 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Aware Mispronunciation Detection and Diagnosis Using Language-Specific Statistical Graphs
Jun 04, 2026Mispronunciation Detection and Diagnosis (MDD) has gained increasing importance in computer-assisted language learning and speech technology in recent years. In this paper, we propose a method for constructing statistical graphs that enable models to learn phoneme confusion patterns represented as directed graphs. Furthermore, we introduce a language-specific strategy to capture systematic pronunciation differences across various native language (L1) backgrounds. The effectiveness of our approach is demonstrated through extensive experiments on the L2-ARCTIC benchmark, where it achieves an F1-score of 59.52%, outperforming several competitive baselines.
VoxVietnam: a Large-Scale Multi-Genre Dataset for Vietnamese Speaker Recognition
Dec 31, 2024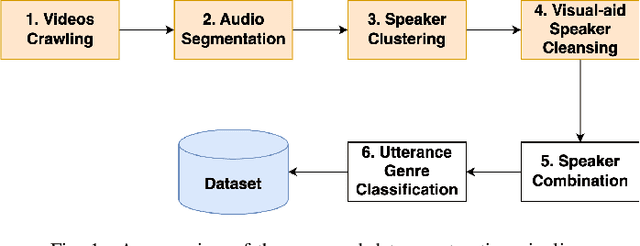
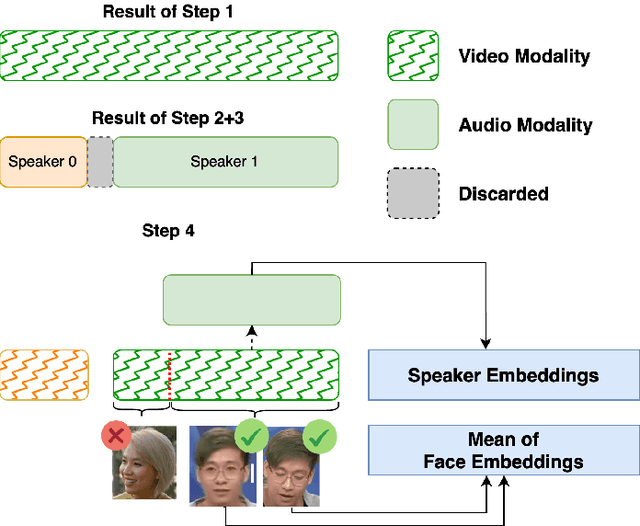
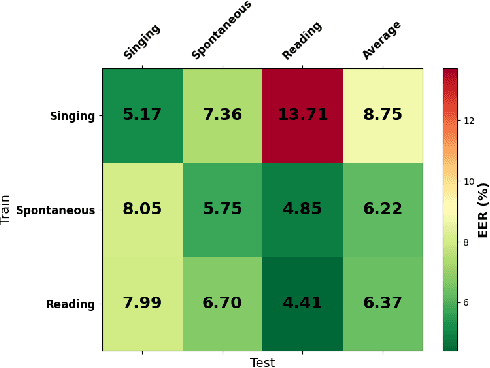
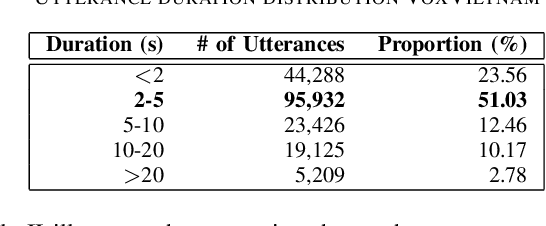
Recent research in speaker recognition aims to address vulnerabilities due to variations between enrolment and test utterances, particularly in the multi-genre phenomenon where the utterances are in different speech genres. Previous resources for Vietnamese speaker recognition are either limited in size or do not focus on genre diversity, leaving studies in multi-genre effects unexplored. This paper introduces VoxVietnam, the first multi-genre dataset for Vietnamese speaker recognition with over 187,000 utterances from 1,406 speakers and an automated pipeline to construct a dataset on a large scale from public sources. Our experiments show the challenges posed by the multi-genre phenomenon to models trained on a single-genre dataset, and demonstrate a significant increase in performance upon incorporating the VoxVietnam into the training process. Our experiments are conducted to study the challenges of the multi-genre phenomenon in speaker recognition and the performance gain when the proposed dataset is used for multi-genre training.