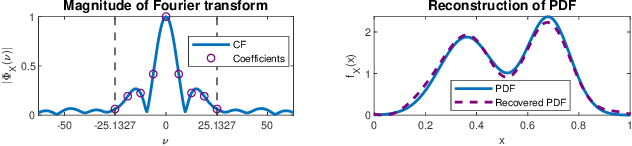


Effective non-parametric density estimation is a key challenge in high-dimensional multivariate data analysis. In this paper,we propose a novel approach that builds upon tensor factorization tools. Any multivariate density can be represented by its characteristic function, via the Fourier transform. If the sought density is compactly supported, then its characteristic function can be approximated, within controllable error, by a finite tensor of leading Fourier coefficients, whose size de-pends on the smoothness of the underlying density. This tensor can be naturally estimated from observed realizations of the random vector of interest, via sample averaging. In order to circumvent the curse of dimensionality, we introduce a low-rank model of this characteristic tensor, which significantly improves the density estimate especially for high-dimensional data and/or in the sample-starved regime. By virtue of uniqueness of low-rank tensor decomposition, under certain conditions, our method enables learning the true data-generating distribution. We demonstrate the very promising performance of the proposed method using several measured datasets.
Mining Large Quasi-cliques with Quality Guarantees from Vertex Neighborhoods
Aug 18, 2020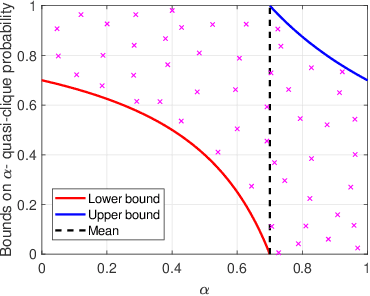
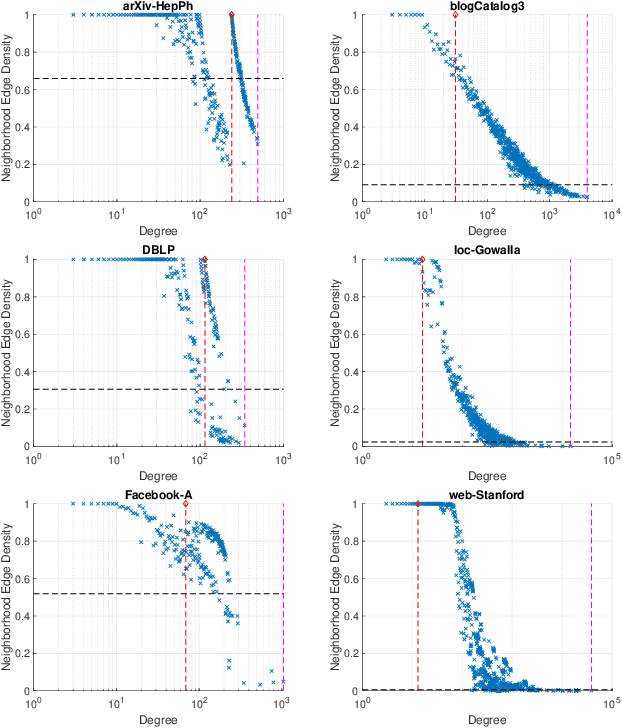
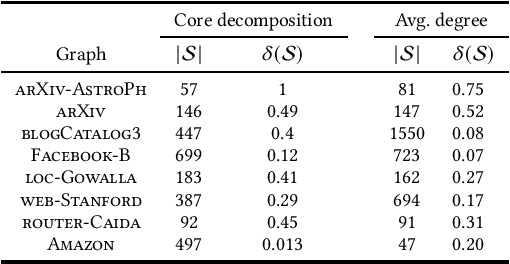
Mining dense subgraphs is an important primitive across a spectrum of graph-mining tasks. In this work, we formally establish that two recurring characteristics of real-world graphs, namely heavy-tailed degree distributions and large clustering coefficients, imply the existence of substantially large vertex neighborhoods with high edge-density. This observation suggests a very simple approach for extracting large quasi-cliques: simply scan the vertex neighborhoods, compute the clustering coefficient of each vertex, and output the best such subgraph. The implementation of such a method requires counting the triangles in a graph, which is a well-studied problem in graph mining. When empirically tested across a number of real-world graphs, this approach reveals a surprise: vertex neighborhoods include maximal cliques of non-trivial sizes, and the density of the best neighborhood often compares favorably to subgraphs produced by dedicated algorithms for maximizing subgraph density. For graphs with small clustering coefficients, we demonstrate that small vertex neighborhoods can be refined using a local-search method to ``grow'' larger cliques and near-cliques. Our results indicate that contrary to worst-case theoretical results, mining cliques and quasi-cliques of non-trivial sizes from real-world graphs is often not a difficult problem, and provides motivation for further work geared towards a better explanation of these empirical successes.
GRATE: Granular Recovery of Aggregated Tensor Data by Example
Apr 05, 2020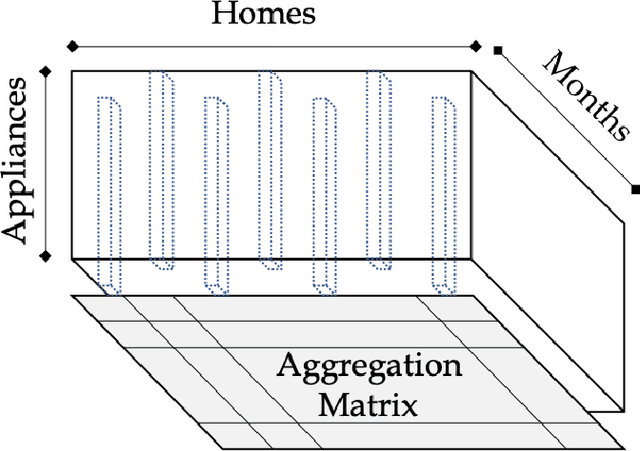
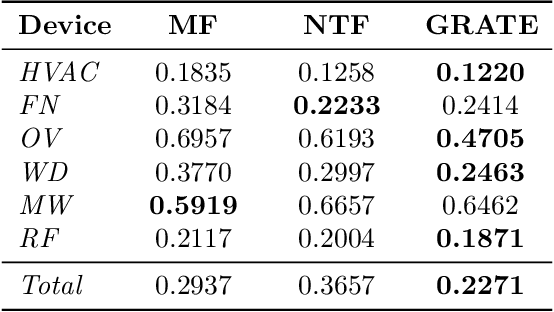
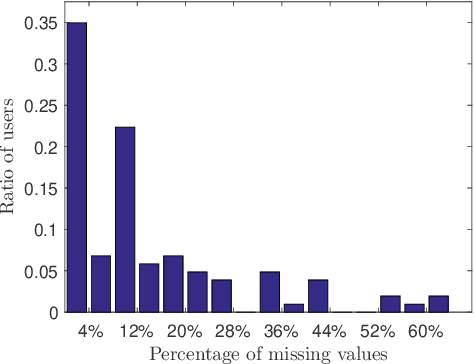
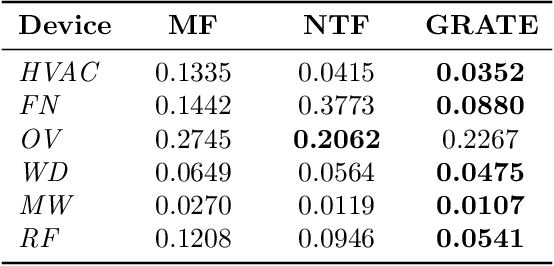
In this paper, we address the challenge of recovering an accurate breakdown of aggregated tensor data using disaggregation examples. This problem is motivated by several applications. For example, given the breakdown of energy consumption at some homes, how can we disaggregate the total energy consumed during the same period at other homes? In order to address this challenge, we propose GRATE, a principled method that turns the ill-posed task at hand into a constrained tensor factorization problem. Then, this optimization problem is tackled using an alternating least-squares algorithm. GRATE has the ability to handle exact aggregated data as well as inexact aggregation where some unobserved quantities contribute to the aggregated data. Special emphasis is given to the energy disaggregation problem where the goal is to provide energy breakdown for consumers from their monthly aggregated consumption. Experiments on two real datasets show the efficacy of GRATE in recovering more accurate disaggregation than state-of-the-art energy disaggregation methods.
Generalized Canonical Correlation Analysis: A Subspace Intersection Approach
Mar 25, 2020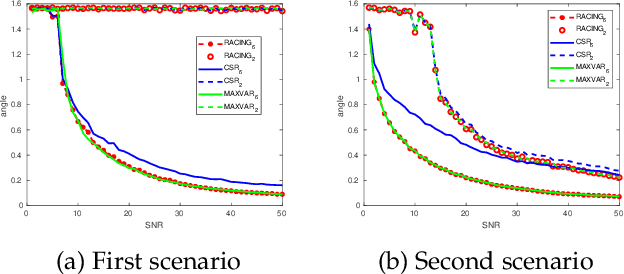
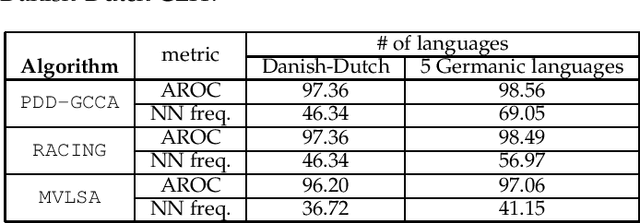
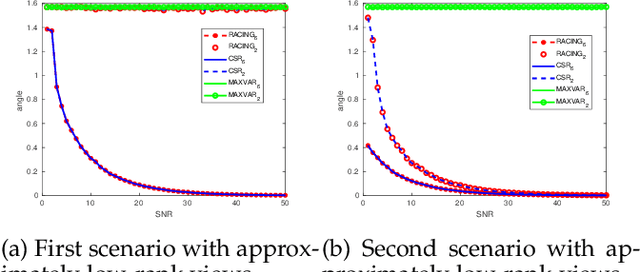
Generalized Canonical Correlation Analysis (GCCA) is an important tool that finds numerous applications in data mining, machine learning, and artificial intelligence. It aims at finding `common' random variables that are strongly correlated across multiple feature representations (views) of the same set of entities. CCA and to a lesser extent GCCA have been studied from the statistical and algorithmic points of view, but not as much from the standpoint of linear algebra. This paper offers a fresh algebraic perspective of GCCA based on a (bi-)linear generative model that naturally captures its essence. It is shown that from a linear algebra point of view, GCCA is tantamount to subspace intersection; and conditions under which the common subspace of the different views is identifiable are provided. A novel GCCA algorithm is proposed based on subspace intersection, which scales up to handle large GCCA tasks. Synthetic as well as real data experiments are provided to showcase the effectiveness of the proposed approach.
PREMA: Principled Tensor Data Recovery from Multiple Aggregated Views
Oct 26, 2019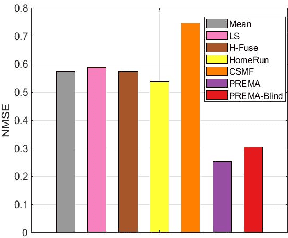

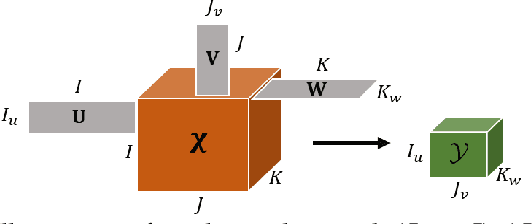
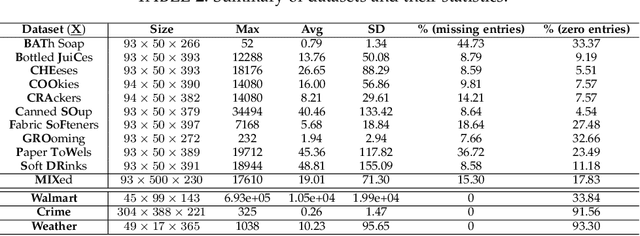
Multidimensional data have become ubiquitous and are frequently involved in situations where the information is aggregated over multiple data atoms. The aggregation can be over time or other features, such as geographical location or group affiliation. We often have access to multiple aggregated views of the same data, each aggregated in one or more dimensions, especially when data are collected or measured by different agencies. However, data mining and machine learning models require detailed data for personalized analysis and prediction. Thus, data disaggregation algorithms are becoming increasingly important in various domains. The goal of this paper is to reconstruct finer-scale data from multiple coarse views, aggregated over different (subsets of) dimensions. The proposed method, called PREMA, leverages low-rank tensor factorization tools to provide recovery guarantees under certain conditions. PREMA is flexible in the sense that it can perform disaggregation on data that have missing entries, i.e., partially observed. The proposed method considers challenging scenarios: i) the available views of the data are aggregated in two dimensions, i.e., double aggregation, and ii) the aggregation patterns are unknown. Experiments on real data from different domains, i.e., sales data from retail companies, crime counts, and weather observations, are presented to showcase the effectiveness of PREMA.
REP: Predicting the Time-Course of Drug Sensitivity
Jul 27, 2019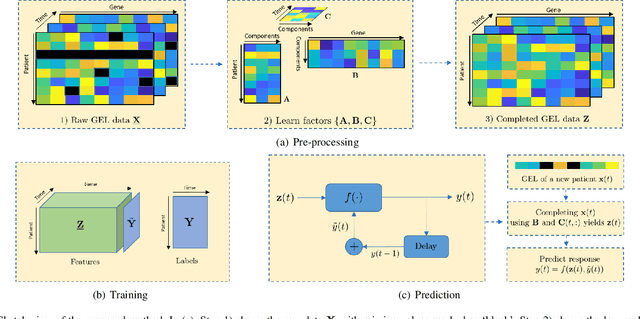
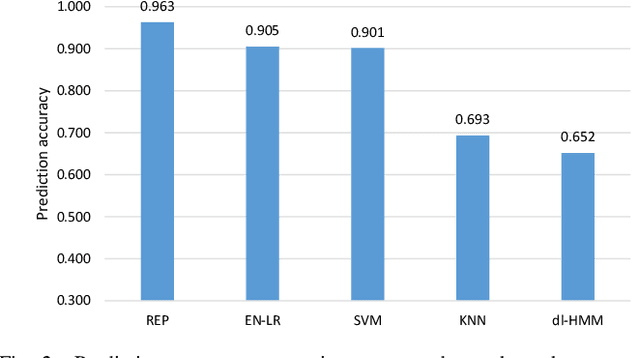
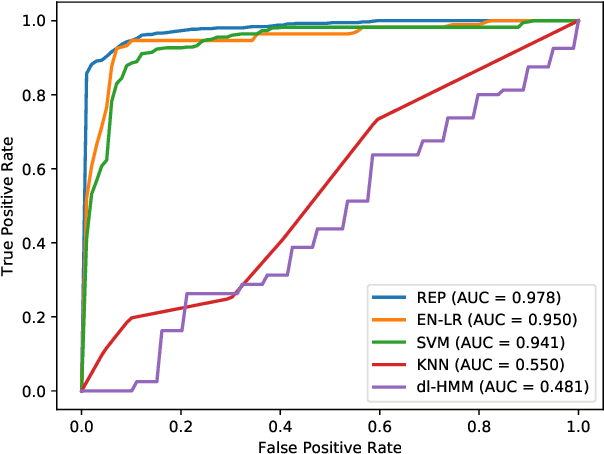
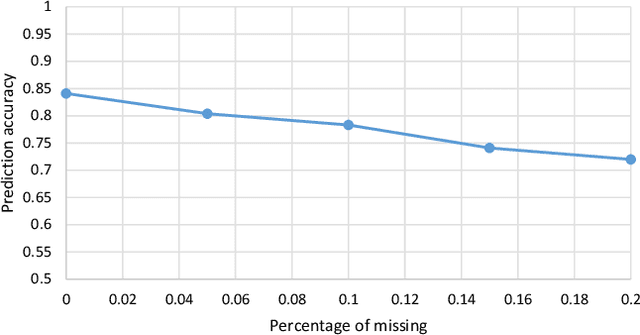
The biological processes involved in a drug's mechanisms of action are oftentimes dynamic, complex and difficult to discern. Time-course gene expression data is a rich source of information that can be used to unravel these complex processes, identify biomarkers of drug sensitivity and predict the response to a drug. However, the majority of previous work has not fully utilized this temporal dimension. In these studies, the gene expression data is either considered at one time-point (before the administration of the drug) or two timepoints (before and after the administration of the drug). This is clearly inadequate in modeling dynamic gene-drug interactions, especially for applications such as long-term drug therapy. In this work, we present a novel REcursive Prediction (REP) framework for drug response prediction by taking advantage of time-course gene expression data. Our goal is to predict drug response values at every stage of a long-term treatment, given the expression levels of genes collected in the previous time-points. To this end, REP employs a built-in recursive structure that exploits the intrinsic time-course nature of the data and integrates past values of drug responses for subsequent predictions. It also incorporates tensor completion that can not only alleviate the impact of noise and missing data, but also predict unseen gene expression levels (GELs). These advantages enable REP to estimate drug response at any stage of a given treatment from some GELs measured in the beginning of the treatment. Extensive experiments on a dataset corresponding to 53 multiple sclerosis patients treated with interferon are included to showcase the effectiveness of REP.