 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFormer-driven Encoding Network for Robust Medical Semantic Segmentation
Jan 01, 2026Semantic segmentation is crucial for medical image analysis, enabling precise disease diagnosis and treatment planning. However, many advanced models employ complex architectures, limiting their use in resource-constrained clinical settings. This paper proposes MFEnNet, an efficient medical image segmentation framework that incorporates MetaFormer in the encoding phase of the U-Net backbone. MetaFormer, an architectural abstraction of vision transformers, provides a versatile alternative to convolutional neural networks by transforming tokenized image patches into sequences for global context modeling. To mitigate the substantial computational cost associated with self-attention, the proposed framework replaces conventional transformer modules with pooling transformer blocks, thereby achieving effective global feature aggregation at reduced complexity. In addition, Swish activation is used to achieve smoother gradients and faster convergence, while spatial pyramid pooling is incorporated at the bottleneck to improve multi-scale feature extraction. Comprehensive experiments on different medical segmentation benchmarks demonstrate that the proposed MFEnNet approach attains competitive accuracy while significantly lowering computational cost compared to state-of-the-art models. The source code for this work is available at https://github.com/tranleanh/mfennet.
Sentiment Analysis Based on Deep Learning: A Comparative Study
Jun 05, 2020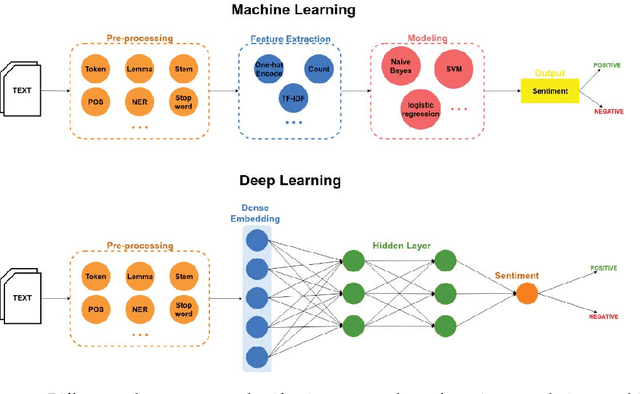
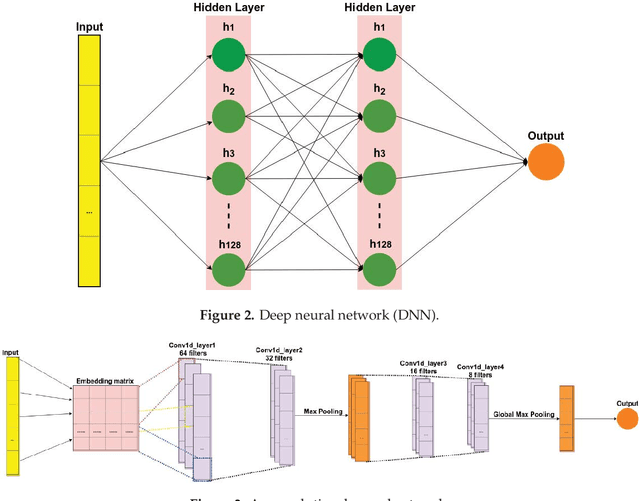
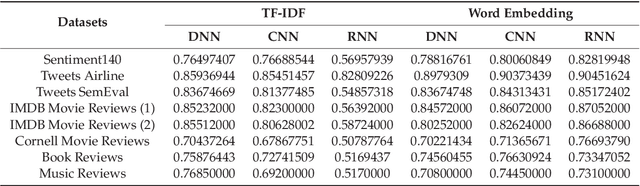
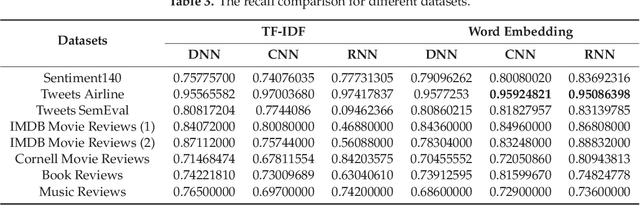
The study of public opinion can provide us with valuable information. The analysis of sentiment on social networks, such as Twitter or Facebook, has become a powerful means of learning about the users' opinions and has a wide range of applications. However, the efficiency and accuracy of sentiment analysis is being hindered by the challenges encountered in natural language processing (NLP). In recent years, it has been demonstrated that deep learning models are a promising solution to the challenges of NLP. This paper reviews the latest studies that have employed deep learning to solve sentiment analysis problems, such as sentiment polarity. Models using term frequency-inverse document frequency (TF-IDF) and word embedding have been applied to a series of datasets. Finally, a comparative study has been conducted on the experimental results obtained for the different models and input features