 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Reasoning Gap in Vietnamese with Small Language Models via Test-Time Scaling
Apr 20, 2026The democratization of ubiquitous AI hinges on deploying sophisticated reasoning capabilities on resource-constrained devices. However, Small Language Models (SLMs) often face a "reasoning gap", particularly in non-English languages like Vietnamese, where they struggle to maintain coherent chains of thought. This paper investigates Test-Time Scaling strategies for the Qwen3-1.7B architecture within the context of Vietnamese Elementary Mathematics. We introduce Vi-S1K, a high-fidelity reasoning dataset localized via a Gemini 2.5 Flash-Lite powered pipeline, and Vi-Elementary-Bench, a dual-resource benchmark for rigorous evaluation. Using an LLM-as-a-Judge protocol, we reveal that the base model possesses robust latent knowledge (Accuracy: 4.05/5.00) but suffers from a severe "formatting gap" in communication. Supervised Fine-Tuning (SFT) acts as a critical "reasoning unlocker", yielding a 77% improvement in Explanation Quality and bridging the gap between raw calculation and pedagogical coherence. Furthermore, our analysis of prompting strategies uncovers a significant trade-off: structured frameworks like ReAct impose a "cognitive tax" on the 1.7B parameter capacity, degrading performance relative to pure Chain-of-Thought (CoT) combined with Self-Consistency. These findings establish a deployment hierarchy for SLMs, demonstrating that SFT combined with simplified test-time scaling is superior to complex agentic workflows for edge-based reasoning.
Auto-Prompting with Retrieval Guidance for Frame Detection in Logistics
Dec 22, 2025Prompt engineering plays a critical role in adapting large language models (LLMs) to complex reasoning and labeling tasks without the need for extensive fine-tuning. In this paper, we propose a novel prompt optimization pipeline for frame detection in logistics texts, combining retrieval-augmented generation (RAG), few-shot prompting, chain-of-thought (CoT) reasoning, and automatic CoT synthesis (Auto-CoT) to generate highly effective task-specific prompts. Central to our approach is an LLM-based prompt optimizer agent that iteratively refines the prompts using retrieved examples, performance feedback, and internal self-evaluation. Our framework is evaluated on a real-world logistics text annotation task, where reasoning accuracy and labeling efficiency are critical. Experimental results show that the optimized prompts - particularly those enhanced via Auto-CoT and RAG - improve real-world inference accuracy by up to 15% compared to baseline zero-shot or static prompts. The system demonstrates consistent improvements across multiple LLMs, including GPT-4o, Qwen 2.5 (72B), and LLaMA 3.1 (70B), validating its generalizability and practical value. These findings suggest that structured prompt optimization is a viable alternative to full fine-tuning, offering scalable solutions for deploying LLMs in domain-specific NLP applications such as logistics.
ViNMT: Neural Machine Translation Toolkit
Jan 08, 2022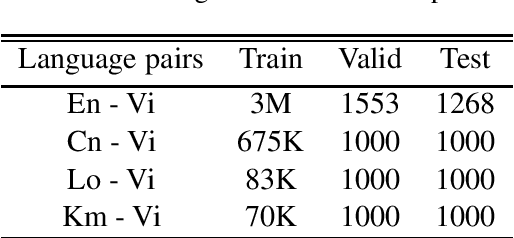
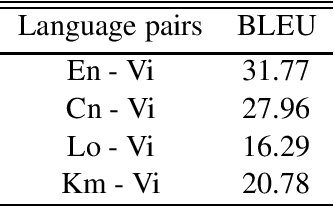
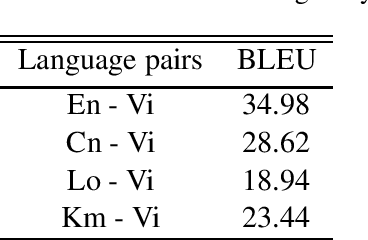
We present an open-source toolkit for neural machine translation (NMT). The new toolkit is mainly based on vaulted Transformer (Vaswani et al., 2017) along with many other improvements detailed below, in order to create a self-contained, simple to use, consistent and comprehensive framework for Machine Translation tasks of various domains. It is tooled to support both bilingual and multilingual translation tasks, starting from building the model from respective corpora, to inferring new predictions or packaging the model to serving-capable JIT format.