 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Model Image Annotation Platform with Active Learning
Aug 06, 2020
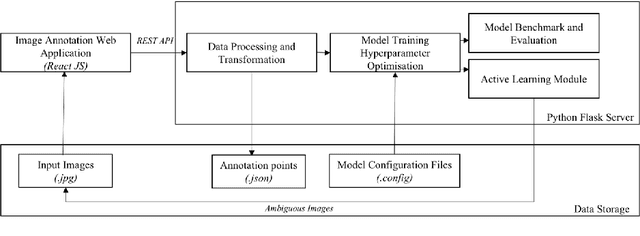
We have seen significant leapfrog advancement in machine learning in recent decades. The central idea of machine learnability lies on constructing learning algorithms that learn from good data. The availability of more data being made publicly available also accelerates the growth of AI in recent years. In the domain of computer vision, the quality of image data arises from the accuracy of image annotation. Labeling large volume of image data is a daunting and tedious task. This work presents an End-to-End pipeline tool for object annotation and recognition aims at enabling quick image labeling. We have developed a modular image annotation platform which seamlessly incorporates assisted image annotation (annotation assistance), active learning and model training and evaluation. Our approach provides a number of advantages over current image annotation tools. Firstly, the annotation assistance utilizes reference hierarchy and reference images to locate the objects in the images, thus reducing the need for annotating the whole object. Secondly, images can be annotated using polygon points allowing for objects of any shape to be annotated. Thirdly, it is also interoperable across several image models, and the tool provides an interface for object model training and evaluation across a series of pre-trained models. We have tested the model and embeds several benchmarking deep learning models. The highest accuracy achieved is 74%.
Deep Learning based Topic Analysis on Financial Emerging Event Tweets
Aug 03, 2020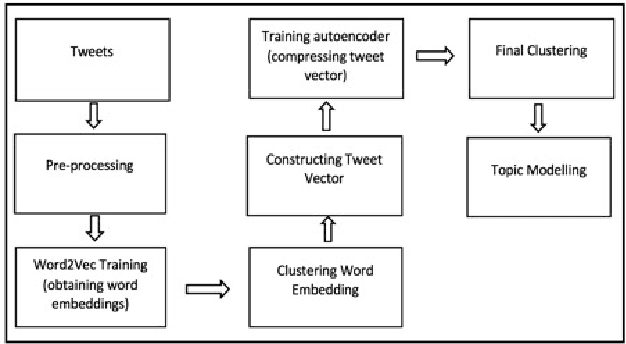
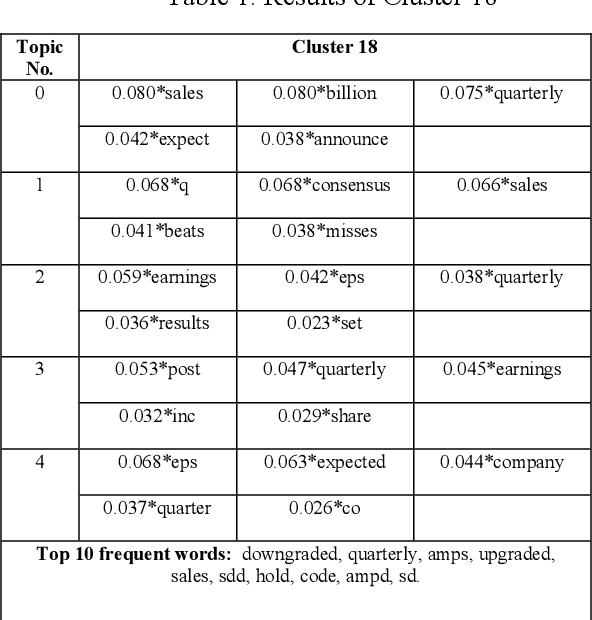
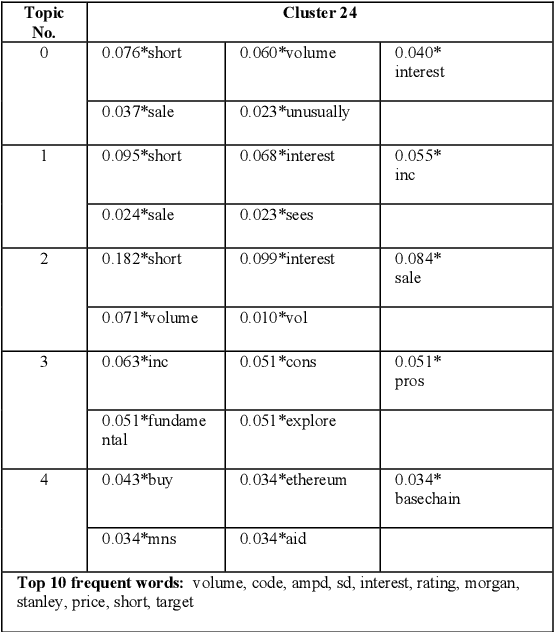
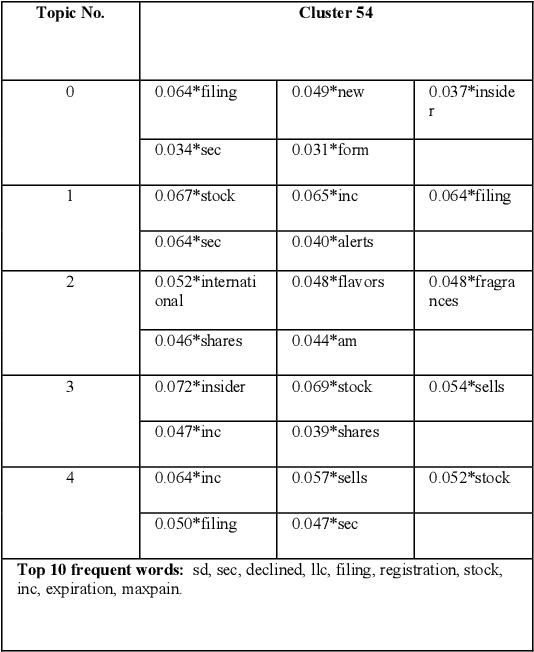
Financial analyses of stock markets rely heavily on quantitative approaches in an attempt to predict subsequent or market movements based on historical prices and other measurable metrics. These quantitative analyses might have missed out on un-quantifiable aspects like sentiment and speculation that also impact the market. Analyzing vast amounts of qualitative text data to understand public opinion on social media platform is one approach to address this gap. This work carried out topic analysis on 28264 financial tweets [1] via clustering to discover emerging events in the stock market. Three main topics were discovered to be discussed frequently within the period. First, the financial ratio EPS is a measure that has been discussed frequently by investors. Secondly, short selling of shares were discussed heavily, it was often mentioned together with Morgan Stanley. Thirdly, oil and energy sectors were often discussed together with policy. These tweets were semantically clustered by a method consisting of word2vec algorithm to obtain word embeddings that map words to vectors. Semantic word clusters were then formed. Each tweet was then vectorized using the Term Frequency-Inverse Document Frequency (TF-IDF) values of the words it consisted of and based on which clusters its words were in. Tweet vectors were then converted to compressed representations by training a deep-autoencoder. K-means clusters were then formed. This method reduces dimensionality and produces dense vectors, in contrast to the usual Vector Space Model. Topic modelling with Latent Dirichlet Allocation (LDA) and top frequent words were used to analyze clusters and reveal emerging events.